







前言
论文:CLongEval: A Chinese Benchmark for Evaluating Long-Context Large Language Models
链接:https://arxiv.org/pdf/2403.03514
Github:https://github.com/zexuanqiu/CLongEval
数据:https://huggingface.co/datasets/zexuanqiu22/CLongEval
总体介绍
CLongEval是港中文提出的一个用于评估长文本上下文大型语言模型(LLMs)的中文基准测试:
- 包含7个不同任务和7267个示例;
- 数据长度在1K至100K的上下文窗口大小
- 除了自动构建的标签外,还有2,000多对人工标注的问题-答案对。
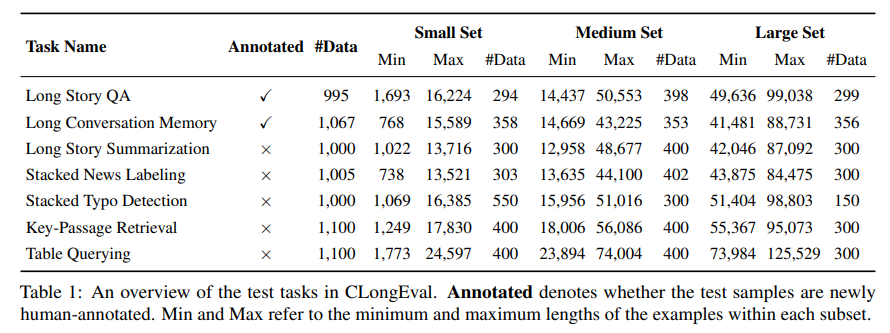
CLongEval 的7个任务每个任务的测试数据都分成了三个不同的子集:小、中、大。
- 小数据集:主要包含长度在1K到16K tokens 之间的测试数据。
- 中数据集:主要包含长度在16K到50K tokens 之间的数据。
- 大数据集:主要包含长度从50K到100K tokens 的数据。
数据情况:
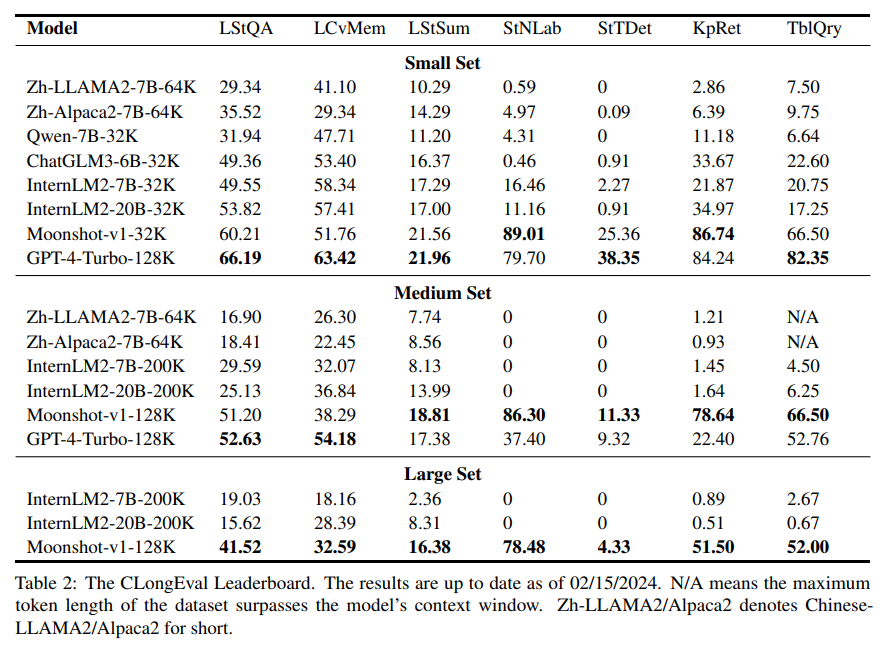
评测结果:
数据详情
任务一:Long Story QA (LStQA) - 长篇故事问答任务
长篇故事问答(LStQA)任务要求大型语言模型(LLMs)基于长篇故事的上下文片段回答相关问题。
模型应该能够识别出相关的片段,并推理出答案。与MultiFieldQA的规范性和客观性不同,我们选择的故事具有叙述性、创造性,并且本质上更长&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









