






本文创新点:
设计了一种基于两种见解来检测来自多个框架的表示攻击的新方法:
1)详细的鉴别线索(例如,空间梯度大小)可以通过叠加的普通卷积被丢弃;2)三维运动人脸的动力学为检测假人脸提供了重要的线索

目前尚未被解决的问题:
1.如何将局部细粒度信息聚合到卷积网络中的面部反欺骗任务还没有被探索
2.多帧可以更充分地探索脸和欺骗脸之间的虚拟深度区分。

解决方法:
我们提出了一种新的具有剩余空间梯度块(RSGB)和时空传播模块(STPM)的深度监督时空网络。

本文主要贡献:
1.提出了一种新的深度监督架构,通过残余空间梯度块(RSGB)捕获鉴别细节,并从单目帧序列中有效地对时空传播模块(STPM)的时空信息进行编码。
2.开发了一个对比深度损失来学习深度监督垫的面点的形态。
3.我们收集了一个双模态数据集,以验证实际深度比生成的深度更适合单眼PAD。这表明,收集相应的深度图像到RGB图像会对单眼PAD的进展带来好处。
4.通过我们的方法在广泛使用的人脸反欺骗基准测试上演示了我们的最先进的性能。
网络解读
1.Residual Spatial Gradient Block (RSGB)
细粒度的空间细节对于区分真实的和攻击性的表示至关重要。如图1所示,活体之间的梯度幅度响应(图1(a))和欺骗(图1(b))人脸是完全不同的,这给了一个洞察力来设计一个剩余的空间梯度块(RSGB)来捕捉这种有区别的线索

2. Spatio-Temporal Propagation Module (STPM)
活脸和欺骗脸之间深度的虚拟区分可以通过多个框架进行充分的探索。因此,我们设计了STPM,通过短期时空块(STSTB)和ConvGRU提取多帧时空特征进行深度估计。
STSTB
STSTB通过融合五种特征提取广义的短期时空信息:当前的压缩特征Fl(t)、当前的空间梯度特征FlS(t)、未来的空间梯度特征fls(t+4t)、时间梯度特征FlT(t)和之前级别的STSTBl−1(t)的STSTB特征。融合的特征可以以一种可学习/自适应的方式提供加权的时空信息。在本文中,空间和时间梯度实现了基于索贝尔的深度卷积(类似于等式时间特征的1)和元素减法。请注意,1x1卷积可以更有效地压缩信道号。
ConvGRU
由于来自STSTB的两个连续帧之间的短期信息的表示能力有限,因此使用递归神经网络来捕获长期的时空上下文是很自然的。然而,经典的LSTM和GRU[13]忽略了隐藏单元中的空间信息。考虑到隐藏层中的空间邻居关系,我们用ConvGRU来传播长距离的时空信息。

Depth Map Refinement

3.损失函数(Loss Function)
对比深度损失(Contrastive Detph Loss,CDL)
EDL
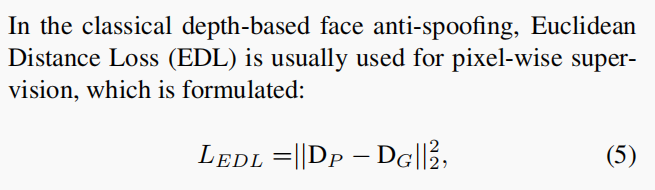
DP和DG分别为预测深度和地面真相深度。EDL基于像素对预测深度进行监督,忽略相邻像素之间的深度差。直观地说,EDL只是帮助网络学习对象到相机之间的绝对距离。然而,监督不同物体的距离关系对于深度学习也很重要。
CDL
因此,我们提出了对比深度损失(CDL)来提供额外强大的监督,从而提高了基于深度的人脸反欺骗模型的通用性


总损失计算:

DMAD数据集
该实验收集了一个新的数据集
实验
1 Depth Generation(深度生成)
借用PRNet的方法
2.Training Strategy(训练策略)
该方法采用两阶段策略训练:第一阶段:我们通过深度损失LEDL和LCDL用级联RSGB训练主干,以学习预测粗深度图的基本表示。第二阶段:我们确定主干的参数,并根据整体损失来训练STPM部分,以细化深度图。我们的网络由Nf帧馈电,它们以三帧的间隔进行采样。这个采样间隔使采样帧在有限的GPU内存中保持足够的时间信息。
3. Testing Strategy(测试策略)

4.超参数设置
训练中,单帧部分的学习速率为1e-4,多帧部分的学习速率为1e-2。单帧部分批量为48,多帧部分批量为2,Nf为5,优化器用 Adadelta optimizer;
测试中ρ为0.95,α=0.6和β=0.8,delta为1e-8
实验结果



部分实验结果此处不再一一列出

OULU-NPU协议1上的测试视频的特征分布如图9所示,右图像(w/RSGB)比左图像(无RSGB)呈现出更多的聚集行为,这证明了我们提出的RSGB在区分真和欺骗脸方面具有出色的识别能力。
结论
本文提出了一种新的人脸反欺骗方法,它利用细粒度的时空信息进行人脸深度估计。在我们的方法中,利用剩余空间梯度块(RSGB)检测更多的鉴别细节,而时空传播模块(STPM)编码时空信息。设计了一种额外的对比深度损失(CDL)来提高深度监督PAD的普遍性。我们还研究了实际深度图在人脸反欺骗中的有效性。大量的实验证明了该方法的优越性。















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









