







 本文详细介绍了基于 Storm 的 Trident 实时计算框架的核心概念,包括 Stream 数据模型、TridentFunction 和 TridentFilter 的使用方法,以及 projections 和 repartitioning operations 的功能特性。
本文详细介绍了基于 Storm 的 Trident 实时计算框架的核心概念,包括 Stream 数据模型、TridentFunction 和 TridentFilter 的使用方法,以及 projections 和 repartitioning operations 的功能特性。
1、简介
2、
TridentFunction
3、
TridentFilter
4、projections
5、Trident repartitioning operations
5.1)The shuffle operation
5.2)The partitionBy operation
5.3)The global operation
5.4)The broadcast operation
5.5)The batchGlobal operation
6、The partition aggregate
1、简介:Trident是在storm基础上,一个以实时计算为目标的高度抽象。 它在提供处理大吞吐量数据能力(每秒百万次消息)的同时,也提供了
低延时分布式查询和有状态流式处理的能力
。 Tident提供了 joins, aggregations, grouping, functions, 以及 filters等能力。除此之外,Trident 还提供了一些专门的原语,从而在基于数据库或者其他存储的前提下来应付有状态的递增式处理。
Trident也提供一致性(consistent)、有且仅有一次(exactly-once)等语义
,这使得我们在使用trident toplogy时变得容易。
"Stream”是Trident中的核心数据模型,它被当做一系列的batch来处理。在Storm集群的节点之间,一个stream被划分成很多partition(分区),对流的操作(operation)是在每个partition上并行进行的。
对每个partition的局部操作包括:function(类似于bolts的execute)、filter、partitionAggregate、stateQuery、partitionPersist、project等。
2、
TridentFunction
Trident是在strom原生API封装的一个框架。并且提供了更强大的功能,可以理解为多了一些功能比如多了function、filter等等的操作。之前我们需要在Topology的execute方法里面接收上个组件发射过来的数据,处理完之后,声明输出内容,再发射到下个组件.而Trident采用组件与组件结合则采用链式编程的方式
在下面例子中
TridentFunction的buildTopology方法在方法里不是用原生的Topology而是使用了TridentTopology,并且组件与组件之间采用了链式编程的方式进行结合
public class TridentFunction {
//继承BaseFunction类,重新execute方法
public static class SumFunction extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
System.out.println("传入进来的内容为:" + tuple);
//获取a、b俩个域
int a = tuple.getInteger(0);
int b = tuple.getInteger(1);
int sum = a + b;
//发射数据
collector.emit(new Values(sum));
}
}
//继承BaseFunction类,重新execute方法
public static class Result extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
//获取tuple输入内容
System.out.println();
Integer a = tuple.getIntegerByField("a");
Integer b = tuple.getIntegerByField("b");
Integer c = tuple.getIntegerByField("c");
Integer d = tuple.getIntegerByField("d");
System.out.println("a: "+ a + ", b: " + b + ", c: " + c + ", d: " + d);
Integer sum = tuple.getIntegerByField("sum");
System.out.println("sum: "+ sum);
}
}
public static StormTopology buildTopology() {
TridentTopology topology = new TridentTopology();
//设定数据源
FixedBatchSpout spout = new FixedBatchSpout(
new Fields("a", "b", "c", "d"), //声明输入的域字段为"a"、"b"、"c"、"d"
4, //设置批处理大小为1
//设置数据源内容
//测试数据
new Values(1, 4, 7, 10),
new Values(1, 1, 3, 11),
new Values(2, 2, 7, 1),
new Values(2, 5, 7, 2));
//指定是否循环
spout.setCycle(false);
//指定输入源spout
Stream inputStream = topology.newStream("spout", spout);
/**
* 要实现流sqout - bolt的模式 在trident里是使用each来做的
* each方法参数:
* 1.输入数据源参数名称:"a", "b", "c", "d"
* 2.需要流转执行的function对象(也就是bolt对象):new SumFunction()
* 3.指定function对象里的输出参数名称:sum
*/
inputStream.each(new Fields("a", "b", "c", "d"), new SumFunction(), new Fields("sum"))
/**
* 继续使用each调用下一个function(bolt)
* 第一个输入参数为:"a", "b", "c", "d", "sum"
* 第二个参数为:new Result() 也就是执行函数,第三个参数为没有输出
*/
.each(new Fields("a", "b", "c", "d", "sum"), new Result(), new Fields());
return topology.build(); //利用这种方式,我们返回一个StormTopology对象,进行提交
}
public static void main(String[] args) throws Exception {
Config conf = new Config();
//设置batch最大处理
conf.setNumWorkers(2);
conf.setMaxSpoutPending(20);
if(args.length == 0) {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("trident-function", conf, buildTopology());
Thread.sleep(10000);
cluster.shutdown();
} else {
StormSubmitter.submitTopology(args[0], conf, buildTopology());
}
}
}

3、TridentFilter
TridentFilter可以海量数据进行过滤,需要继承BaseFilter,重写isKeep方法
TridentFilter可以海量数据进行过滤,需要继承BaseFilter,重写isKeep方法
public class TridentFilter {
//继承BaseFilter类,重新isKeep方法
public static class CheckFilter extends BaseFilter {
@Override
public boolean isKeep(TridentTuple tuple) {
int a = tuple.getInteger(0);
int b = tuple.getInteger(1);
if((a + b) % 2 == 0){
return true;
}
return false;
}
}
//继承BaseFunction类,重新execute方法
public static class Result extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
//获取tuple输入内容
Integer a = tuple.getIntegerByField("a");
Integer b = tuple.getIntegerByField("b");
Integer c = tuple.getIntegerByField("c");
Integer d = tuple.getIntegerByField("d");
System.out.println("a: "+ a + ", b: " + b + ", c: " + c + ", d: " + d);
}
}
public static StormTopology buildTopology() {
TridentTopology topology = new TridentTopology();
//设定数据源
FixedBatchSpout spout = new FixedBatchSpout(
new Fields("a", "b", "c", "d"), //声明输入的域字段为"a"、"b"、"c"、"d"
4, //设置批处理大小为1
//设置数据源内容
//测试数据
new Values(1, 4, 7, 10),
new Values(1, 1, 3, 11),
new Values(2, 2, 7, 1),
new Values(2, 5, 7, 2));
//指定是否循环
spout.setCycle(false);
//指定输入源spout
Stream inputStream = topology.newStream("spout", spout);
/**
* 要实现流sqout - bolt的模式 在trident里是使用each来做的
* each方法参数:
* 1.输入数据源参数名称:subjects
* 2.需要流转执行的function对象(也就是bolt对象):new Split()
*/
inputStream.each(new Fields("a", "b", "c", "d"), new CheckFilter())
//继续使用each调用下一个function(bolt)输入参数为subject和count,第二个参数为new Result() 也就是执行函数,第三个参数为没有输出
.each(new Fields("a", "b", "c", "d"), new Result(), new Fields());
return topology.build(); //利用这种方式,我们返回一个StormTopology对象,进行提交
}
public static void main(String[] args) throws Exception {
Config conf = new Config();
//设置batch最大处理
conf.setNumWorkers(2);
conf.setMaxSpoutPending(20);
if(args.length == 0) {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("trident-function", conf, buildTopology());
Thread.sleep(10000);
cluster.shutdown();
} else {
StormSubmitter.submitTopology(args[0], conf, buildTopology());
}
}
}

4、projections
projections的意思是
通过inputStream.project(new Fields("a"));,仅仅保留我们在上面声明的abcd中的a的域。
5、Trident repartitioning operations
在这一节博客里我们提到过storm里面的分组。比如我想在广播分组我就写All Grouping,我想按字段分组我就写Fields Grouping等等,但是在Trident里面我们可以这样写
5.1)The shuffle operation表示随机分组,我们直接想下面这样写就行了(调用mystream的shuffle()方法)
mystream.shuffle().each(new Fields("a","b"), new
myFilter()).parallelismHint(2)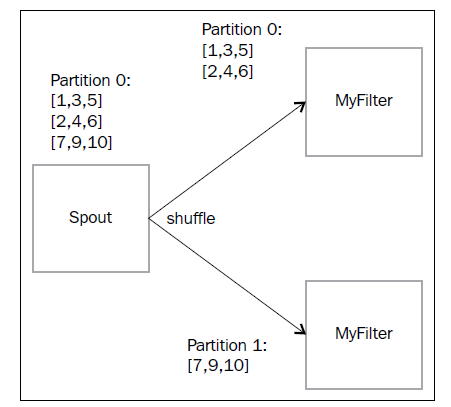
5.2)The partitionBy operation类似于Fields Grouping(字段分组)
mystream.partitionBy(new Fields("username")).each(new
Fields("username","text"), new myFilter()).parallelismHint(2)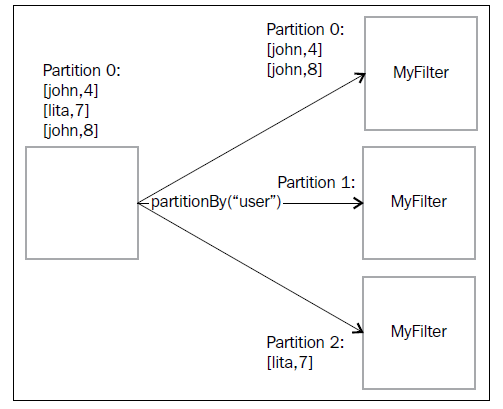
5.3)The global operation全局分组(有点汇总的意思)
mystream.global().each(new Fields("a","b"),
new myFilter()).parallelismHint(2)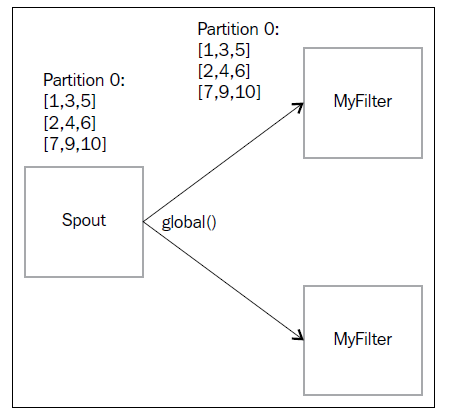
5.4)The broadcast operation广播分组
mystream.broadcast().each(new Fields("a","b"),
new myFilter()).parallelismHint(2)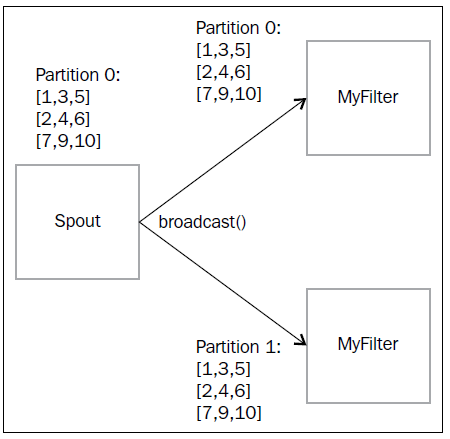
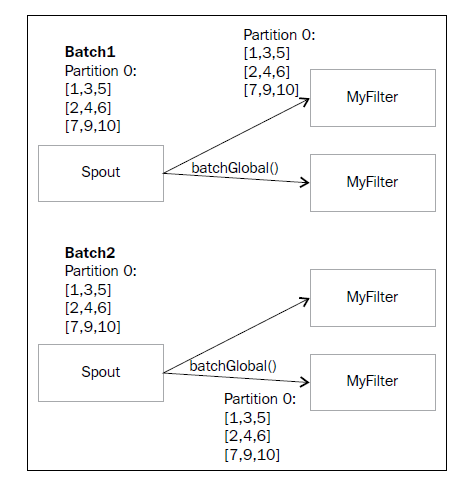
5.5)The batchGlobal operation:批量发送的意思,使用场景,比如说你这个三个数据是一组的,要么全部成功,要是失败了(Trident就是通过这种批量发到一个bolt上,要么一起成功要么一起失败,来维护一个事务,失败了,这个三个数据就一起重新发一次。如果不用这种分组,使用其他类型的分组,有可能这三个数据会被分发到不同的bolt上,这样就有可能出现其中一个失败了,另外2个处理成功了,这种情况如果需要做好事务,那么就需要记录在数据库记录一个ID,这个ID表示这3个数据是一组的,并且这3个数据有一个状态,处理成功了那么状态就是1,处理失败了就是0,最后我们就知道这3个数据是没有全部成功的,需要进行重发。不管是那种情况,由于数据可能发生重发的情况,所以程序要做好幂等的逻辑判断),这个三个数据可以重新再发一次。可以使用到这个批量操作
mystream.batchGlobal().each(new Fields("a","b"),
new myFilter()).parallelismHint(2)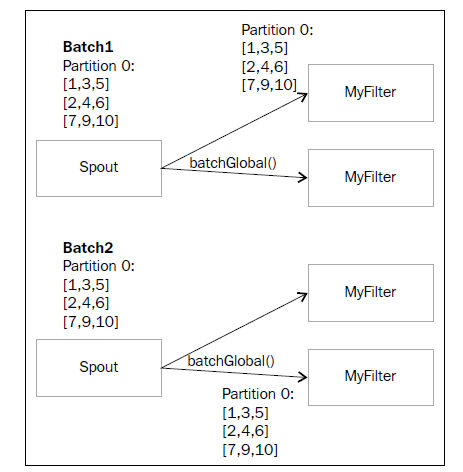
5.6)The partition operation
例子代码:
public class StrategyTopology {
public static StormTopology buildTopology() {
TridentTopology topology = new TridentTopology();
//设定数据源
FixedBatchSpout spout = new FixedBatchSpout(
new Fields("sub"), //声明输入的域字段为"sub"
4, //设置批处理大小为4
//设置数据源内容
//测试数据
new Values("java"),
new Values("python"),
new Values("php"),
new Values("c++"),
new Values("ruby"));
//指定是否循环
spout.setCycle(true);
//指定输入源spout
Stream inputStream = topology.newStream("spout", spout);
/**
* 要实现流sqout - bolt的模式 在trident里是使用each来做的
* each方法参数:
* 1.输入数据源参数名称:"sub"
* 2.需要流转执行的function对象(也就是bolt对象):new WriteFunction()
* 3.指定function对象里的输出参数名称,没有则不输出任何内容
*/
inputStream
//随机分组:shuffle
.shuffle()
//分区分组:partitionBy
//.partitionBy(new Fields("sub"))
//全局分组:global
//.global()
//广播分组:broadcast
//.broadcast()
.each(new Fields("sub"), new WriteFunction(), new Fields()).parallelismHint(4);
return topology.build(); //利用这种方式,我们返回一个StormTopology对象,进行提交
}
public static void main(String[] args) throws Exception {
Config conf = new Config();
//设置batch最大处理
conf.setNumWorkers(2);
conf.setMaxSpoutPending(20);
if(args.length == 0) {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("trident-strategy", conf, buildTopology());
Thread.sleep(5000);
cluster.shutdown();
} else {
StormSubmitter.submitTopology(args[0], conf, buildTopology());
}
}
}
6、The partition aggregate
下列代码表示先按照域x进行分组,然后进行统计,最后输出。Count()是自带的API,不需要我们自己实现。
mystream.partitionAggregate(new Fields("x"), new Count(), new
Fields("count"))

















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









