






排序可以说是很多日志系统的硬指标(如按照时间逆序排序),如果一个大数据系统不能进行排序,基本上是这个系统属于不可用状态,排序算得上是大数据系统的一个“刚需”,无论大数据采用的是hadoop,还是spark,还是impala,hive,总之排序是必不可少的,排序的性能测试也是必不可少的。
有着计算奥运会之称的Sort Benchmark全球排序每年都会举行一次,每年巨头都会在排序上进行巨大的投入,可见排序速度的高低有多么重要!但是对于大多数企业来说,动辄上亿的硬件投入,实在划不来、甚至远远超出了企业的项目预算。相比大数据领域的暴力排序有没有一种更廉价的实现方式?
在这里,我们为大家介绍一种新的廉价排序方法,我们称为blockSort。
500G的数据300亿条数据,只使用4台 16核,32G内存,千兆网卡的虚拟机即可实现 2~15秒的 排序 (可以全表排序,也可以与任意筛选条件筛选后排序)。
一、基本的思想是这样的,如下图所示:
1.将数据按照大小预先划分好,如划分成 大、中、小三个块(block)。
2.如果想找最大的数据,那么只需要在最大的那个块里去找就可以了。
3.这个快还是有层级结构的,如果每个块内的数据量很多,可以到下面的子快内进行继续查找,可以分多个层进行排序。
4.采用这种方法,一个亿万亿级别的数据(如long类型),最坏最坏的极端情况也就进行2048次文件seek就可以筛选到结果。
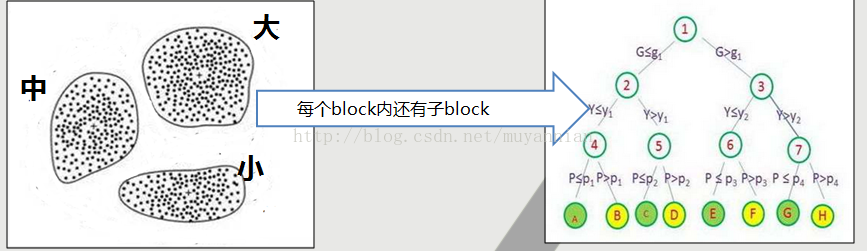
怎么样,原理是不是非常简单,这样数据量即使特别多,那么排序与查找的次数是固定的。
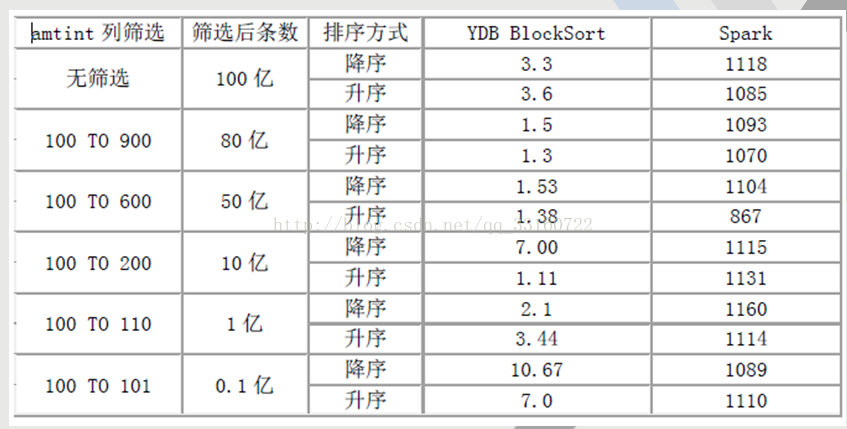
二、这个是我们之前基于spark做的性能测试,供大家参考
在排序上,YDB具有绝对优势,无论是全表,还是基于任意条件组合过滤,基本秒杀Spark任何格式。
测试结果(时间单位为秒)
测试过程视频地址
https://v.qq.com/x/page/q0371wjj8fb.html
https://v.qq.com/x/page/n0371l0ytji.html
感兴趣的读者也可以阅读YDB编程指南 http://url.cn/42R4CG8 。也可以参考该书自己安装延云YDB进行测试。
三、当然除了排序上,我们的其他性能也是远远高于spark,这块大家也可以了解一下
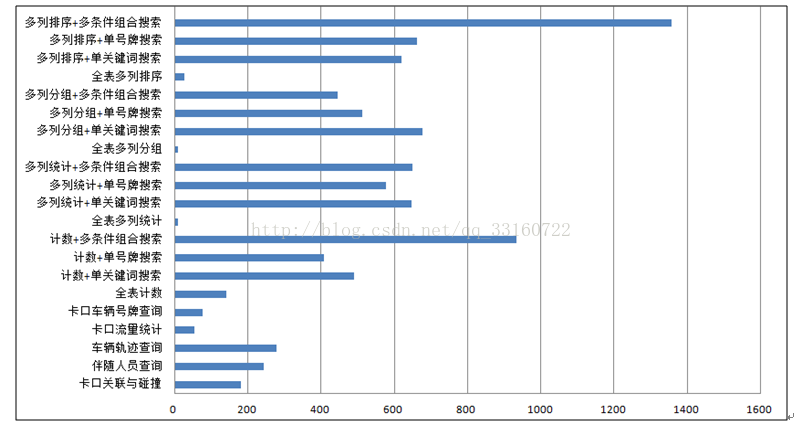
1、与Spark txt在检索上的性能对比测试。
注释:备忘。下图的这块,其实没什么特别的,只不过由于YDB本身索引的特性,不想spark那样暴力,才会导致在扫描上的性能远高于spark,性能高百倍不足为奇。
下图为ydb相对于spark txt提升的倍数
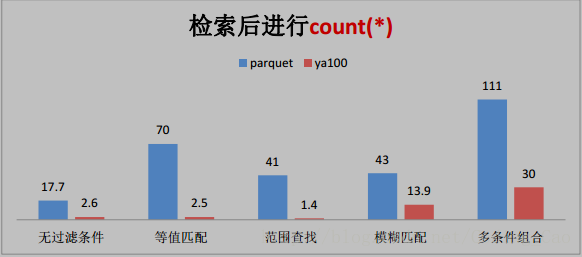
2、这些是与 Parquet 格式对比(单位为秒)
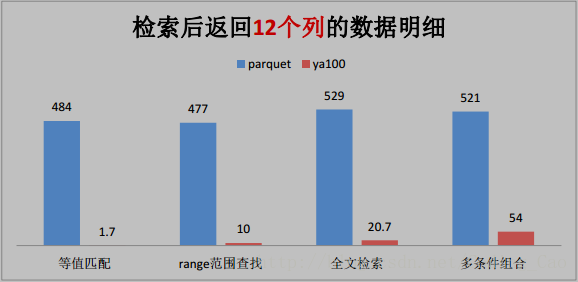
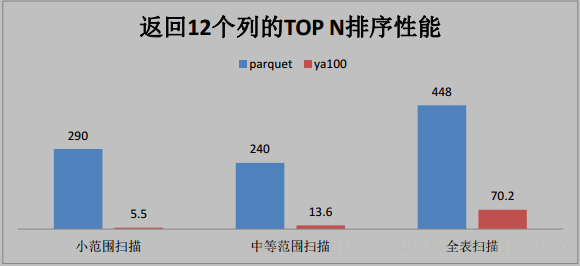
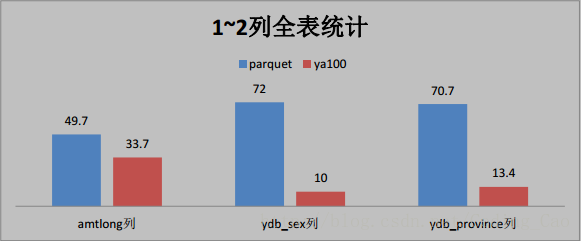
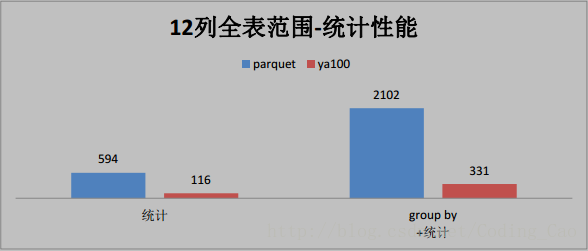
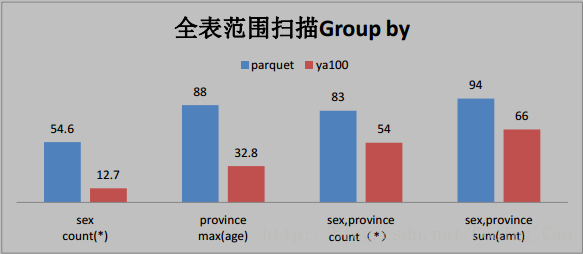
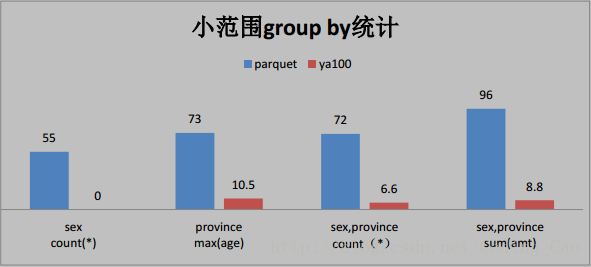
3、与ORACLE性能对比
跟传统数据库的对比,已经没啥意义,Oracle不适合大数据,任意一个大数据工具都远超oracle 性能。
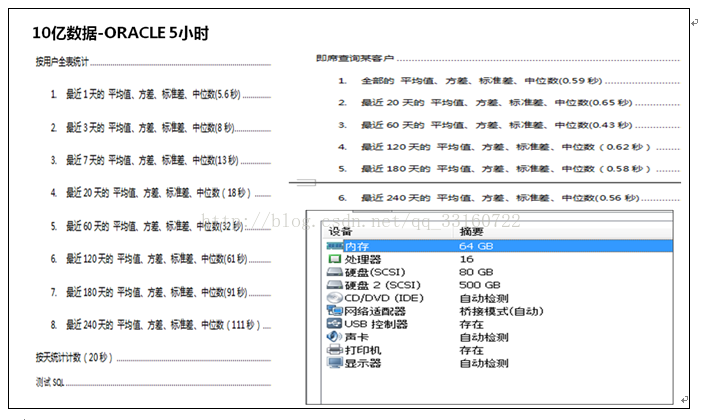 |
4.稽查布控场景性能测试

四、YDB是怎么样让spark加速的?
基于Hadoop分布式架构下的实时的、多维的、交互式的查询、统计、分析引擎,具有万亿数据规模下的秒级性能表现,并具备企业级的稳定可靠表现。
YDB是一个细粒度的索引,精确粒度的索引。数据即时导入,索引即时生成,通过索引高效定位到相关数据。YDB与Spark深度集成,Spark对YDB检索结果集直接分析计算,同样场景让Spark性能加快百倍。
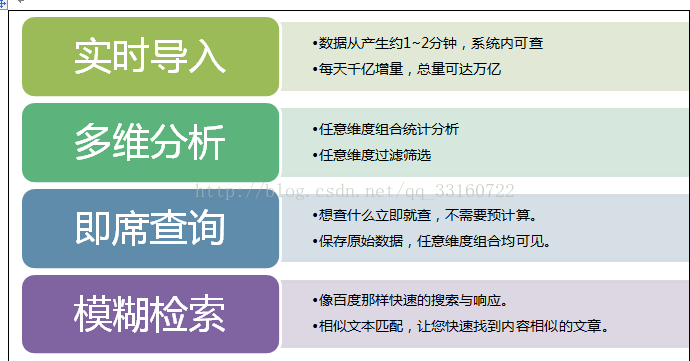
五、哪些用户适合使用YDB?
1.传统关系型数据,已经无法容纳更多的数据,查询效率严重受到影响的用户。
2.目前在使用SOLR、ES做全文检索,觉得solr与ES提供的分析功能太少,无法完成复杂的业务逻辑,或者数据量变多后SOLR与ES变得不稳定,在掉片与均衡中不断恶性循环,不能自动恢复服务,运维人员需经常半夜起来重启集群的情况。
3.基于对海量数据的分析,但是苦于现有的离线计算平台的速度和响应时间无满足业务要求的用户。
4.需要对用户画像行为类数据做多维定向分析的用户。
5.需要对大量的UGC(User Generate Content)数据进行检索的用户。
6.当你需要在大数据集上面进行快速的,交互式的查询时。
7.当你需要进行数据分析,而不只是简单的键值对存储时。
8.当你想要分析实时产生的数据时。
视频地址 (看不清的同学可以进入腾讯视频 高清播放)
https://v.qq.com/x/page/q0371wjj8fb.html
https://v.qq.com/x/page/n0371l0ytji.html
感兴趣的读者也可以阅读YDB编程指南 http://url.cn/42R4CG8 。也可以参考该书自己安装延云YDB进行测试。















 3609
3609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









