







1.创建类与堆栈框架
1 )对象调用实例方法,也就是向一个对象发送消息 时,运行时系统会在对象所属类的方法集合中查找方法。
2 )类调用类方法,也就是向一个类发送消息时,运行时系统会在类的 meta-class 的 方法集合中查找方法。
1.1 buildCore
//编译核心模块
void buildCore(VM* vm) {
//核心模块不需要名字,模块也允许名字为空
ObjModule* coreModule = newObjModule(vm, NULL);
//创建核心模块,录入到vm->allModules
mapSet(vm, vm->allModules, CORE_MODULE, OBJ_TO_VALUE(coreModule));
//创建object类并绑定方法
vm->objectClass = defineClass(vm, coreModule, "object");
PRIM_METHOD_BIND(vm->objectClass, "!", primObjectNot);
PRIM_METHOD_BIND(vm->objectClass, "==(_)", primObjectEqual);
PRIM_METHOD_BIND(vm->objectClass, "!=(_)", primObjectNotEqual);
PRIM_METHOD_BIND(vm->objectClass, "is(_)", primObjectIs);
PRIM_METHOD_BIND(vm->objectClass, "toString", primObjectToString);
PRIM_METHOD_BIND(vm->objectClass, "type", primObjectType);
//定义classOfClass类,它是所有meta类的meta类和基类
vm->classOfClass = defineClass(vm, coreModule, "class");
//objectClass是任何类的基类
bindSuperClass(vm, vm->classOfClass, vm->objectClass);
PRIM_METHOD_BIND(vm->classOfClass, "name", primClassName);
PRIM_METHOD_BIND(vm->classOfClass, "supertype", primClassSupertype);
PRIM_METHOD_BIND(vm->classOfClass, "toString", primClassToString);
//定义object类的元信息类objectMetaclass,它无须挂载到vm
Class* objectMetaclass = defineClass(vm, coreModule, "objectMeta");
//classOfClass类是所有meta类的meta类和基类
bindSuperClass(vm, objectMetaclass, vm->classOfClass);
//类型比较
PRIM_METHOD_BIND(objectMetaclass, "same(_,_)", primObjectmetaSame);
//绑定各自的meta类
vm->objectClass->objHeader.class = objectMetaclass;
objectMetaclass->objHeader.class = vm->classOfClass;
vm->classOfClass->objHeader.class = vm->classOfClass; //元信息类回路,meta类终点
}
//定义类
static Class* defineClass(VM* vm, ObjModule* objModule, const char* name) {
//1先创建类
Class* class = newRawClass(vm, name, 0);
//2把类做为普通变量在模块中定义
defineModuleVar(vm, objModule, name, strlen(name), OBJ_TO_VALUE(class));
return class;
}
暂时忽略PRIM_METHOD_BIND
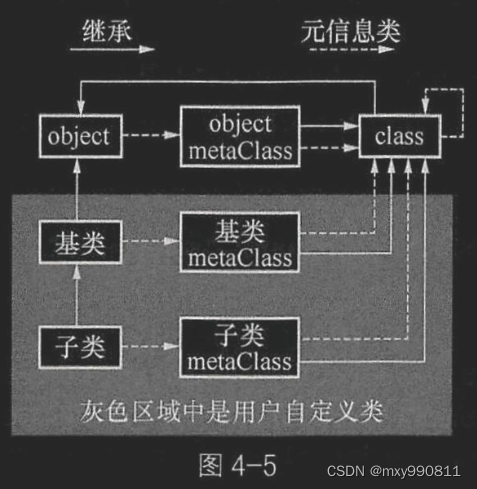
- defineClass创建object类保存于vm->objectClass
- defineClass创建object的metaClass,无需挂载到vm
- defineClass创建class类保存于vm->classOfClass
- object类的meta类设置为object的metaClass,即objHeader.class指向object的metaClass
- objectMetaclass类的meta类设置为class类
- class类的meta类设置为class类
2.newClass
//创建一个类
Class* newClass(VM* vm, ObjString* className, uint32_t fieldNum, Class* superClass) {
//10表示strlen(" metaClass"
#define MAX_METACLASS_LEN MAX_ID_LEN + 10
char newClassName[MAX_METACLASS_LEN] = {'\0'};
#undef MAX_METACLASS_LEN
memcpy(newClassName, className->value.start, className->value.length);
memcpy(newClassName + className->value.length, " metaclass", 10);
//先创建子类的meta类
Class* metaclass = newRawClass(vm, newClassName, 0);
metaclass->objHeader.class = vm->classOfClass;
pushTmpRoot(vm, (ObjHeader*)metaclass);
//绑定classOfClass为meta类的基类
//所有类的meta类的基类都是classOfClass
bindSuperClass(vm, metaclass, vm->classOfClass);
//最后再创建类
memcpy(newClassName, className->value.start, className->value.length);
newClassName[className->value.length] = '\0';
Class* class = newRawClass(vm, newClassName, fieldNum);
pushTmpRoot(vm, (ObjHeader*)class);
class->objHeader.class = metaclass;
bindSuperClass(vm, class, superClass);
popTmpRoot(vm); // metaclass
popTmpRoot(vm); // class
return class;
}
//新建一个裸类
Class* newRawClass(VM* vm, const char* name, uint32_t fieldNum) {
Class* class = ALLOCATE(vm, Class);
//裸类没有元类
initObjHeader(vm, &class->objHeader, OT_CLASS, NULL);
class->name = newObjString(vm, name, strlen(name));
class->fieldNum = fieldNum;
class->superClass = NULL; //默认没有基类
pushTmpRoot(vm, (ObjHeader*)class);
MethodBufferInit(&class->methods);
popTmpRoot(vm);
return class;
}
传入参数要创建的类名className、实例域数量fieldNum、superClass。
- 根据传入className的利用newRawClass创建了Class、metaClass。
- metaclass的meta类、基类都设置为class类
- class的meta类设置为metaclass,基类设置为superClass
3.ensureStack
//确保stack有效
void ensureStack(VM* vm, ObjThread* objThread, uint32_t neededSlots) {
if (objThread->stackCapacity >= neededSlots) {
return;
}
uint32_t newStackCapacity = ceilToPowerOf2(neededSlots);
ASSERT(newStackCapacity > objThread->stackCapacity, "newStackCapacity error!");
//记录原栈底以用于下面判断扩容后的栈是否是原地扩容
Value* oldStackBottom = objThread->stack;
uint32_t slotSize = sizeof(Value);
objThread->stack = (Value*)memManager(vm, objThread->stack,
objThread->stackCapacity * slotSize, newStackCapacity * slotSize);
objThread->stackCapacity = newStackCapacity;
//为判断是否原地扩容
long offset = objThread->stack - oldStackBottom;
//说明os无法在原地满足内存需求, 重新分配了起始地址,下面要调整
if (offset != 0) {
//调整各堆栈框架的地址
uint32_t idx = 0;
while (idx < objThread->usedFrameNum) {
objThread->frames[idx++].stackStart += offset;
}
//调整"open upValue"
ObjUpvalue* upvalue = objThread->openUpvalues;
while (upvalue != NULL) {
upvalue->localVarPtr += offset;
upvalue = upvalue->next;
}
//更新栈顶
objThread->esp += offset;
}
}
大运行时栈空间单位为Value。
根据传入参数neededSlots即需要的栈空间重新给objThread->stack申请动态内存,动态内存管理器memManager返回的内存地址如果变了,则给objThread->frames[idx++].stackStart和objThread->openUpvalues->localVarPtr重新加上改变的偏移offset。
4.createFrame
//为objClosure在objThread中创建运行时栈
inline static void createFrame(VM* vm, ObjThread* objThread,
ObjClosure* objClosure, int argNum) {
if (objThread->usedFrameNum + 1 > objThread->frameCapacity) { //扩容
uint32_t newCapacity = objThread->frameCapacity * 2;
uint32_t frameSize = sizeof(Frame);
objThread->frames = (Frame*)memManager(vm, objThread->frames,
frameSize * objThread->frameCapacity, frameSize * newCapacity);
objThread->frameCapacity = newCapacity;
}
//栈大小等于栈顶-栈底
uint32_t stackSlots = (uint32_t)(objThread->esp - objThread->stack);
//总共需要的栈大小
uint32_t neededSlots = stackSlots + objClosure->fn->maxStackSlotUsedNum;
ensureStack(vm, objThread, neededSlots);
//准备上cpu
prepareFrame(objThread, objClosure, objThread->esp - argNum);
}
//为运行函数准备桢栈
void prepareFrame(ObjThread* objThread, ObjClosure* objClosure, Value* stackStart) {
ASSERT(objThread->frameCapacity > objThread->usedFrameNum, "frame not enough!!");
//objThread->usedFrameNum是最新可用的frame
Frame* frame = &(objThread->frames[objThread->usedFrameNum++]);
//thread中的各个frame是共享thread的stack
//frame用frame->stackStart指向各自frame在thread->stack中的起始地址
frame->stackStart = stackStart;
frame->closure = objClosure;
frame->ip = objClosure->fn->instrStream.datas;
}
函数闭包objClosure作为线程objThread的参数,让线程来运行这个函数。objClosure->fn->instrStream.datas中保存了指令流。想要执行函数的指令流,需要线程来提供运行时栈,objThread->stack为线程的大栈,线程给每个函数分配一个框架objThread->frames,框架中包含一个从大栈分配出去的小栈来作为该函数的运行时栈,frame->stackStart为该函数栈的起始地址。
对于createFrame,每次想要给一个函数闭包创建一个框架,需要扩容线程框架数和线程大运行时栈栈空间:
- 先查看线程原来的框架数是否够用,不够则扩大一倍
- 根据当前大运行时栈的总空间和本函数闭包需要的栈空间objClosure->fn->maxStackSlotUsedNum来调用ensureStack重新扩容大运行时栈空间
- 以上两项扩容完毕后,objThread->usedFrameNum是最新可用的frame,调用prepareFrame使该frame的ip指向函数闭包指令流objClosure->fn->instrStream.datas,该frame的运行时栈指向大运行时栈中对应位置。
5.创建与关闭upvalue
函数的局部变量存在函数的frame指向的小运行时栈中,函数内部是可以定义函数的,如果内部函数引用了外部函数的局部变量被称为open upvalue,那么该内部函数对应的线程会保存upvalue队列(objThread->openUpvalues),其中每个upvalue的upvalue->localVarPtr指向外部函数运行时栈中的局部变量。
如果外部函数的生命周期结束了,内部函数还需要继续引用外部函数的局部变量,这时的局部变量被称为closed upvalue。在关闭本函数的upvalue的时候,会把upvalue被保存在upvalue->closedUpvalue,而upvalue->localVarPtr不再指向本函数运行时栈,而是指向upvalue->closedUpvalue
5.1 closeUpvalue、createOpenUpvalue
//关闭在栈中slot为lastSlot及之上的upvalue
static void closeUpvalue(ObjThread* objThread, Value* lastSlot) {
ObjUpvalue* upvalue = objThread->openUpvalues;
while (upvalue != NULL && upvalue->localVarPtr >= lastSlot) {
//localVarPtr改指向本结构中的closedUpvalue
upvalue->closedUpvalue = *(upvalue->localVarPtr);
upvalue->localVarPtr = &(upvalue->closedUpvalue);
upvalue = upvalue->next;
}
objThread->openUpvalues = upvalue;
}
//创建线程已打开的upvalue链表,并将localVarPtr所属的upvalue以降序插入到该链表
static ObjUpvalue* createOpenUpvalue(VM* vm, ObjThread* objThread, Value* localVarPtr) {
//如果openUpvalues链表为空就创建
if (objThread->openUpvalues == NULL) {
objThread->openUpvalues = newObjUpvalue(vm, localVarPtr);
return objThread->openUpvalues;
}
//下面以upvalue.localVarPtr降序组织openUpvalues
ObjUpvalue* preUpvalue = NULL;
ObjUpvalue* upvalue = objThread->openUpvalues;
//后面的代码保证了openUpvalues按照降顺组织,
//下面向堆栈的底部遍历,直到找到合适的插入位置
while (upvalue != NULL && upvalue->localVarPtr > localVarPtr) {
preUpvalue = upvalue;
upvalue = upvalue->next;
}
//如果之前已经插入了该upvalue则返回
if (upvalue != NULL && upvalue->localVarPtr == localVarPtr) {
return upvalue;
}
//openUpvalues中未找到该upvalue,
//现在就创建新upvalue,按照降序插入到链表
ObjUpvalue* newUpvalue = newObjUpvalue(vm, localVarPtr);
//保证了openUpvalues首结点upvalue->localVarPtr的值是最高的
if (preUpvalue == NULL) {
//说明上面while的循环体未执行,新结点(形参localVarPtr)的值大于等于链表首结点
//因此使链表结点指向它所在的新upvalue结点
objThread->openUpvalues = newUpvalue;
} else {
//preUpvalue已处于正确的位置
preUpvalue->next = newUpvalue;
}
newUpvalue->next = upvalue;
return newUpvalue;//返回该结点
}
createOpenUpvalue就是选择排序算法。从大到小排序
作用是在传入参数线程objThread的upvalue链表objThread->openUpvalues中,将传入的value创建为upvalue,并按从大到小顺序插入该链表,最后返回创建的upvalue结点
6.运行虚拟机
6.1 runFile
//执行脚本文件
static void runFile(const char* path) {
const char* lastSlash = strrchr(path, '/');
if (lastSlash != NULL) {
char* root = (char*)malloc(lastSlash - path + 2);
memcpy(root, path, lastSlash - path + 1);
root[lastSlash - path + 1] = '\0';
rootDir = root;
}
VM* vm = newVM();
const char* sourceCode = readFile(path);
executeModule(vm, OBJ_TO_VALUE(newObjString(vm, path, strlen(path))), sourceCode);
freeVM(vm);
}
脚本执行函数顺序梳理:
runFile(读取脚本源码)-> executeModule -> loadModule(返回创建新线程) -> compileModule(返回编译后的模块cu->fn) -> 循环执行compileProgram编译每一句代码。-> executeInstruction(执行线程框架的闭包中的指令流fn)
6.2 executeModule
//执行模块
VMResult executeModule(VM* vm, Value moduleName, const char* moduleCode) {
ObjThread* objThread = loadModule(vm, moduleName, moduleCode);
return executeInstruction(vm, objThread);
}
6.3 loadModule、getModule
//载入模块moduleName并编译
static ObjThread* loadModule(VM* vm, Value moduleName, const char* moduleCode) {
//确保模块已经载入到 vm->allModules
//先查看是否已经导入了该模块,避免重新导入
ObjModule* module = getModule(vm, moduleName);
//若该模块未加载先将其载入,并继承核心模块中的变量
if (module == NULL) {
//创建模块并添加到vm->allModules
ObjString* modName = VALUE_TO_OBJSTR(moduleName);
ASSERT(modName->value.start[modName->value.length] == '\0', "string.value.start is not terminated!");
module = newObjModule(vm, modName->value.start);
pushTmpRoot(vm, (ObjHeader*)module);
mapSet(vm, vm->allModules, moduleName, OBJ_TO_VALUE(module));
popTmpRoot(vm);
//继承核心模块中的变量
ObjModule* coreModule = getModule(vm, CORE_MODULE);
uint32_t idx = 0;
while (idx < coreModule->moduleVarName.count) {
defineModuleVar(vm, module,
coreModule->moduleVarName.datas[idx].str,
strlen(coreModule->moduleVarName.datas[idx].str),
coreModule->moduleVarValue.datas[idx]);
idx++;
}
}
ObjFn* fn = compileModule(vm, module, moduleCode);
pushTmpRoot(vm, (ObjHeader*)fn);
ObjClosure* objClosure = newObjClosure(vm, fn);
pushTmpRoot(vm, (ObjHeader*)objClosure);
ObjThread* moduleThread = newObjThread(vm, objClosure);
popTmpRoot(vm); // objClosure
popTmpRoot(vm); // fn
return moduleThread;
}
//从modules中获取名为moduleName的模块
static ObjModule* getModule(VM* vm, Value moduleName) {
Value value = mapGet(vm->allModules, moduleName);
if (value.type == VT_UNDEFINED) {
return NULL;
}
return (ObjModule*)(value.objHeader);
}
//新建线程
ObjThread* newObjThread(VM* vm, ObjClosure* objClosure) {
ASSERT(objClosure != NULL, "objClosure is NULL!");
Frame* frames = ALLOCATE_ARRAY(vm, Frame, INITIAL_FRAME_NUM);
//加1是为接收者的slot
uint32_t stackCapacity = ceilToPowerOf2(objClosure->fn->maxStackSlotUsedNum + 1);
Value* newStack = ALLOCATE_ARRAY(vm, Value, stackCapacity);
ObjThread* objThread = ALLOCATE(vm, ObjThread);
initObjHeader(vm, &objThread->objHeader, OT_THREAD, vm->threadClass);
objThread->frames = frames;
objThread->frameCapacity = INITIAL_FRAME_NUM;
objThread->stack = newStack;
objThread->stackCapacity = stackCapacity;
resetThread(objThread, objClosure);
return objThread;
}
//重置thread
void resetThread(ObjThread* objThread, ObjClosure* objClosure) {
objThread->esp = objThread->stack;
objThread->openUpvalues = NULL;
objThread->caller = NULL;
objThread->errorObj = VT_TO_VALUE(VT_NULL);
objThread->usedFrameNum = 0;
ASSERT(objClosure != NULL, "objClosure is NULL in function resetThread");
prepareFrame(objThread, objClosure, objThread->stack);
}
- 调用loadModule有两种情况,一种是runfile运行脚本文件,该脚本文件是一个模块,所以需要加载该模块,也就是继续编译该模块里的程序;第二种是识别到关键字import,从而调用编译模块。
- 编译完模块后得到模块的指令流fn,申请新函数闭包objClosure保存fn,再申请新线程newObjThread保存该函数闭包objClosure。
- 新线程的初始框架数为默认框架数,同时上述的闭包是该新线程的第一个函数闭包,所以直接prepareFrame。待调用executeInstruction中的LOAD_CUR_FRAME后就可直接执行该函数闭包的指令流。
6.4 compileModule
//编译模块
ObjFn* compileModule(VM* vm, ObjModule* objModule, const char* moduleCode) {
//各源码模块文件需要单独的parser
Parser parser;
parser.parent = vm->curParser;
vm->curParser = &parser;
if (objModule->name == NULL) {
// 核心模块是core.script.inc
initParser(vm, &parser, "core.script.inc", moduleCode, objModule);
} else {
initParser(vm, &parser,
(const char*)objModule->name->value.start, moduleCode, objModule);
}
CompileUnit moduleCU;
initCompileUnit(&parser, &moduleCU, NULL, false);
//记录现在模块变量的数量,后面检查预定义模块变量时可减少遍历
uint32_t moduleVarNumBefor = objModule->moduleVarValue.count;
//初始的parser->curToken.type为TOKEN_UNKNOWN,下面使其指向第一个合法的token
getNextToken(&parser);
//编译模块
while (!matchToken(&parser, TOKEN_EOF)) {
compileProgram(&moduleCU);
}
//模块编译完成,生成return null返回,避免执行下面endCompileUnit中添加的OPCODE_END
writeOpCode(&moduleCU, OPCODE_PUSH_NULL);
writeOpCode(&moduleCU, OPCODE_RETURN);
//检查在函数id中用行号声明的模块变量是否在引用之后有定义
uint32_t idx = moduleVarNumBefor;
while (idx < objModule->moduleVarValue.count) {
//为简单起见,依然是遇到第一个错后就报错退出,后面的不再检查
if (VALUE_IS_NUM(objModule->moduleVarValue.datas[idx])) {
char* str = objModule->moduleVarName.datas[idx].str;
ASSERT(str[objModule->moduleVarName.datas[idx].length] == '\0',
"module var name is not closed!");
uint32_t lineNo = VALUE_TO_NUM(objModule->moduleVarValue.datas[idx]);
COMPILE_ERROR(&parser, "line:%d, variable \'%s\' not defined!", lineNo, str);
}
idx++;
}
//模块编译完成,当前编译单元置空
vm->curParser->curCompileUnit = NULL;
vm->curParser = vm->curParser->parent;
#if DEBUG
return endCompileUnit(&moduleCU, "(script)", 8);
#else
return endCompileUnit(&moduleCU);
#endif
}
void initParser(VM* vm, Parser* parser, const char* file,
const char* sourceCode, ObjModule* objModule) {
parser->file = file;
parser->sourceCode = sourceCode;
parser->curChar = *parser->sourceCode;
parser->nextCharPtr = parser->sourceCode + 1;
parser->curToken.lineNo = 1;
parser->curToken.type = TOKEN_UNKNOWN;
parser->curToken.start = NULL;
parser->curToken.length = 0;
parser->preToken = parser->curToken;
parser->interpolationExpectRightParenNum = 0;
parser->vm = vm;
parser->curModule = objModule;
}
内部创建模块CU,接收了loadModule传入的objModule,编译模块生成指令流保存于cu->fn后,模块变量保存于objModule。initParser将objModule保存parser->curModule,initCompileUnit将parser保存于模块cu->curParser,endCompileUnit返回编译后的cu->fn,endCompileUnit会在自己父编译单元创建函数常量和父编译单元指令流中生成创建闭包指令,但是这里的脚本模块编译单元是第一个编辑单元,没有父编译单元,loadMoudle直接创建了新闭包。
事实上,编辑单元编译完成在cu->fn生成了指令流后,给编译单元创建闭包意味着收集本编译单元所有upvalue并保存到线程的objThread->openUpvalues,方便编译单元作用域退出后释放upvalue,释放已经结束作用域占用的运行时栈空间.而对于第一个运行的脚本模块,他自然也有局部变量,但是第一个脚本模块退出后,意味着操作系统为了执行这个脚本专门创建的进程也会被操作系统的进程管系统释放,所以第一个脚本模块占用的内存是不需要编译器释放的,自然也不需要为第一个脚本模块收集upvalue.
6.5 compileProgram
//编译程序
static void compileProgram(CompileUnit* cu) {
if (matchToken(cu->curParser, TOKEN_CLASS)) {
compileClassDefinition(cu);
} else if (matchToken(cu->curParser, TOKEN_FUN)) {
compileFunctionDefinition(cu);
} else if (matchToken(cu->curParser, TOKEN_VAR)) {
compileVarDefinition(cu, cu->curParser->preToken.type == TOKEN_STATIC);
} else if (matchToken(cu->curParser, TOKEN_IMPORT)) {
compileImport(cu);
} else {
compileStatment(cu);
}
}
6.6 executeInstruction
//执行指令
VMResult executeInstruction(VM* vm, register ObjThread* curThread) {
vm->curThread = curThread;
register Frame* curFrame;
register Value* stackStart;
register uint8_t* ip;
register ObjFn* fn;
OpCode opCode;
//定义操作运行时栈的宏
//esp是栈中下一个可写入数据的slot
#define PUSH(value) (*curThread->esp++ = value) //压栈
#define POP() (*(--curThread->esp)) //出栈
#define DROP() (curThread->esp--)
#define PEEK() (*(curThread->esp - 1)) // 获得栈顶的数据
#define PEEK2() (*(curThread->esp - 2)) // 获得次栈顶的数据
//下面是读取指令流:objfn.instrStream.datas
#define READ_BYTE() (*ip++) //从指令流中读取一字节
//读取指令流中的2字节
#define READ_SHORT() (ip += 2, (uint16_t)((ip[-2] << 8) | ip[-1]))
//当前指令单元执行的进度就是在指令流中的指针,即ip,将其保存起来
#define STORE_CUR_FRAME() curFrame->ip = ip // 备份ip以能回到当前
//加载最新的frame
#define LOAD_CUR_FRAME() \
/* frames是数组,索引从0起,故usedFrameNum-1 */ \
curFrame = &curThread->frames[curThread->usedFrameNum - 1]; \
stackStart = curFrame->stackStart; \
ip = curFrame->ip; \
fn = curFrame->closure->fn;
#define DECODE loopStart: \
opCode = READ_BYTE();\
switch (opCode)
#define CASE(shortOpCode) case OPCODE_##shortOpCode
#define LOOP() goto loopStart
LOAD_CUR_FRAME();
DECODE {
//若OPCODE依赖于指令环境(栈和指令流),会在各OPCODE下说明
CASE(LOAD_LOCAL_VAR):
......
......
LOOP();
CASE(xxx)
...
}
}
方法调用会切换框架执行框架对应的函数闭包,采用的就是
case MT_SCRIPT:
STORE_CUR_FRAME();
createFrame(vm, curThread, (ObjClosure*)method->obj, argNum);
LOAD_CUR_FRAME(); //加载最新的frame
break;
显然,在curThread-frames中,新框架就是老框架的下一个。
runfile -> loadModule -> compileModule
其中编译模块完成后,会newThread,此时线程的esp与线程的第usedFrameNum个(为0)可用框架的stackstart一致,也就是初始时栈顶栈底一致。
在executeInstruction时,有可能会涉及到方法调用,执行新方法意味着需要新框架,也就是上述的代码createFrame,注意,createFrame接受了一个参数argNum,也就是方法参数个数,新框架的运行时栈栈底stackstart指向了objThread->esp - argNum。这是因为在ip跳转到方法指令流(ObjClosure*)method->obj前,编译方法调用语句生成的指令中,有一个函数processArgList加载了方法实参(只要提到加载,就是push到线程运行时栈栈顶objThread->esp),而新框架的运行时栈栈底stackstart指向objThread->esp - argNum使得这些在运行时栈的实参正好定义(赋值)了编译方法的时候idMethodSignature对方法形参声明。也就是说,编译期间编译方法时遇到局部变量标识符,会从方法CU->localVar中寻找局部变量对应的索引index(虽然虚拟机执行指令的时候CU不会再使用,但是编译期间索引已经写入生成的指令了),而新框架的运行时栈栈底stackstart指向objThread->esp - argNum使得这些在运行时栈的实参正好可以对得上这些索引















 1051
1051











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









