







目录
一、认识文件系统
我们之前对文件的学习都是内存级别的,那么在文件没有被进程打开之前,这个文件是什么样的状态?
不是所有的文件都会在OS内存中被打开(大部分文件都不是被打开的),这些没有被打开的文件在磁盘中保存。也要把这些文件安装一定规律管理好,方便用户进行及时查找、快速查找、方便查找,用户随时读取时要随时打开、随时进行把文件数据快速加载到内存。管理是为了解决快速定位问题。管理这些没有被打开的磁盘文件,就叫做文件系统。
例如我们身上只穿一套衣服,其他衣服也要在柜子里整理好,否则下次需要用到时查找效率特别低下。
综上,文件的管理工作:
- 对打开的文件进行管理
- 没有被打开的文件也要在磁盘中进行管理。
文件系统实现文件管理工作。文件系统核心工作之一:快速定位到文件(通过路径机制或管理机制等)
文件 = 内容 + 属性
- 文件的存储问题最终本质就是将文件内容和文件属性存储的问题。
- 文件存储在磁盘中,那么对于文件方便OS/用户就要进行磁盘级别的增删查改。
之前讲到 一切皆文件 的概念,即OS通过软件的方式,对底层硬件的差异化进行屏蔽,这种动作叫做逻辑抽象。逻辑抽象给OS提供了一个管理的统一视角,为OS管理磁盘做准备。
- 磁盘 --- 硬件 --- 物理存储结构
- 逻辑抽象 --- 逻辑存储结构
二、认识磁盘

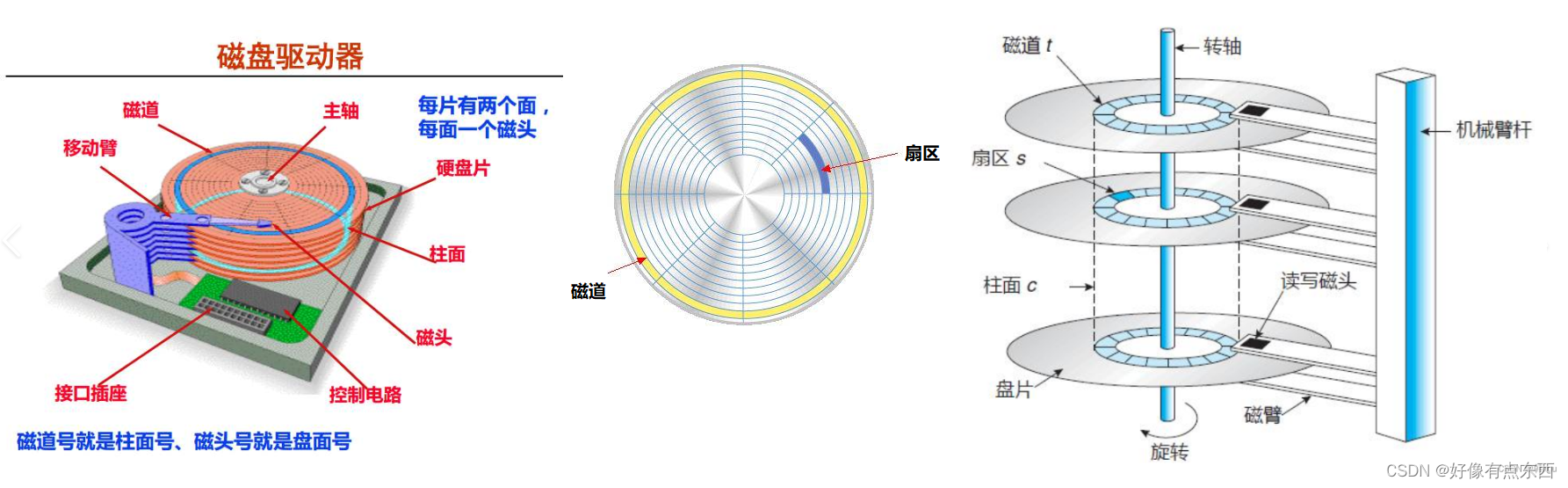
磁盘的特点:
- 磁盘 --- 硬件 --- 物理存储结构。
- 磁盘容量大、便宜、企业可以大量使用。
- 通过磁头的摆动和盘片的旋转可以读取磁盘中的所有内容。
- 一个盘面可以有很多的同心磁道,一圈磁道可以有很多扇形的扇区
- 扇区是磁盘的最小存储单元 ---- 一般是512字节
哪怕只需要访问1个比特位,磁盘也会读取512字节,所以磁盘是块设备。
(支持随机存取,且有最小存储单元的设备是块设备)
如果我想向一个扇区写入,我们该如何寻址,定位?
(CHS定位法)
1.选择哪一面 --- 本质选择磁头(head)2.选择该面上的哪一个磁道 (track / cylinder柱面)
3.选择在该磁道的哪一个扇区 (sector)我们可以向一个扇区写入,就可以向任意一个/多个扇区写入,也连续多个扇区式的写入,当然也可以随机写入。
磁头左右摆动可以定位柱面/磁道,盘片旋转可以定位扇区。
三、磁盘文件系统
3.1 磁盘存储的抽象逻辑结构
为了方便操作系统统一管理磁盘,也为了对磁盘进行更好的逻辑抽象,进而实现各种各样的逻辑结果,所以就必须对磁盘的存储结构做抽象。
磁盘存储的逻辑抽象结构:
- 将磁盘盘片想象成线性空间
- 整个磁盘就是sector sec[ ],即以扇区为单位的数组。
1~100000 第一面,100001~200000 第二面 ......
1~10000 第一个磁道,10001~20000 第二个磁道 ......- 对磁盘的管理,就变成了对数组的管理。就可以完成由数组下标转化成对应磁盘的CHS地址。
操作系统可以按照扇区为单位进行存取,也可以基于文件系统,按照文件块为单位进行数据存取。(文件块 —— 8个扇区,4KB,文件保存属性和内容的基本单元)
从此操作系统不需要关心扇区或者磁道,只要文件块起始地址,就能一次连续访问8个扇区(4KB)。这个起始地址叫做LBA地址(Logical Block Addressing逻辑块地址)。
将磁盘看作4KB block[n](4KB大小的文件块数组),每一个4KB都有它对应的LBA起始地址,从此OS对磁盘的管理、对文件系统的管理,就变成了对文件块数组的管理。
例如有500GB的磁盘要进行文件管理,可以先把它们分区,每个区100G,然后再对每个区分组(每个组包含多个块),把一个组的空间管理好,那么其他组也可以按照这个方法管理,最后实现对500GB的磁盘文件管理。(在每个分区上创建文件系统,并使用组(groups)来管理文件系统)
3.2 磁盘文件系统图
以下是磁盘文件系统的一个分区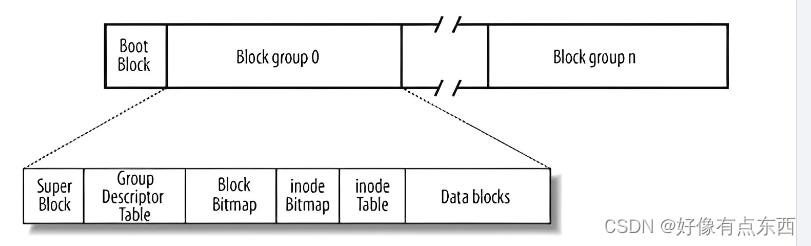
Boot Block:启动块,位于文件系统的最前端(例如编号为0的磁头、编号为0的盘面、编号为0的磁道的第一个扇区),用于启动文件系统。它包含了文件系统的基本信息,如文件系统类型、磁盘有多少区,每个区的开始和结束位置等。
Block group:文件系统中的数据块组,包含文件信息和用于文件管理的数据。文件内容和属性分开存储。
在使用磁盘之前把磁盘分区,使用分区之前要先让管理数据写入到块组当中,这个工作叫做格式化。(把管理数据恢复出厂设置等)
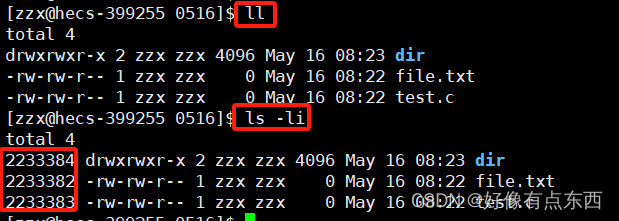
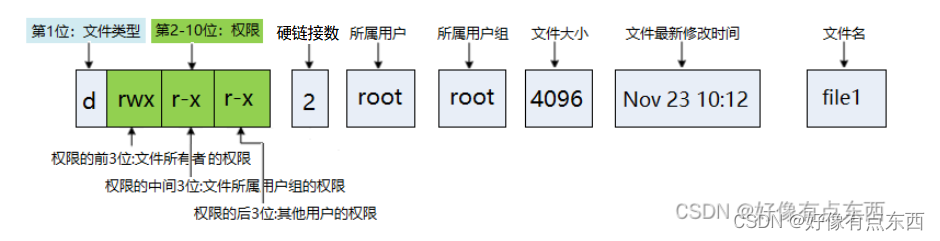
使用 ls -li 文件属性列表最前面多了一列,这一列数字就是inode编号。
- 一般情况一个文件一个inode,每个文件都有inode。
- inode编号在整个分区具有唯一性。(不是磁盘)
- 在Linux内核中,识别一个文件与文件名无关,只与 inode 有关
Inode Table:节点表,包含了文件的属性信息,如创建时间、修改时间、访问权限等。
每个inode固定128字节,在节点表中也容易定位,只需要inode编号即可。
inode节点里有一个blocks数组,数组保存这个inode对应文件的blocks块号。数组大小一般为15(前13个1级映射,第14个2级映射,第15个3级映射)(数据文件块也可以放索引)(跨区/组存储是通过索引连接的)
inode通常包含以下信息:
文件类型:文件或目录的类型(如普通文件、目录、符号链接等)。
权限:文件或目录的访问权限,包括读(r)、写(w)、执行(x)权限。
所有者:文件的拥有者用户ID。
组:文件的拥有者所属的用户组ID。
链接数:指向该文件的硬链接数量。
文件大小:文件的大小,以字节为单位。
创建时间:文件或目录的创建时间。
修改时间:文件或目录的最后修改时间。
访问时间:文件或目录的最后访问时间。
数据块:文件的数据块列表,每个数据块包含文件的实际数据
Data blocks:数据区,用于存储文件的实际数据内容。包含很多4KB的文件块,每个文件块也有对应的编号。
查找文件内容只需要知道文件的inode编号,就能定位在哪个区,通过inode里面blocks数组的内容可以查找到文件的内容。
Inode Bitmap:inode位图,通过比特位记录每个inode的状态,即哪些inode被占用,哪些inode是空闲的。例如1字节(8bit)可以记录8个inode的状态
Block Bitmap:块位图,用比特位记录每个数据块的状态,即哪些块被占用,哪些块是空闲的。
3.3 创建和删除文件
在Linux文件系统中,创建文件时,涉及以下步骤和组件的工作:
- 分配inode:文件系统从inode位图中分配一个空闲inode。将对应比特位 置为1,通过偏移量可以找到对应的inode,填充inode中的数据。
- 分配数据块:如果文件有数据,存储文件需要一些块,文件系统从块位图中分配一个或多个数据块来存储文件内容。通过偏移量可以得到块号,再将块号更新到 inode 中的blocks数组中。
- 更新目录:文件系统在父目录的目录项中添加新文件的inode编号,使其在目录中可见。
删除文件时,只需要更改位图。根据inode中blocks找到块位图对应的bit并置为0,根据inode编号将inode位图对应的bit也置为为0。表示inode、Data blocks无效。
文件恢复,需要inode编号,就能把inode位图的对应比特置为1,根据blocks找到块组,将块位图对应比特位置为1。
Group Descriptor Table:块组描述符,位于super block之后,用于描述每个数据块组的信息,包括该组内的块数量、inode数量等。
Super Block:位于block group 的起始位置,包含了文件系统本身的结构信息。不一定每一个块组都有。记录的信息主要有:bolck 和 inode的总量, 未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。一个分区有多个Super Block,当所有的Super Block信息被破坏,可以说整个文件系统结构就被破坏了。因为有多个Super Block,所以1个或多个Super Block被破坏时,只要找到一个没有被破坏的,就可以进行修复,这提高了文件系统的健壮性。
以上的文件系统称作 Ext2 文件系统。
3.4 如何理解目录?
用户不需要知道inode编号,只知道文件名。目录也是文件,有自己的数据块,目录内部保存的是文件的文件名和 inode 的映射关系(文件可以是任何文件)。所以用户访问一个文件时,只要找到文件所在目录,就能根据文件名找到对应的 inode 编号,然后就能找到对应的inode和数据块。这也说明了为什么同一个目录不能存在同名文件。也说明了为什么一个目录中新建、删除、修改文件需要目录的 w 权限。(需要新增、删除或修改映射关系)
inode中没有文件名,Linux中文件名不属于文件属性,只有inode编号,文件名在目录中存放。
3.5 如何查找一个文件
查找文件,需要知道文件所在的目录,找到目录文件并打开,目录文件的内容中就有文件名和inode编号的映射关系,根据inode编号找到文件所在分组、inode Table,就能找到inode,并将它的所有属性加载到内存里。(一般从根目录开始找,需要路径结构。路径结构的来源:用函数打开路径时要提供路径信息,pwd环境变量也会提供路径信息)
Linux会把高频访问的路径放在缓存里。struct dentry目录项是Linux内核中定义的一个数据结构,用于表示文件系统的目录项。目录项包含文件名、与其他目录项的关联关系、以及一些缓存信息。它不是一个用户空间可访问的结构,而是内核空间的一部分。(struct dentry的定义可以在Linux内核源代码的fs/namei.c文件中找到)
3.6 查找文件的一般流程
- 用户输入文件路径,如/home/user/document.txt。
- 操作系统使用getcwd()函数或pwd环境变量来获取当前工作目录。
- 从根目录(/)开始,使用open()或stat()系统调用来访问路径的各个组成部分。
- Linux内核使用struct dentry数据结构来构建路径树,每个struct dentry实例代表路径树中的一个节点。
- struct dentry包含了文件名和 inode 编号的映射关系,以及指向父目录和子目录的指针,方便OS查找。
- Linux内核会尝试在struct dentry缓存中查找路径。如果缓存中有对应的struct dentry实例,则直接使用该实例,避免了对磁盘的访问。
- 如果缓存中没有对应的struct dentry实例,内核会继续沿着路径树向下查找,直到找到对应的目录项。
- 在每个目录中,内核会查找包含文件名的struct qstr,并将其与路径中的文件名进行匹配。
struct qstr 包含了文件名的哈希值,用于快速查找。 - 一旦找到对应的struct dentry实例,内核会根据inode编号在inode表中查找对应的inode。inode包含了文件的属性数据,如权限、所有者、大小、创建和修改时间等。
- 内核将找到的inode的所有属性加载到内存中,这样就可以了解文件的具体信息。
- 一旦文件被找到,用户就可以使用open()、read()、write()等系统调用来访问文件。
Linux内核会尽量减少对磁盘的访问,以提高性能。
3.7 如何确定文件所在的分区
访问文件的时候,最开始是要知道这个文件在哪一个分区里面。因为虽然inode编号在整个分区具有唯一性,但是其它分区也可能会有相同的inode编号。(之前的创建、删除、查找文件讨论的都是在同一个分区的情况,一个分区一个文件系统)
一个磁盘被分区格式化之后,Linux中要使用这个分区,要把这个分区进行挂载(mount)。挂载将一个分区关联到一个目录,使得访问该目录时就可以确定哪个分区被访问和使用。
每一个文件都有路径,可以通过路径的前缀判断出路径在哪一个分区下。
3.8 总结
int fd = fopen("./log.txt", "r");这个函数做了哪些事?
答:
- 打开文件:进程执行该函数操作,打开了这个文件。函数提供了路径、文件名、打开方式。
- 路径和文件名:进程有自己的cwd,结合传入的路径,可以定位到文件在磁盘的哪个位置。
- 定位分区、上级目录:根据路径确定分区、上级目录。
- 目录文件中的映射关系:根据目录文件中的文件名和inode编号的映射关系能找到文件名对应的inode编号。
- 找到inode和属性加载:通过inode编号就能找到inode,可以获得文件的属性。将inode的所有属性加载到内存中,创建一个struct inode对象。。
- 构建struct file对象:内核使用inode构建struct file对象来代表这个文件,与文件描述符表连接,分配文件描述符,用户空间通过文件描述符fd来访问这个struct file对象。
- 预加载Data blocks数据块:根据inode找到对应的Data blocks数据块,内核可以预加载文件的数据块到内存中的缓冲区。
- 读取数据:当用户空间需要读取数据时,内核将内存缓冲区的数据拷贝到应用层。应用层可以访问这些数据,并进行进一步的处理。
四、软硬链接
4.1 引入
在Linux文件系统中,硬链接(Hard Link)和软链接(Symbolic Link)是两种不同的链接方式,用于在文件系统中创建指向文件或目录的链接。
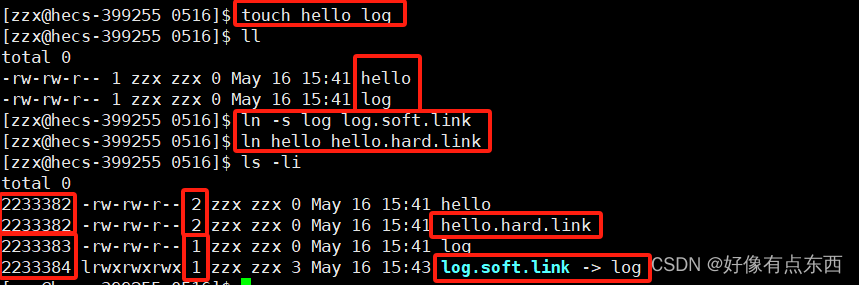
通过ln -s 创建 log 文件的软链接,ln 创建 hello 文件的硬链接。
发现软链接的inode编号与源文件不同,而且还有箭头指向源文件;硬链接的inode编号与源文件相同,但硬链接数变为2。
说明软连接是一个独立的文件,硬链接不是独立的文件,因为他没有独立的inode编号。
4.2 软链接(Symbolic Link)
软链接,也称为符号链接或快捷方式,是一个特殊的文件,包含指向另一个文件或目录的路径。
软链接具有以下特点:
- 包含路径:软链接包含一个路径,指向另一个文件或目录。
- 可以跨越文件系统:软链接可以跨越不同的文件系统。
- 占用额外空间:软链接有自己的inode编号,本身是一个文件,所以会占用额外的磁盘空间。有自己的数据块,修改了inode bitmap和block bitmap等。
- 删除原始文件会影响软链接:如果原始文件(或目录)被删除,软链接将无法访问。
- 它不指向原始文件的inode编号,而是指向原始文件或目录的路径。
软链接创建一个指向常用目录或文件的快捷方式,以便快速访问。
创建软链接的命令是 ln,需要指定 -s 或 --symbolic 选项,例如:
ln -s original_file symbolic_link_name4.3 硬链接(Hard Link)
硬链接不是独立的文件,是在指定目录内部的一组映射关系:文件名 <-> inode 的映射关系!
硬链接用于创建与原始文件相同的inode编号的另一个文件名。
硬链接具有以下特点:
- 指向同一inode:多个硬链接指向同一个inode,所以它们都指向相同的文件数据。
- 不跨越文件系统:硬链接不能跨越不同的文件系统。
- 不能指向目录:不能对目录建立硬链接,只能指向文件。
- 不占用额外空间:硬链接不会占用额外的磁盘空间,因为它们都指向相同的inode。
- 删除原始文件不影响硬链接:删除原始文件(inode)不会影响硬链接,因为硬链接仍然指向同一个inode。但是会将目标文件的硬链接数减1。
硬链接数:
没有文件名和inode映射时,文件被真正删除。inode中包含一个引用计数字段ret_count,表明有几个文件名和它映射。文件名在目录文件中具有唯一性,类似于指针,指向对应的inode,每增加一个文件名指向inode,inode的引用计数加1,每删除一个指向inode的文件名,引用计数减1。该引用计数也对应着硬链接数。
新创建文件时,硬链接数为1;新创建目录时,硬链接数为2。
因为目录创建时会包含两个因此的文件: . (当前目录) 和 .. (上级目录)
当前目录(.)的inode 和 目录的inode是同一个。同理,新创建目录时,包含该目录的上级目录的硬链接数变为3。
为什么不能对目录建立硬链接?
对于目录来说,硬链接的创建会破坏文件系统的目录结构。目录通常是文件系统树结构的组成部分,每个目录都有一个指向其父目录的硬链接(.),以及指向其自身的硬链接(..)。如果允许对目录创建硬链接,可能会导致循环引用,在使用某些查找命令时(例如find),通常要指定路径,实际在查找时会不断遍历对应的目录,对目录中所有的文件名和inode进行甄别和查找,软链接是个普通文件不用进入查询,而硬链接的目录是目录文件,需要打开目录继续查询,此时就会不断递归。从而破坏了文件系统树形结构的完整性。(形成了环状路径)
(.)和(..)是特殊情况,Linux自己设置的硬链接,不允许用户自己设置。find操作时不会考虑(.)和(..)
硬链接用来进行路径切换,构建了Linux的整个路径结构,方便进行路径回退。
创建硬链接的命令是 ln,例如:
ln original_file hard_link_name














 1292
1292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









