






原文地址:https://huggingface.co/blog/zh/smolervlm
一、核心发布概要
- 新成员亮相:推出256M(2.56亿参数)与500M(5亿参数)视觉语言模型
- 关键定位:目前全球最小VLM(256M)+ 轻量高性能折衷方案(500M)
- 模型类型:包含基础版与指令微调版(各2个checkpoint)
- 兼容性:支持Transformers、MLX、ONNX框架,提供WebGPU演示
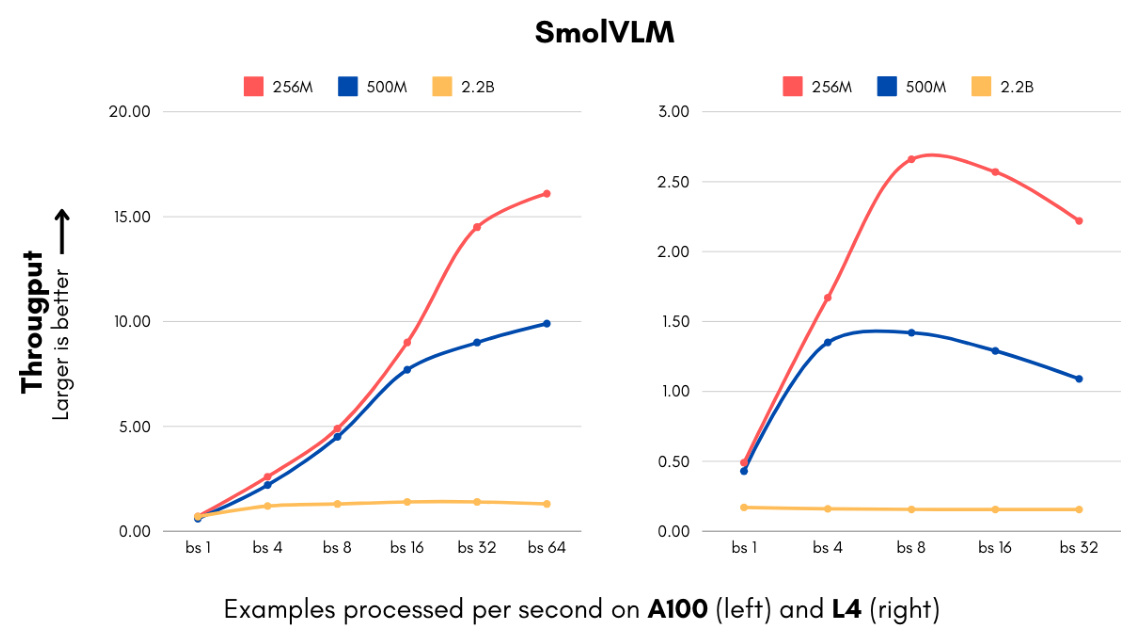
二、技术突破点
1. 视觉编码器革新
| 编码器类型 | 参数量 | 优势 |
|---|---|---|
| SigLIP base patch-16/512 | 93M | 高分辨率支持(384x384),性能接近大编码器 |
| SigLIP 400M SO(旧版) | 400M | 性能略优但体积庞大 |
▶️ 选择逻辑:小编码器在分辨率提升(+33%)与参数量缩减(-77%)间取得平衡
2. 数据混合优化
- 核心数据集:The Cauldron、Docmatix、新增MathWriting
- 配比调整:
- 文档理解:41%(原35%)
- 图像描述:14%(原10%)
- 视觉推理/图表理解:30%
- 指令跟随:15%
3. Token化改进
- 像素编码:4096像素/Token(原1820)
- 分隔符优化:子图像标记(如<row_1_col_1>)从7 Token压缩为1
- 效果:训练稳定性↑15%,推理质量显著提升
三、性能表现对比
| 评测指标 | 256M | 500M | 2.2B | Idefics80B |
|---|---|---|---|---|
| OCRBench文字识别 | 52.6% | 61.0% | 65.5% | 28.9% |
| DocVQA文档推理 | 58.3% | 70.5% | 79.7% | 16.1% |
| MathVista数学推理 | 35.9% | 40.1% | 43.9% | 25.0% |
| MMMU大学级推理 | 28.3% | 33.7% | 38.3% | 42.3% |
▶️ 关键观察:500M模型在多数任务达到2.2B 80%+性能,体积仅1/4
四、应用场景示例
-
文档问答:PDF/扫描件内容解析
# Transformers调用示例 from transformers import AutoProcessor, AutoModelForVision2Seq model = AutoModelForVision2Seq.from_pretrained("HuggingFaceTB/SmolVLM-500M-Instruct") -
图像描述:生成短视频/图片的文本说明
# MLX运行指令 python3 -m mlx_vlm.generate --model HuggingfaceTB/SmolVLM-500M-Instruct -
多模态检索:ColSmolVLM实现高速数据库检索
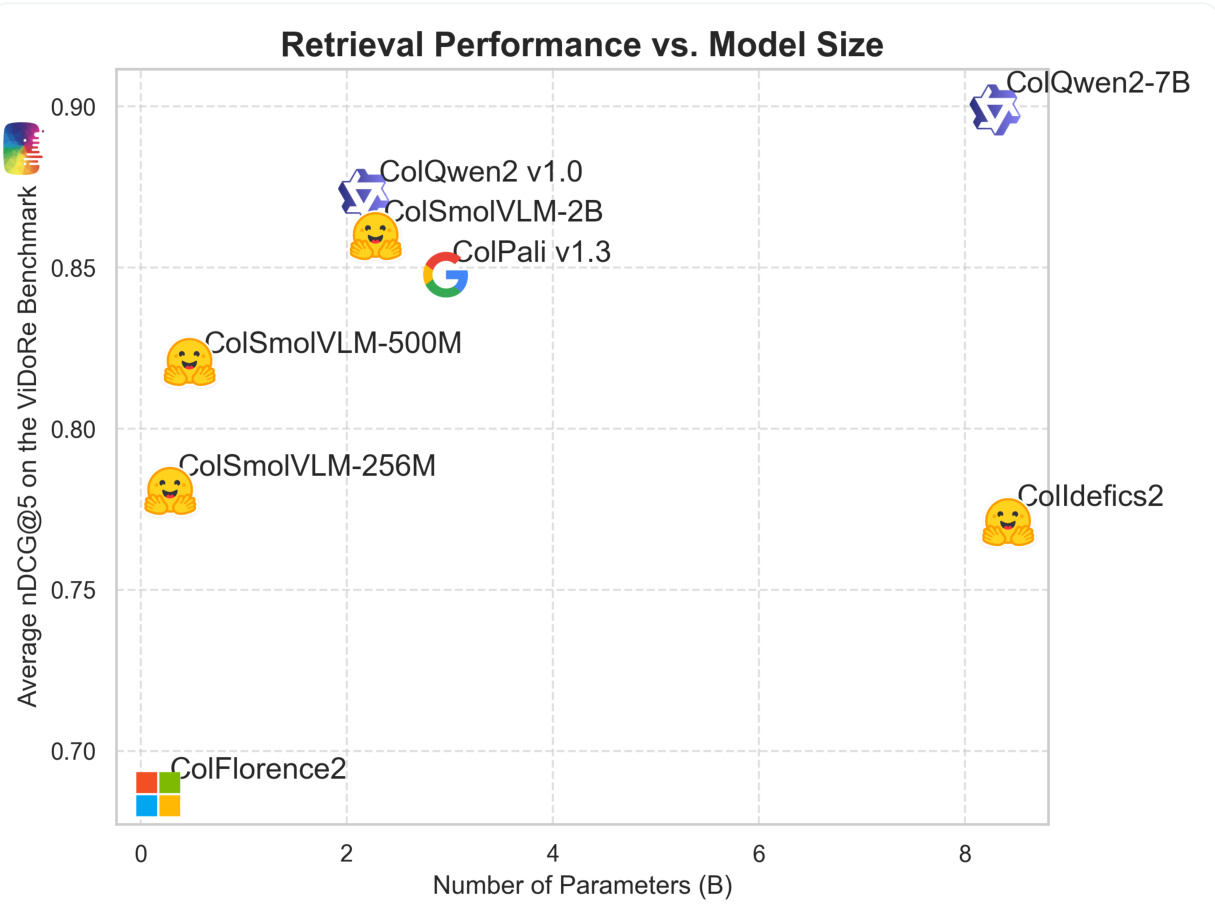
五、部署优势
| 设备类型 | 256M适用场景 | 500M适用场景 |
|---|---|---|
| 普通笔记本 | 实时推理 | 批量处理 |
| 浏览器 | WebGPU演示版 | - |
| 服务器集群 | 低成本海量数据处理 | 生产环境部署 |
六、未来路线图
- ColSmolVLM:深化多模态检索系统开发
- SmolDocling:与IBM合作文档处理专项优化
- 量化版本:计划推出4-bit量化模型

技术启示:通过视觉编码器重构+数据配比优化+token压缩技术,验证了小模型在特定任务上可超越历史大模型的可行性,为边缘计算场景的VLM部署提供了新范式。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











