





本文章版本为Apache Storm1.1.0
主要为翻译Apache Storm官方文档,但也参考其他的技术博客的思想,如有参考会在最后贴上链接
Trident是基于Storm的一个可选择接口,它提供正好一次的处理,事务性持久化数据存储,和一系列的共通流分析操作。
本章是Trident的基础概念和操作攻略。
Trident是基于Storm的高级别实时计算框架,允许你实现无间隙的混合高吞吐量(能达到每秒数百万条信息处理),状态流处理和低延迟的分布式请求。如果你很熟悉高级的批处理工具,类似于Pig和Cascading,就会发现Trident的概念很类似-Trident有joins,aggregations,grouping,functions,和filters。除了这些,Trident增加了状态化,基于任何形式的数据库和持久化存储的递增操作。Trident有一致性,正好一次处理语法,所以很容易就能推导出Trident的拓扑逻辑。
解说示例
示例做两件事情
1.从输入的语句流中实时计算单词数量
2.为一系列单词实现请求,得到每个单词的统计数量
为了解说, 这个例子讲从下列资源中读取一个无限制的句子流:
FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 3,
new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"),
new Values("four score and seven years ago"),
new Values("how many apples can you eat"));
spout.setCycle(true);这段代码用于实时单词计数。
TridentTopology topology = new TridentTopology();
TridentState wordCounts =
topology.newStream("spout1", spout)
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"))
.parallelismHint(6);Trident以小批量的tuples处理流。例如,输入的语句流可能被分割成批为下面这样:
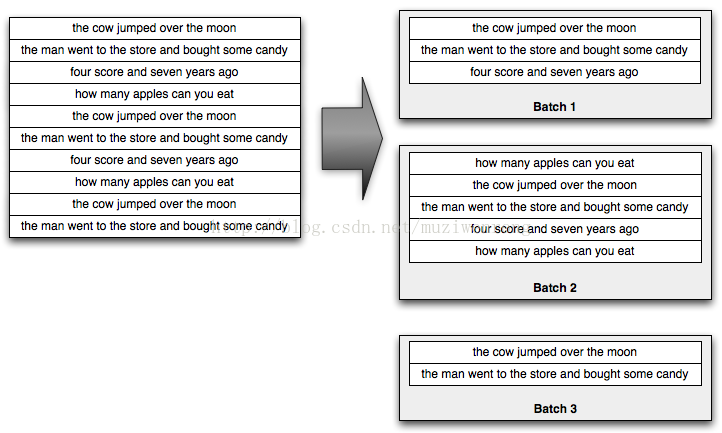
一般的这些按照数以万计的tuples的顺序分割出来的的小批次,他们的大小依赖于你输入的吞吐量。
Trident提供完善的批量处理接口API,用于处理这些小批次。该API和Pig或者Cascading针对于Hadoop的高级抽象接口非常相似:可以进行group by`s,joins,aggregations,run functions,run filters,等等。当然,单独隔离地处理每一个小批次很无聊,所以Trident提供了函数,用于处理聚集所有批次,持久化存储这些聚集-不论是存储在内存,Memcached,Cassandra,还是其他形式的存储。最终,Trident使用头等函数(first-class)提供实时状态资源。这个状态能被Trident更新(像示例中的这样),或者成为一个独立的状态资源。
返回这个示例,spout发出一个包含“sentence”字段的流。拓扑的下一行定义了应用于流中的每一个tuple的Split函数,获得“sentence”字段,将语句分割成单独的单词。每一个语句tuple能潜在的创建出许多个单词tuples-例如:语句“the cow jumped over the moon”创造出六个“单词”tuples。这是Split的定义:
public class Split extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
collector.emit(new Values(word));
}
}
}剩余的拓扑逻辑计算单词数量和持久化存储计算结果。首先流按照“word”字段分组,然后使用Count聚集器持久的聚集。这个persistentAggregate函数知道如何将聚集结果存储或者更新进状态资源。在这个例子中,单词计数被保存在内存中,也可以很一般地使用Memcached,Cassandra,或者其他形式的持久化存储替换内存。替换这个拓扑的计数存储进Memcached很简单,只需要替换persistentAggregate代码(使用trident-memcached),“serverLocations”是一系列的Memcached集群的主机/端口:
.persistentAggregate(MemcachedState.transactional(serverLocations), new Count(), new Fields("count"))
MemcachedState.transactional()Trident完全容错,和正好一次处理的语义。能很简单地推导出来实时处理。Trident维持状态的方案是当错误发生时, 必须重试,但是它不会将相同的来源数据多次更新进数据库。
persistentAggregate方法将流转换成TridentState对象,在这种情况下TridentState对象表示所有的单词计数,我们将使用这个TridentState对象实现分布式查询计算的部分结果。
下一部分的拓扑实现了对单词计数的低延迟分布式请求。这个请求带有用空格分隔开的一列单词,请求返回这些单词计数的合。这些请求类似于一般的RPC调用,但这些调用是并行执行的。这是一个如何调用这些请求的例子:
DRPCClient client = new DRPCClient("drpc.server.location", 3772);
System.out.println(client.execute("words", "cat dog the man");
// prints the JSON-encoded result, e.g.: "[[5078]]"部分分布式请求拓扑的实现像下面这样:
topology.newDRPCStream("words")
.each(new Fields("args"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.stateQuery(wordCounts, new Fields("word"), new MapGet(), new Fields("count"))
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));每一个DRPC请求被当作它的小批量处理任务,任务将输入作为独立的tuple表示请求。tuple包含一个“args”的字段,包含客户端提供的所有参数。这个例子中,参数是用空格分隔开的一列单词。
首先,Split函数将请求中的参数分割成本来组成它的各个单词。流通过“word”分组,stateQuery操作是请求拓扑第一部分产生的TridentState对象。stateQuery访问状态的资源-在这个例子中,状态表示被其他拓扑部分计算出来的单词的数量-并请求这些状态。这个例子中,MapGet方法被调用,用于获得每一个单词的计数。因为DRPC流被以TridentState相同的方式分组(使用“word”分组),每一个单词请求被路由精确的TridentState对象的某一部分,用于更新单词。
下一步,被FilterFull过滤器过滤掉的单词不计数,然后通过Sum函数将计数聚集进一个结果中。最后Trident自动发送这些结果给等待的客户端。
Trident能够智能地在执行拓扑的时候最大化效率。这里有两个在拓扑过程中自动发生的有意思的事情:
1.读或者写状态的操作(像persistentAggregate和stateQuery)自动批量执行这些状态。
参考链接:Storm DRPC介绍 http://www.dataguru.cn/article-5572-1.html














 108
108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









