






Mysql del 数据去重
数据表
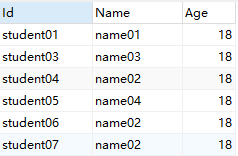
重复数据只保留第一条,去掉Name列已重复的数据(表Id字段为主键)
思路
1、查询出重复的数据
SELECT
*
FROM
student
WHERE
`Name` IN (
SELECT
`Name`
FROM
student
GROUP BY
`Name`
HAVING
count( 1 ) > 1
)
执行结果
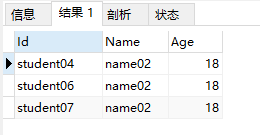
对于count(1)的使用可以去了解下:MySQL查询count(*)、count(1)、count(field)的区别收集
链接地址:
https://www.cnblogs.com/EasonJim/p/7709650.html
2、分组去重
分组查询默认显示的是检索的第一条记录(如果你Id有序,像这样student01,student02…这种,默认是Id最小记录作为查询显示的数据)
SELECT * FROM student GROUP BY `Name` HAVING count(1) > 1
执行结果
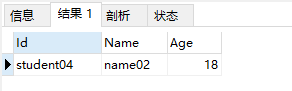
我这里是三条记录重复,数据Id分别是student04,student06,student07,我们保留Id最小的那一条
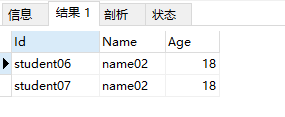
组合一下sql,把Id是student04那条数据保留
SELECT
*
FROM
student
WHERE
`Name` IN ( SELECT `Name` FROM student GROUP BY `Name` HAVING count( 1 ) > 1 )
AND `Id` NOT IN (
SELECT
`Id`
FROM
student
GROUP BY
`Name`
HAVING
count( 1 ) > 1)
执行结果
3、组合del语句去重
DELETE
FROM
student
WHERE
`Id` IN (
SELECT
`Id`
FROM
(
SELECT
`Id`
FROM
student
WHERE
`Name` IN ( SELECT `Name` FROM student GROUP BY `Name` HAVING count( 1 ) > 1 )
AND `Id` NOT IN ( SELECT `Id` FROM student GROUP BY `Name` HAVING count( 1 ) > 1 )) AS stu)
执行结果

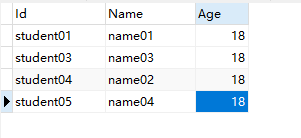
再查看一下表数据,可以看到之前Name字段重复的Id为student06,student07数据已经被移除了
参考:
https://blog.csdn.net/weixin_30867015/article/details/98818003?utm_medium=distribute.pc_relevant.none-task-blog-baidujs-2















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









