







本文属于「数据库系统」系列文章之一,这一系列着重于「数据库系统知识的学习与实践」。由于文章内容随时可能发生更新变动,欢迎关注和收藏数据库系统系列文章汇总目录一文以作备忘。需要特别说明的是,为了透彻理解和全面掌握数据库系统,本系列文章中参考了诸多博客、教程、文档、书籍等资料,限于时间精力有限,这里无法一一列出。部分重要资料的不完全参考目录如下所示,在后续学习整理中还会逐渐补充:
- 数据库系统概念 第六版
Database System Concepts, Sixth Edition,作者是Abraham Silberschatz, Henry F. Korth, S. Sudarshan,机械工业出版社- 数据库系统概论 第五版,王珊 萨师煊编著,高等教育出版社
关系数据库应用数学方法来处理数据库中的数据。最早将这类方法用于数据处理的是1962年CODASYL发表的“信息代数”,之后有1968年David Child在IBM 7090机上实现的集合论数据结构,但是系统、严格地提出关系模型的是美国IBM公司的E. F. Codd。
1970年,E. F. Codd在美国计算机学会会刊 Communications of the ACM 上发表了题为 A Relational Model of Data for Shared Data Banks 的论文,开创了数据库系统的新纪元。1983年,ACM把这篇论文列为从1958年以来的四分之一世纪中,具有里程碑意义的25篇研究论文之一。此后,E. F. Codd连续发表了多篇论文,奠定了关系数据库的理论基础。
20世纪70年代末,关系方法的理论研究和软件系统的研制,均取得了丰硕的成果,IBM公司的San Jose实验室在IBM 370系列机上研制的关系数据库实验系统 System R ,历时6年获得成功。1981年,IBM公司又宣布了具有 System R 全部特征的、新的数据库软件产品 SQL/DS 问世。
与 System R 同期,美国加州大学伯克利分校也研制了 INGRES 关系数据库实验系统,并由 INGRES 公司发展成为 INGRES 数据库产品。
40多年来,关系数据库系统的研究和开发取得了辉煌的成就。关系数据库系统从实验室走向了社会,成为最重要、应用最广泛的数据库系统,大大促进了数据库应用领域的扩大和深入。因此,关系数据模型的原理、技术和应用十分重要,是数据库课程的重点。
简单地说,关系数据库系统就是支持关系(数据)模型的数据库系统。第一章初步介绍了关系模型及其基本术语,这里深入介绍关系模型。
按照数据模型的三个要素,关系模型由关系数据结构、关系操作集合和关系完整性约束三部分组成。下面分别介绍这三部分内容,2.1节讲解关系的形式化定义、关系数据结构的形式化定义及有关概念;2.2讲解关系操作;2.3讲解关系的三类完整性约束;2.4讲解关系代数,即关系数据库系统中实现关系操作的一种语言;最后,在2.5节介绍关系演算。
本章参考文献

2.1 关系数据结构及形式化定义
2.1.1 关系
关系模型的数据结构非常简单,只包含单一的数据结构——关系。在用户看来,关系模型中数据的逻辑结构是一张扁平的二维表。
关系模型的数据结构虽然简单,但能够表达丰富的语义,描述出现实世界的实体以及实体间的各种联系。也就是说,在关系模型中,现实世界的实体、实体间的各种联系,均用单一的结构类型,即关系来表示。
前面已经非形式地介绍了关系模型及有关的基本概念。关系模型是建立在集合代数的基础上的,这里从集合论角度,给出关系数据结构的形式化定义。
1. 域 domain
定义2.1 域是一组具有相同数据类型的值的集合,一个域允许的不同取值个数称为这个域的基数 cardinal number(集合的基数)。
例如,自然数、整数、实数、长度小于
25
25
25 字节的字符串集合,
{
0
,
1
}
\{0,1\}
{0,1} 等,都可以是域。
2. 笛卡尔积 cartesian product
笛卡尔积是域上的一种集合运算。
定义2.2 给定一组域
D
1
,
D
2
,
…
,
D
n
D_1, D_2, \dots, D_n
D1,D2,…,Dn ,允许其中某些域是相同的,
D
1
,
D
2
,
…
,
D
n
D_1, D_2, \dots, D_n
D1,D2,…,Dn 的笛卡尔积为:
D
1
×
D
2
×
⋯
×
D
n
=
{
(
d
1
,
d
2
,
…
,
d
n
)
∣
d
i
∈
D
i
,
i
=
1
,
2
,
…
,
n
}
D_1 \times D_2 \times \dots \times D_n = \{ (d_1, d_2, \dots, d_n) \mid d_i \in D_i, i = 1, 2, \dots, n \}
D1×D2×⋯×Dn={(d1,d2,…,dn)∣di∈Di,i=1,2,…,n} 其中,每个元素
(
d
1
,
d
2
,
…
,
d
n
)
(d_1, d_2, \dots, d_n)
(d1,d2,…,dn) 叫做一个
n
n
n 元组 n-tuple 或简称元组 tuple 。元素中的每个值
d
i
d_i
di 叫做一个分量 component 。
若 D i ( i = 1 , 2 , … , n ) D_i\ (i = 1, 2, \dots, n) Di (i=1,2,…,n) 为有限集合,其基数为 m i ( i = 1 , 2 , … , n ) m_i\ (i = 1, 2, \dots, n) mi (i=1,2,…,n) ,则 D 1 × D 2 × ⋯ × D n D_1 \times D_2 \times \dots \times D_n D1×D2×⋯×Dn 的基数 M M M 为: M = ∏ i = 1 n m i M = \prod^n_{i = 1}m_i M=i=1∏nmi
笛卡尔积可表示为一张二维表,表中的每行对应一个元组,表中的每列的值来自一个域。例如给出三个域:
D1 = 导师集合 SUPERVISOR = {张清玫,刘逸}D2 = 专业集合 SPECIALITY = {计算机专业,信息专业}D3 = 研究生集合 POSTGRADUATE = {李勇,刘晨,王敏}D1,D2,D3的笛卡尔积为
该笛卡尔积的基数为 2 × 2 × 3 = 12 2×2×3=12 2×2×3=12 。也就是说, D 1 × D 2 × D 3 D_1 \times D_2 \times D_3 D1×D2×D3 一共有 2 × 2 × 3 = 12 2 \times 2 \times 3 = 12 2×2×3=12 个元组,这些元组可列成一张二维表,如表2.1所示:D1 × D2 × D3= { (张清玫,计算机专业,李勇),(张清玫,计算机专业,刘晨), (张清玫,计算机专业,王敏),(张清玫,信息专业,李勇), (张清玫,信息专业,刘晨),(张清玫,信息专业,王敏), (刘逸,计算机专业,李勇),(刘逸,计算机专业,刘晨), (刘逸,计算机专业,王敏),(刘逸,信息专业,李勇), (刘逸,信息专业,刘晨),(刘逸,信息专业,王敏) }

3. 关系 relation
定义2.3
D
1
×
D
2
×
⋯
×
D
n
D_1 \times D_2 \times \dots \times D_n
D1×D2×⋯×Dn 的子集叫做在域
D
1
,
D
2
,
…
,
D
n
D_1, D_2, \dots, D_n
D1,D2,…,Dn 上的关系,表示为:
R
(
D
1
,
D
2
,
…
,
D
n
)
R(D_1, D_2, \dots, D_n)
R(D1,D2,…,Dn) 这里
R
R
R 表示关系的名字,
n
n
n 是关系的目或度 degree ——当
n
=
1
n = 1
n=1 时,称该关系为单元关系 unary relation 或一元关系;当
n
=
2
n = 2
n=2 时,称该关系为二元关系 binary relation 。关系中的每个元素是关系中的元组,通常用
t
t
t 表示。
关系是笛卡尔积的有限子集,笛卡尔积可表示为一张二维表,关系也可表示为一张二维表,表的每行对应一个元组(关系的元素),表的每列对应一个域。由于域可以相同,为了区分,必须对每列起一个名字,称为属性 attribute 。
n
n
n 目关系必有
n
n
n 个属性。
若关系中的某一属性组的值能唯一地标识一个元组,而其子集不能,则称该属性组为候选键 candidate key 。若一个关系有多个候选键,则选定其中一个为主键 primary key 。候选键的诸属性称为主属性,不包含在任何候选键中的属性称为非主属性 non-prime attribute 或非键属性 non-key attribute 。在最简单的情况下,候选键只包含一个属性;在最极端的情况下,关系模式的所有属性是这个关系模式的候选键,称为全键 all-key 。在第6章中,我们会在函数依赖和多值依赖的基础上,更加深入地讨论这些概念。
一般来说,
D
1
,
D
2
,
…
,
D
n
D_1, D_2, \dots, D_n
D1,D2,…,Dn 的笛卡尔积是没有实际语义的,只有它的某个真子集才有实际含义。例如,可以发现表2.1的笛卡尔积中许多元组是没有意义的。因为在学校中,一个专业方向有多个导师,而一个导师只在一个专业方向带研究生;一个导师可以带多名研究生,而一名研究生只有一个导师,学习某一个专业。因此,表2.1中的一个子集才是有意义的,才可以表示导师与研究生的关系,把该关系命名为 SAP ,如表2.2所示。李勇和刘晨是计算机专业张清玫老师的研究生;王敏是信息专业刘逸老师的研究生。

把关系 SAP 的属性名取为域名,即 SUPERVISOR, SPECIALITY, POSTGRADUATE ,则这个关系可以表示为:SAP(SUPERVISOR, SPECIALITY, POSTGRADUATE) 。假设研究生不会重名(这在实际生活中是不合适的,这里只是为了举例方便),则 POSTGRADUATE 属性的每个值都唯一地标识了一个元组,因此可作为 SAP 关系的主键。
关系可以有三种类型:基本关系(通常又称为基本表或基表)、查询表和视图表。其中,基本表是实际存在的表,它是实际存储数据的逻辑表示;查询表是查询结果对应的表;视图表是由基本表或其他视图导出的表,是虚表,不对应实际存储的数据。
按照定义2.2,关系可以是一个无限集合。由于组成笛卡尔积的域不满足交换律,所以按照数学定义, ( d 1 , d 2 , … , d n ) ≠ ( d 2 , d 1 , … , d n ) (d_1, d_2, \dots, d_n) \ne (d_2, d_1, \dots, d_n) (d1,d2,…,dn)=(d2,d1,…,dn)(说是元组,其实准确来说是 n n n 元序偶)。当关系作为关系数据模型的数据结构时,需要给予如下的限定和补充。
- 无限关系在数据库系统中是无意义的。因此,限定关系数据模型中的关系必须是有限集合。
- 通过为关系的每个列附加一个属性名的方法,取消关系属性的有序性,即 ( d 1 , d 2 , … , d i , d j , … , d n ) = ( d 1 , d 2 , … , d j , d i , … , d n ) ( i , j = 1 , 2 , … , n ) (d_1, d_2, \dots, d_i, d_j, \dots, d_n) = (d_1, d_2, \dots, d_j, d_i, \dots, d_n)\ (i,j = 1, 2, \dots, n) (d1,d2,…,di,dj,…,dn)=(d1,d2,…,dj,di,…,dn) (i,j=1,2,…,n) 。
因此,基本关系具有以下 6 6 6 条性质:
- 列是同质的
homogeneous,即每一列中的分量是同一类型的数据,来自同一个域。 - 不同的列可出自同一个域,称其中的每一列为一个属性,不同的属性要给予不同的属性名。例如,在上面的例子中,也可以只给出两个域:
人(PERSON) = {张清枚, 刘逸, 李勇, 刘晨, 王敏}, 专业(SPECIALITY) = {计算机专业, 信息专业}。
SAP关系的导师属性和研究生属性都从PERSON域中取值。为了避免混淆,必须给这两个属性取不同的属性名,而不能直接使用域名。例如,定义导师属性名为SUPERVISOR-PERSON,研究生属性名为POSTGRADUATE-PERSON。 - (命名属性名后)列的顺序无所谓,即列的次序可以任意交换。由于列顺序是无关紧要的,因此在许多实际关系数据库产品中,增加新属性时永远是插至最后一列。
- 任意两个元组的候选键不能取相同的值;
- 行的顺序无所谓,即行的次序可以任意交换;
- 分量必须取原子值,即每个分量都必须是不可分的数据项。关系模型要求关系必须是规范化
normalization的,即要求关系必须满足一定的规范条件。这些规范条件中最基本的一条就是,关系的每一个分量必须是一个不可分的数据项。规范化的关系简称为范式Normal Form, NF。范式的概念将在第6章关系数据理论中进一步讲解。
例如,表2.3虽然很好地表达了导师与研究生之间的一对多关系,但由于属性POSTGRADUATE中分量取了两个值,不符合规范化的要求,因此这样的关系在数据库中是不允许的。通俗地讲,关系表中不允许还有表,即不允许表中有表。直观地描述,表2.3中还有一个小表。

注意,许多实际关系数据库产品中,基本表并不完全具有这 6 6 6 条性质。例如,有的数据库产品仍然区分了属性顺序和元组顺序。许多时候,人们把元组称为记录,元组和记录是同一个概念。
2.1.2 关系模式
在数据库中要区分型和值。关系数据库中,关系模式是型,关系是值,关系模式是对关系的描述。那么一个关系需要描述哪些方面呢?关系是笛卡尔积的有限子集,是元组的集合,因此关系模式必须指出这个元组集合的结构,即它由哪些属性构成,这些属性来自哪些域,以及属性与域之间的映像关系。
现实世界随着时间在不断地变化,因而在不同的时刻,关系模式的关系也会有所变化。但是,现实世界的许多已有事实和规则限定了,关系模式所有可能的关系必须满足一定的完整性约束条件。这些约束条件或者通过对属性取值范围的限定,例如职工年龄小于 60 60 60 岁(之后退休),或者通过属性值间的相互关联反映出来,例如如果 2 2 2 个元组的主键相等,那么元组的其他值也一定相等,因为主键唯一标识一个元组,主键相等就表示这是同一个元组。关系模式应当刻画出这些完整性约束条件。
定义2.4 关系的描述称为关系模式 relation schema ,它可以形式化地表示为:
R
(
U
,
D
,
D
O
M
,
F
)
R(U, D, DOM, F)
R(U,D,DOM,F) 其中,
R
R
R 为关系名,
U
U
U 为组成该关系的属性名集合,
D
D
D 为
U
U
U 中属性所来自的域,
D
O
M
DOM
DOM 为属性向域的映像集合,
F
F
F 为「属性间数据的依赖关系」(将在第6章讨论,本章的关系模式只涉及关系名、各属性名、域名、属性向域的映像四部分)集合。
例如,在上面的例子中,由于导师和研究生出自同一个域——人,所以要取不同的属性名,并在模式中定义属性向域的映像,即说明它们分别出自哪个域,如:
DOM(SUPERVISOR) = DOM(POSTGRADUATE) = PERSON
\textrm{DOM(SUPERVISOR) = DOM(POSTGRADUATE) = PERSON}
DOM(SUPERVISOR) = DOM(POSTGRADUATE) = PERSON
关系模式通常可以简记为: R ( U ) R(U) R(U) 或 R ( A 1 , A 2 , … , A n ) R(A_1, A_2, \dots, A_n) R(A1,A2,…,An) 其中 R R R 为关系名, A 1 , A 2 , … , A n A_1, A_2, \dots, A_n A1,A2,…,An 为属性名。而域名、属性向域的映像常常直接说明为属性的类型、长度。
关系是关系模式在某一时刻的状态或内容。关系模式是静态的、稳定的,关系是动态的、随时间不断变化的,因为关系操作在不断地更新着数据库中的数据。例如,学生关系模式在不同的学年,学生关系是不同的。在实际工作中,人们常常把关系模式和关系都笼统称为关系,这不难从上下文加以区别。
2.1.3 关系数据库
在关系模型中,实体以及实体间的联系都是用关系来表示的。例如导师实体、研究生实体、导师与研究生之间的一对多联系,都可以用一个关系来表示。在一个给定的应用领域中,所有关系的集合构成一个关系数据库。
关系数据库也有型和值之分。关系数据库的型也称为关系数据库模式,是对关系数据库的描述,包括若干域的定义,以及在这些域上定义的若干关系模式。关系数据库的值是这些关系模式在某一时刻对应的关系的集合,通常就称为关系数据库。
2.1.4 关系模型的存储结构
在关系数据模型中,实体及实体间的联系都用(关系)表来表示,但表是关系数据的逻辑模型。在关系数据库的物理组织中,有的关系数据库管理系统中,一个表对应一个操作系统文件,将物理数据组织交给操作系统完成;有的关系数据库管理系统中,从操作系统那里申请若干个大的文件,自己划分文件空间,组织表、索引等存储结构,并进行存储管理。
2.2 关系操作
关系模型给出了关系操作的能力的说明,但不对关系数据库管理系统的语言给出具体的语法要求,也就是说,不同的关系DBMS可以定义和开发不同的语言,来实现这些操作。
2.2.1 基本的关系操作
关系模型中,常用的关系操作包括查询 query 操作和插入 insert 、删除 delete 、修改 update 操作两大部分。关系的查询表达能力很强,是关系操作中最主要的部分。查询操作又可以分为选择 select 、投影 project 、连接 join 、除 divide 、并 union 、差 except 、交 intersection 、笛卡尔积等,其中选择、投影、并、差、笛卡尔积是五种基本操作,其他操作可用基本操作来定义和导出,就像乘法可用加法来定义和导出一样。
关系操作的特点是集合操作方式,即操作的对象和结果都是集合。这种操作方式也称为一次一集合 set-at-a-time 。相应的,非关系数据模型的数据操作方式则为一次一记录 record-at-a-time 。
2.2.2 关系数据语言的分类
早期的关系操作能力,通常用代数方式或逻辑方式来表示,分别称为关系代数 relational algebra 和关系演算 relational calculus 。关系代数用对关系的运算来表达查询要求,关系演算则用谓词来表达查询要求。关系演算又可按谓词变元的基本对象是元组变量还是域变量,分为元组关系演算和域关系演算。一个关系数据语言能够表示关系代数可以表示的查询,称为具有完备的表达能力,简称关系完备性。已经证明,关系代数、元组关系演算、域关系演算三种语言在表达能力上是等价的,都具有完备的表达能力。
关系代数、元组关系演算和域关系演算均是抽象的查询语言,这些抽象的语言与具体的关系DBMS中实现的实际语言并不完全一样,但它们能用做评估实际系统中查询语言能力的标准或基础。实际的查询语言,除了提供关系代数或关系演算的基本功能外,还提供了许多附加功能,例如聚集函数 aggregation function 、关系赋值、算术运算等,使得目前实际查询语言的功能十分强大。
另外,还有一种介于关系代数和关系演算之间的结构化查询语言 structured query language, SQL,SQL不仅具有丰富的查询功能,而且具有数据定义和数据控制功能,是集查询、数据定义语言、数据操纵语言和数据控制语言 data control language, DCL 于一体的关系数据语言。它充分体现了关系数据语言的特点和优点,是关系数据库的标准语言。
因此,关系数据语言可以分为三类:
- 关系代数语言:ISBL
- 关系演算语言:
- 元组关系演算语言:ALPHA、QUEL
- 域关系演算语言:QBE
- 具有关系代数和关系演算双重特点的语言:SQL
特别地,SQL语言是一种高度非过程化的语言,用户不必请求数据库管理员为其建立特殊的存取路径,存取路径的选择由关系DBMS的优化机制来完成。例如,在一个存储有百万条记录的关系中,查找符合条件的某一个或某一些记录,从原理上讲可以有多种查找方法,例如,可以顺序扫描这个关系;可以通过某一种索引来查找。不同的查找路径(或称为存取路径)的效率是不同的,有的完成某个查询可能很快,有的可能极慢。关系DBMS中研究和开发了查询优化方法,系统可以自动选择较优的存取路径,提高查找效率。
2.3 关系的完整性
关系模型的完整性规则是对关系的某种约束条件。也就是说,关系的值随时间变化时应该满足一些约束条件。这些约束条件实际上是现实世界的要求。任何关系在任何时刻都要满足这些语义约束。
关系模型中有三类完整性约束:实体完整性 entity integrity 、参照完整性 referential integrity 、用户定义的完整性 user-defined integrity,其中实体完整性和参照完整性是关系模型必须满足的完整性约束条件,被称作关系的两个不变性,应该由关系系统自动支持。用户定义的完整性是应用领域需要遵循的约束条件,体现了具体领域中的语义约束。
2.3.1 实体完整性
关系数据库中每个元组应该是可区分的、唯一的。这样的约束条件用实体完整性来保证。
规则2.1 实体完整性规则 若属性(指一个或一组属性)
A
A
A 是基本关系
R
R
R 的主属性,则
A
A
A 不能取空值 null value 。所谓空值就是“不知道”或“不存在”或“无意义”的值。有关空值的处理,见【数据库系统】第一部分 数据库基础(3) 关系数据库标准语言SQL(6) 空值的处理。
例如,学生(学号, 姓名, 性别, 专业号, 年龄) 关系中,学号为主键,则学号不能取空值。
按照实体完整性规则的规定,如果主键由若干属性组成,则所有这些主属性都不能取空值。例如 选修(学号, 课程号, 成绩) 关系中,学号, 课程号为主键,则学号和课程号两个属性都不能取空值。
对于实体完整性规则的说明如下:
(1)实体完整性规则是针对基本关系而言的,一个基本表通常对应现实世界的一个实体集。例如学生管理对应于学生的集合。
(2)现实世界中的实体是可区分的,即它们具有某种唯一性标识。例如每个学生都是独立的个体,是不一样的。
(3)相应地,关系模型中以主键作为唯一性标识。
(4)主键中的属性即主属性不能取空值。如果主属性取空值,就说明存在某个不可标识的实体,即存在不可区分的实体,这与第(2)点相矛盾,因此这个规则称为实体完整性。
2.3.2 参照完整性
现实世界中的实体之间往往存在某种联系,在关系模型中实体及实体间的联系都是用关系来描述的,这样就自然存在着「关系与关系间的引用」。先看三个例子。
1. 关系间的引用
【例2.1】学生实体、专业实体可用下面的关系来表示,其中主键用下划线标识:
- 学生(学号,姓名,性别,专业号,年龄)
- 专业(专业号,专业名)
这两个关系之间存在着属性的引用,即学生关系引用了专业关系的主键“专业号”,显然,学生关系中的“专业号”值必须是确实存在的专业的专业号,即专业关系中有该专业的记录。也就是说,学生关系中的某个属性的取值,需要参照专业关系的属性取值。
【例2.2】学生、课程、学生与课程之间的多对多联系,可以用如下三个关系表示:
- 学生(学号,姓名,性别,专业号,年龄)
- 课程(课程号,课程名,学分)
- 选修(学号,课程号,成绩)
这三个关系之间也存在着属性的引用,即选修关系引用了学生关系的主键“学号”和课程关系的主键“课程号”。同样,选修关系中的“学号”值必须是确实存在的学生的学号,即学生关系中有该学生的记录;选修关系中的“课程号”值也必须是确实存在的课程的课程号,即课程关系中有该课程的记录。换句话说,选修关系中某些属性的取值需要参照其他关系的属性取值。
不仅两个或两个以上的关系间可以存在引用关系,同一关系内部属性间也可能存在引用关系。
【例2.3】 在学生(学号,姓名,性别,专业号,年龄,班长)关系中,“学号”属性是主键,“班长”属性表示该学生所在班级的班长的学号,它引用了本关系“学号”属性,即“班长”必须是确实存在的学生的学号。
这三个例子说明关系与关系之间存在着相互引用、相互约束的情况。下面先引入外键的概念,然后给出表达关系之间相互引用约束的参照完整性的定义。
2. 外码 foreign key
定义2.5 设
F
F
F 是基本关系
R
R
R 的一个或一组属性,但不是关系
R
R
R 的键。如果
F
F
F 与基本关系
S
S
S 的主键
K
s
K_s
Ks 相对应,则称
F
F
F 是
R
R
R 的外键 foreign key ,并称基本关系
R
R
R 为参照关系 referencing relation ,基本关系
S
S
S 为被参照关系 referenced relation 或目标关系 target relation 。关系
R
R
R 和
S
S
S 不一定是不同的关系。
显然,目标关系 S S S 的主键 K s K_s Ks 和参照关系 R R R 的外键 F F F 必须定义在同一个(或同一组)域上。
在【例2.1】中,学生关系的“专业号”属性与专业关系的主键“专业号”相对应,因此“专业号”属性是学生关系的外键。专业关系是被参照关系,学生关系为参照关系。如图所示:
 在【例2.2】中,选修关系的“学号”属性与学生关系的主键“学号”相对应,选修关系的“课程号”属性与课程关系的主键“课程号”相对应,因此,“学号”和“课程号”是选修关系的外键。这里,学生关系和课程关系均为被参照关系,选修关系为参照关系。如图所示:
在【例2.2】中,选修关系的“学号”属性与学生关系的主键“学号”相对应,选修关系的“课程号”属性与课程关系的主键“课程号”相对应,因此,“学号”和“课程号”是选修关系的外键。这里,学生关系和课程关系均为被参照关系,选修关系为参照关系。如图所示:

在【例2.3】中“班长”属性与本身的主键“学号”属性相对应,因此“班长”是外键。这里,学生关系既是参照关系也是被参照关系。如图所示:

需要指出的是,外键并不一定要与相应的主键同名,如【例2.3】中学生关系的主键为学号,外键为班长。不过,在实际应用中为了便于识别,当外键与相应的主键属于不同关系时,往往给它们取相同的名字。
参照完整性规则就是定义外键与主键之间的引用规则。
规则2.2 参照完整性规则 若属性(属性组) F F F 是基本关系 R R R 的外键,它与基本关系 S S S 的主键 K s K_s Ks 相对应(基本关系 R R R 和 S S S 不一定是不同的关系),则对于 R R R 中每个元组在 F F F 上的值必须:
- 或者取空值( F F F 的每个属性值均为空值);
- 或者等于 S S S 中某个元组的主键值
例如,对于【例2.1】,学生关系中每个元组的“专业号”属性只能取下面两类值:
(1)空值,表示尚未给该学生分配专业;
(2)非空值,这时该值必须是专业关系中某个元组的“专业号”值,表示该学生不可能分配到一个不存在的专业。即被参照关系“专业”中一定存在一个元组,它的主键值等于该参照关系“学生”中的外键值。
对于【例2.2】,按照参照完整性规则,“学号”和“课程号”属性也可以取两类值:空值或目标关系中已经存在的值。但由于“学号”和“课程号”是选修关系中的主属性,按照实体完整性规则,它们均不能取空值,所以选修关系中的“学号”和“课程号”属性,实际上只能取相应被参照关系中已经存在的主键值。
参照完整性规则中,
R
R
R 和
S
S
S 可以是同一个关系。例如对于【例2.3】,按照参照完整性规则,“班长”属性值可以取两类值:
(1)空值,表示该学生所在班级尚未选出班长;
(2)非空值,这时该值必须是本关系中某个元组的学号值。
2.3.3 用户定义的完整性
任何关系数据库系统都应该支持实体完整性和参照完整性,这是关系模型所要求的。除此之外,不同的关系数据库系统根据其应用环境的不同,往往还需要一些特殊的约束条件。用户定义的完整性,就是针对某一具体关系数据库的约束条件,它反映某一具体应用所涉及的数据必须满足的语义要求。例如某个属性必须取唯一值、某个非主属性不能取空值等。
举例,在【例2.1】的学生关系中,若按照应用的要求,则学生不能没有姓名,于是可以定义学生姓名不能取空值;某个属性如学生的成绩的取值范围,可以定义在 0 ∼ 100 0 \sim 100 0∼100 之间等。
关系模型应提供定义和检验这类完整性的机制,以便用统一的、系统的方法处理它们,而不需由应用程序承担这一功能。
在早期的关系数据库管理系统中,没有提供定义和检验这类完整性的机制,因此需要应用开发人员在应用系统的程序中进行检查。例如,在【例2.2】的选修关系中,每插入一条记录,必须在应用程序中写一段程序,来检查其中的学号是否等于学生关系中的某个学号,并检查其中的课程号是否等于课程关系中的某个课程号。如果等于,则插入这一条选修记录,否则就拒绝插入,并给出错误信息。
2.4 关系代数
关系代数是一种抽象的查询语言,它用「对关系的运算」来表达查询。了解基本的关系代数,是学习SQL的前提,也是深入学习数据库设计的前提。
任何一种运算都是将一定的运算符作用于一定的运算对象上,得到预期的运算结果,所以运算对象、运算符、运算结果是运算的三大要素。「对关系的运算」以(一个或多个)关系为运算对象,运算结果也是关系。关系代数用到的运算符则包括两类:集合运算符和专门的关系运算符,如表2.4所示:

关系代数的运算,按运算符的不同可分为传统的集合运算和专门的关系运算。其中,传统的集合运算将关系看做元组的集合,其运算是从关系的「水平」方向,即行的角度进行;而专门的关系运算不仅涉及行,而且涉及列。比较运算符和逻辑运算符是用来辅助专门的关系运算符进行操作的,基本的比较与逻辑运算符如下:
| 符号 | 含义 | LaTeX \LaTeX LATEX |
|---|---|---|
| < \lt < | 小于 | $\lt$ |
| ≤ \leq ≤ | 小于等于 | $\leq$ |
| > \gt > | 大于 | $\gt$ |
| ≥ \geq ≥ | 大于等于 | $\geq$ |
| = = = | 等于 | $=$ |
| ≠ \ne = | 不等于 | $\ne$ |
| ┐ \urcorner ┐ | 非 | $\lnot$ |
| ∧ \wedge ∧ | 与 | $\wedge$ |
| ∨ \vee ∨ | 或 | $\vee$ |
此外,关系代数还含有扩充的关系运算——广义投影、外连接、半连接、聚集等。
2.4.1 传统的集合运算 Union, Difference, Intersection, Cartesian Product
传统的集合运算是二目运算,包括并、差、交、广义笛卡尔积。其中前三者都要求,参与运算的两个关系必须是相容的同类关系,即它们必须有相同的列数,且对应的属性值取自同一个域(属性名可以不同),前三者运算的结果仍为同类 n n n 元关系。
设关系 R R R 和 S S S 为同类(同为 n n n 目,即两个关系都有 n n n 个属性,且相应属性取自同一个域)的 n n n 元关系, t t t 为元组变量, t ∈ R t \in R t∈R 表示 t t t 是 R R R 的一个元组。可以定义并、差、交、笛卡尔积运算如下:
- 并运算
union。关系 R R R 与 S S S 的并记作:
R ∪ S = { t ∣ ( t ∈ R ) ∨ ( t ∈ S ) } R∪S =\ \{ t\mid (t∈R) \lor (t∈S)\} R∪S= {t∣(t∈R)∨(t∈S)} 其结果由属于 R R R 或属于 S S S 的元组组成。注意:并运算不会重复出现相同的元组! - 差运算
except。关系 R R R 与 S S S 的差记作: R − S = { t ∣ ( t ∈ R ) ∧ ( t ∉ S ) } R-S=\ \{ t\ |\ (t∈R) \land (t \notin S)\} R−S= {t ∣ (t∈R)∧(t∈/S)}
其结果由属于 R R R 而不属于 S S S 的所有元组组成。 - 交运算
intersection。关系 R R R 与 S S S 的交记作:
R ∩ S = { t ∣ ( t ∈ R ) ∧ ( t ∈ S ) } R∩S=\ \{ t\ |\ (t∈R)\land (t∈S)\} R∩S= {t ∣ (t∈R)∧(t∈S)}
其结果由既属于 R R R 又属于 S S S 的元组组成。关系的交可用差来表示,即 R ∩ S = R − ( R − S ) R\cap S= R- (R - S) R∩S=R−(R−S) 上述三种运算的示例如下图:

- 笛卡尔积
cartesian product。这里的笛卡尔积严格地说应该是广义笛卡尔积extended cartesian product,因为这里笛卡尔积的元素是元组。
R R R 为 k 1 k_1 k1 元关系,有 n 1 n_1 n1 个元组; S S S 为 k 2 k_2 k2 元关系,有 n 2 n_2 n2 个元组。则广义笛卡尔积运算的结果关系为一个 k 1 + k 2 k_1+k_2 k1+k2 元的不同类新关系,有 n 1 × n 2 n_1 \times n_2 n1×n2 个元组。
R × S = { t r , t s ∣ ( t r ∈ R ) ∧ ( t s ∈ S ) } R \times S = \{\ t_r,\ t_s\ |\ (t_r \in R) \wedge (t_s \in S)\} R×S={ tr, ts ∣ (tr∈R)∧(ts∈S)} 显然, R , S R, S R,S 可以是不同类的关系,结果也是不同类关系。特别地,当需要得到一个关系 R R R 和自己的广义笛卡尔积时,必须引入 R R R 的别名(比如 R ′ R' R′ ),把表达式写成 R × R ′ R\times R' R×R′ 或者 R ′ × R R' \times R R′×R。运算中出现同名的属性也要同样区别,如果是两个不同的关系 R R R 和 S S S 中存在同名的属性 a 1 a_1 a1 时,可以写成 R . a 1 R.a_1 R.a1 与 S . a 1 S.a_1 S.a1 ,其他属性同样操作。

上述运算中,并、交、积运算均满足结合律,但差运算不满足结合律。其中,笛卡尔积运算是相当重要的,它是后面的条件连接、等值连接、自然连接的基础——连接中先做笛卡尔积,然后根据条件、等值来选择元组。自然连接在不存在公共属性时,结果就是笛卡尔积。同样,自然连接则是外连接、左外连接、右外连接的基础。这些都会在后面提到。?
2.4.2 专门的关系运算
专门的关系运算包括选择、投影、连接、除运算等。为了叙述的方便,先引入几个记号:
- 设关系模式为 R ( A 1 , A 2 , … , A n ) R(A_1,\ A_2,\ \dots,\ A_n) R(A1, A2, …, An) ,它的一个关系设为 R R R , t t t 为 R R R 的元组变量, t ∈ R t \in R t∈R 表示 t t t 是 R R R 的一个元组。 t [ A i ] t[A_i] t[Ai] 则表示元组 t t t 中、相应于属性 A i A_i Ai 的一个分量。
- 若
A
=
{
A
i
1
,
A
i
2
,
…
,
A
i
k
}
A = \{ A_{i1},\ A_{i2},\ \dots,\ A_{ik}\}
A={Ai1, Ai2, …, Aik} ,其中
A
i
1
,
A
i
2
,
…
,
A
i
k
A_{i1}, A_{i2}, \dots, A_{ik}
Ai1,Ai2,…,Aik 是
A
1
,
A
2
,
…
,
A
n
A_1, A_2, \dots, A_n
A1,A2,…,An 中的一部分,则
A
A
A 称为属性列或属性组。
t
[
A
]
=
(
t
[
A
i
1
]
,
t
[
A
i
2
]
,
…
,
t
[
A
i
k
]
)
t[A] = (t[A_{i1}],\ t[A_{i2}],\ \dots,\ t[A_{ik}])
t[A]=(t[Ai1], t[Ai2], …, t[Aik]) 则表示元组
t
t
t 在属性列或属性组
A
A
A 上诸分量的集合,
A
‾
\overline A
A 则表示
{
A
1
,
A
2
,
…
,
A
n
}
\{A_1,\ A_2,\ \dots,\ A_n\}
{A1, A2, …, An} 中去掉
{
A
i
1
,
A
i
2
,
…
,
A
i
k
}
\{ A_{i1},\ A_{i2},\ \dots,\ A_{ik}\}
{Ai1, Ai2, …, Aik} 后剩余的属性组。例如,
t
[
学
号
,
姓
名
]
t[学号, 姓名]
t[学号,姓名] 表示
R
R
R 在学号、姓名两列上的所有属性值。

-
R
R
R 为
n
n
n 目关系,
S
S
S 为
m
m
m 目关系。
t
r
∈
R
,
t
s
∈
S
t_r\in R,\ t_s \in S
tr∈R, ts∈S ,
t
r
t
s
⏠
\overgroup{t_rt_s}
trts
称为元组的连接
concatenation或元组的串接,它是一个 n + m n+m n+m 列的元组,前 n n n 个分量为 R R R 中的一个 n n n 元组,后 m m m 个分量为 S S S 中的一个 m m m 元组。 - 给定一个关系
R
(
X
,
Z
)
R(X, Z)
R(X,Z) ,
X
X
X 和
Z
Z
Z 为属性组。当
t
[
X
]
=
x
t[X] = x
t[X]=x 时,
x
x
x 在
R
R
R 中的象集
images set(象的集合)定义为: Z x = { t [ Z ] ∣ t ∈ R , t [ X ] = x } Z_x = \{ t[Z] \mid t \in R,\ t[X] = x \} Zx={t[Z]∣t∈R, t[X]=x} 它表示 R R R 中属性组 X X X 上值为 x x x 的诸元组,在 Z Z Z 上分量的集合。例如,图2.3中 x 1 x_1 x1 在 R R R 中的象集 Z x 1 = { Z 1 , Z 2 , Z 3 } Z_{x_1} = \{ Z_1, Z_2, Z_3\} Zx1={Z1,Z2,Z3} , x 2 x_2 x2 在 R R R 中的象集 Z x 2 = { Z 2 , Z 3 } Z_{x_2} = \{Z_2, Z_3 \} Zx2={Z2,Z3} , x 3 x_3 x3 在 R R R 中的象集 Z x 3 = { Z 1 , Z 3 } Z_{x_3} = \{ Z_1, Z_3\} Zx3={Z1,Z3} 。

1. 选择运算 selection

选择运算又称为限制 restriction ,它是在关系的行上进行的横向筛选,选择出满足给定条件的诸元组,结果产生同类关系。设
t
t
t 为
R
R
R 的元组变量,选择运算记作:
σ
F
(
R
)
=
{
t
∣
(
t
∈
R
)
∧
F
(
t
)
=
t
r
u
e
}
\sigma_F(R) = \{\ t\ |\ (t \in R) \wedge F(t) = true\}
σF(R)={ t ∣ (t∈R)∧F(t)=true}
含义:
σ
F
(
R
)
\sigma_F(R)
σF(R) 表示从关系
R
R
R 中选出的、满足
F
F
F 条件表达式的那些元组所构成的关系。其中,选择条件
F
F
F 是「由属性名(或列号)、比较符、逻辑运算符构成的逻辑表达式」,取逻辑值“真”或“假”。
F
F
F 的基本形式为:
X
1
θ
Y
1
X_1 \theta Y_1
X1θY1
θ
\theta
θ 表示比较运算符;
X
1
,
Y
1
X_1, Y_1
X1,Y1 等是属性名,或为常量或为简单函数,属性名也可以用它的序号来代替。在基本的选择条件上,可以进一步进行逻辑运算,即进行求非、与、或运算。
一个示例是,
σ
A
2
>
5
∨
A
3
≠
“
f
”
(
R
)
σ_{A2\ >\ 5\ ∨\ A3\ ≠\ “f”} (R)
σA2 > 5 ∨ A3 = “f”(R) 或
σ
[
2
]
>
5
∨
[
3
]
≠
“
f
”
(
R
)
σ_{[2]\ >\ 5\ ∨\ [3]\ ≠\ “f”}(R)
σ[2] > 5 ∨ [3] = “f”(R) ,对下面的图来说,打勾的四行满足条件,会被选择出来构成新关系。

设有一个学生-课程数据库,包括学生关系 Student 、课程关系 Course 和选修关系 SC 。如图2.4所示,下面的多个例子将对这三个关系进行运算:



【例2.4】查询信息系(IS 系)的全体学生。
答:
σ
S
d
e
p
t
=
′
I
S
′
(
S
t
u
d
e
n
t
)
\sigma_{Sdept = 'IS' } (Student)
σSdept=′IS′(Student) 。结果如图所示:

【例2.5】查询年龄小于
20
20
20 岁的学生。
答:
σ
S
a
g
e
<
20
(
S
t
u
d
e
n
t
)
\sigma_{Sage < 20} (Student)
σSage<20(Student) 。结果如图所示:

2. 投影运算 projection

投影是在关系的列上进行的纵向筛选,选择出若干属性列组成新的关系,结果产生不同类关系,只有被选中的几列可能构成新的关系。设
t
t
t 为
R
R
R 的元组变量,投影运算记作:
∏
A
(
R
)
=
{
t
[
A
]
∣
(
t
∈
R
)
}
\prod {}_A(R) = \{\ t[A]\ |\ (t \in R)\ \}
∏A(R)={ t[A] ∣ (t∈R) } 含义:
∏
A
(
R
)
\prod {}_A(R)
∏A(R) 表示从关系
R
R
R 中取出
A
A
A 属性指定的列,并消除重复的元组。这里的
A
A
A 属性可以有多个。一个示例是
∏
A
2
,
A
3
(
R
)
\prod _{A2,A3}(R)
∏A2,A3(R),结果如下:

显然,投影之后不仅取消了原关系中的某些列,而且还可能取消某些元组,因为取消了某些属性列后,就可能出现重复行,应取消这些完全相同的行。
【例】对下面的学生选课表,用关系代数进行查询。

(1)查选
2
2
2 号课程的学生记录。答:
σ
[
2
]
=
=
′
2
′
(
S
C
)
\sigma _{[2] == '2'}(SC)
σ[2]==′2′(SC)
(2)成绩在
90
90
90 分及以上的学生号。答:
∏
S
n
o
(
σ
G
r
a
d
e
≥
90
(
S
C
)
)
\prod _{Sno}(\sigma_{Grade\ \ge\ 90}(SC))
∏Sno(σGrade ≥ 90(SC))
【例2.6】查询学生的姓名和所在系。即求 Student 关系上学生姓名和所在系两个属性上的投影
答:
∏
S
n
a
m
e
,
S
d
e
p
t
(
S
t
u
d
e
n
t
)
\prod_{Sname,Sdept}(Student)
∏Sname,Sdept(Student) 。结果如下图所示。

【例2.7】查询学生关系 Student 中都有哪些系。
答:
∏
S
d
e
p
t
(
S
t
u
d
e
n
t
)
\prod_{Sdept}(Student)
∏Sdept(Student) 。结果如下图所示,Student 关系原来有四个元组,而投影结果取消了重复的 CS 元组,因此只有三个元组。

3. 连接运算 join
连接运算也被称为
θ
\theta
θ 连接,它是从两个关系的笛卡尔积中选择「属性间满足一定条件的元组」。
R
⋈
A
θ
B
S
=
{
t
r
t
s
⏠
∣
(
t
r
∈
R
)
∧
(
t
s
∈
S
)
∧
(
t
r
[
A
]
θ
t
s
[
B
]
)
}
R\mathop{\Join} \limits_{A \theta B} S = \{\ \overgroup{t_r t_s} \ |\ (t_r \in R) \wedge (t_s \in S) \wedge (t_r[A]\ \theta\ t_s[B])\ \}
RAθB⋈S={ trts
∣ (tr∈R)∧(ts∈S)∧(tr[A] θ ts[B]) } 其中,
A
A
A 和
B
B
B 分别为
R
R
R 和
S
S
S 上列数相等且可比的属性组,
θ
\theta
θ 是比较运算符。连接运算从
R
R
R 和
S
S
S 的笛卡尔积
R
×
S
R\times S
R×S 中,选取「
R
R
R 关系在
A
A
A 属性组上的值」与「
S
S
S 关系在
B
B
B 属性组上的值」满足「比较关系
θ
\theta
θ」的元组,构成一个新关系。上式可以用其他关系代数式表示为:
R
⋈
A
θ
B
S
=
σ
R
.
A
θ
S
.
B
(
R
×
S
)
R\mathop{\Join} \limits_{A \theta B} S = \sigma _{R.A\ \theta\ S.B}\ (R \times S)
RAθB⋈S=σR.A θ S.B (R×S) 除了上面的一般条件连接外,连接运算中有两种最为重要也最为常用的连接,一种是等值连接 equijoin ,另一种是自然连接 natural join 。
θ
\theta
θ 为
=
=
= 的连接运算称为等值连接,它是从关系
R
R
R 与
S
S
S 的广义笛卡尔积中选取
A
,
B
A, B
A,B 属性值相等的那些元组,即等值连接为:
R
⋈
A
=
B
S
=
{
t
r
t
s
⏠
∣
(
t
r
∈
R
)
∧
(
t
s
∈
S
)
∧
(
t
r
[
A
]
=
t
s
[
B
]
)
}
R\mathop{\Join}\limits_{A=B} S = \{ \overgroup {\ t_r t_s} \mid (t_r \in R) \land (t_s \in S) \land (t_r[A] = t_s[B])\ \}
RA=B⋈S={ trts
∣(tr∈R)∧(ts∈S)∧(tr[A]=ts[B]) }
自然连接是一种特殊的等值连接。它要求两个关系中进行比较的分量必须是「同名的属性组」,并在结果中把重复的属性列去掉。即若
R
R
R 和
S
S
S 中具有相同的属性组
B
B
B ,
U
U
U 为
R
R
R 和
S
S
S 的全体属性集合,则自然连接可记作:
R
⋈
S
=
{
t
r
t
s
⏠
[
U
−
B
]
∣
(
t
r
∈
R
)
∧
(
t
s
∈
S
)
∧
(
t
r
[
B
]
=
t
s
[
B
]
)
}
R \mathop{\Join} S = \{\ \overgroup{t_rt_s} [U - B] \mid (t_r \in R)\land (t_s \in S) \land (t_r[B] = t_s[B])\ \}
R⋈S={ trts
[U−B]∣(tr∈R)∧(ts∈S)∧(tr[B]=ts[B]) } 一般的连接操作是从行的角度进行运算,但自然连接还需要取消重复列,所以是同时从行和列的角度进行运算。

【例2.28】
(1). 等值连接
即
θ
\theta
θ 关系为
=
=
= 的连接,可以用其他关系代数式表示为:
R
⋈
A
=
B
S
=
σ
R
.
A
=
S
.
B
(
R
×
S
)
R \Join _{A\ =\ B} S = \sigma_{R.A = S.B}\ (R \times S)
R⋈A = BS=σR.A=S.B (R×S)
(2). 自然连接Natural Join
这是一种特殊的等值连接,要求两个关系中进行比较的分量是公共的属性组,并且要去掉重复的属性!若
R
R
R 和
S
S
S 具有相同的属性组
B
B
B,则自然连接记作:
R ⋈ S = { t r , t s ⏞ ∣ ( t r ∈ R ) ∧ ( t s ∈ S ) ∧ ( t r [ B ] = t s [ B ] ) R \Join S = \{\overbrace {t_r, t_s}\ |\ (t_r \in R) \wedge (t_s \in S) \wedge (t_r[B] = t_s[B]) R⋈S={tr,ts ∣ (tr∈R)∧(ts∈S)∧(tr[B]=ts[B])
自然连接可以用其他关系代数式表示,设
R
R
R,
S
S
S 有同名属性
B
i
(
i
=
1
,
2
,
.
.
.
,
k
)
B_i\ (i = 1, 2,..., k)
Bi (i=1,2,...,k),有:
R
⋈
S
=
∏
无
重
复
属
性
名
者
(
θ
R
.
B
1
=
S
.
B
1
∧
.
.
.
∧
R
.
B
k
=
S
.
B
k
(
R
×
S
)
)
R \Join S = \prod_{无重复属性名者}\ (\theta _{R.B_1 = S.B_1\ \wedge\ ...\ \wedge\ R.B_k = S.B_k}\ (R \times S))
R⋈S=无重复属性名者∏ (θR.B1=S.B1 ∧ ... ∧ R.Bk=S.Bk (R×S))
比起一般的等值连接,自然连接有特殊要求:
R
R
R、
S
S
S 有同名属性,其连接结果:满足 同名属性 值也对应相同,并且 去掉重复属性后 的连接元组集合。自然连接的运算步骤可分解为:
1.
1.
1. 计算
R
×
S
R\times S
R×S;
2.
2.
2. 选择满足等值条件
R
.
B
1
=
S
.
B
1
∧
.
.
.
∧
R
.
B
k
=
S
.
B
k
R.B_1 = S.B_1 \wedge\ ...\ \wedge R.B_k = S.B_k
R.B1=S.B1∧ ... ∧R.Bk=S.Bk 的元组;
3.
3.
3. 去掉重复属性
S
.
B
1
,
.
.
.
,
S
.
B
k
S.B_1, ...\ , S.B_k
S.B1,... ,S.Bk。
如果 R R R, S S S 无公共属性,则 R ⋈ S = R × S R \Join S = R\times S R⋈S=R×S。
等值连接与自然连接的区别:
(1)自然连接一定是等值连接,但等值连接不一定是自然连接。因为自然连接要求相等的分量必须是公共属性,而等值连接相等的分量不一定是公共属性。
(2)等值连接不要求把重复的属性去掉,而自然连接要把重复属性去掉。
例子:已知有图所示的关系
R
R
R,
S
S
S如下:

其笛卡尔积
R
×
S
R \times S
R×S 为:

(1)条件连接
R
⋈
[
2
]
>
[
1
]
S
R \Join_{[2] \gt [1]} S
R⋈[2]>[1]S 示例,运算结果如下:

(2)等值连接
R
⋈
[
2
]
=
[
1
]
S
R\Join _{[2] = [1]} S
R⋈[2]=[1]S 运算结果如下:

(3)自然连接
R
⋈
S
R \Join S
R⋈S 运算结果如下:

4. 除法运算Divide
设关系
R
(
X
,
Y
)
R(X,Y)
R(X,Y) 与
S
(
Y
,
Z
)
S(Y, Z)
S(Y,Z),
X
,
Y
,
Z
X,Y,Z
X,Y,Z 为属性 组,
X
X
X 属性组上的值为
x
i
x_i
xi,除法运算记作:
R
÷
S
=
{
t
[
X
]
∣
t
∈
R
∧
∏
Y
(
S
)
⊆
Y
X
}
R \div S = \{\ t[X]\ |\ t \in R \wedge \prod {}_Y(S) \subseteq Y_X\}
R÷S={ t[X] ∣ t∈R∧∏Y(S)⊆YX}
分解
R
÷
S
R\div S
R÷S 的步骤如下:
1.
1.
1. 求
∏
X
(
R
)
\prod {}_X(R)
∏X(R);
2.
2.
2. 求
∏
Y
(
S
)
\prod{}_Y(S)
∏Y(S);
3.
3.
3.
Y
X
Y_X
YX 为
X
X
X 在
R
R
R 中的像集(Image Set),它表示
R
R
R 中属性组上
X
X
X 值为
x
i
x_i
xi 的各个元组在
Y
Y
Y 上的分量集合,每个
x
i
x_i
xi 都有一个
Y
Y
Y 的分量集合;求像集
Y
X
Y_X
YX 的方法:对于每个值
x
i
∈
∏
X
(
R
)
x_i \in \prod {}_X(R)
xi∈∏X(R),求出
∏
Y
(
σ
X
=
x
i
(
R
)
)
\prod {}_Y(\sigma _{X = x_i}(R))
∏Y(σX=xi(R));
4.
4.
4.
R
÷
S
R \div S
R÷S 运算结果为:像集
Y
X
Y_X
YX 包含了
∏
Y
(
S
)
\prod {}_Y(S)
∏Y(S) 的所有
x
i
x_i
xi。
例:设关系
R
(
A
,
B
,
C
)
,
S
(
B
,
C
,
D
)
R(A,B,C), S(B,C,D)
R(A,B,C),S(B,C,D),如下图所示,求
R
÷
S
R\div S
R÷S 的结果。

1.
1.
1. 求
∏
X
(
R
)
\prod {}_X(R)
∏X(R),易知:
∏
X
(
R
)
=
{
a
1
,
a
2
,
a
3
,
a
4
}
\prod {}_X(R) = \{a_1, a_2, a_3, a_4\}
∏X(R)={a1,a2,a3,a4},即在关系
R
R
R 中,
A
A
A 可以取
4
4
4 个值
{
a
1
,
a
2
,
a
3
,
a
4
}
\{a_1, a_2, a_3, a_4\}
{a1,a2,a3,a4};
2.
2.
2. 求
∏
Y
(
S
)
\prod {}_Y(S)
∏Y(S),易知:
∏
Y
(
S
)
=
{
(
b
1
,
c
2
)
,
(
b
2
,
c
1
)
,
(
b
2
,
c
3
)
}
\prod {}_Y(S) = \{(b_1,c_2),(b_2,c_1), (b_2,c_3)\}
∏Y(S)={(b1,c2),(b2,c1),(b2,c3)};
3.
3.
3. 求
x
i
x_i
xi 或者说
a
i
,
1
≤
i
≤
4
a_i, 1 \le i \le 4
ai,1≤i≤4 在
R
R
R 中的像集
Y
X
Y_X
YX,对每个
x
i
∈
∏
X
(
R
)
x_i \in \prod{}_X(R)
xi∈∏X(R),求
∏
Y
(
σ
X
=
x
i
(
R
)
)
\prod {}_Y(\sigma _{X = x_i}(R))
∏Y(σX=xi(R)):
-
x
1
=
a
1
x_1 = a_1
x1=a1,
σ
x
1
=
a
1
(
R
)
\sigma _{x_1=a_1}(R)
σx1=a1(R)如下:

可得在 R R R 中的像集: ∏ Y ( σ x 1 = a 1 ( R ) ) = { { b 1 , c 2 } , { b 2 , c 3 } , { b 2 , c 1 } } \prod {}_Y(\sigma _{x_1=a_1}(R)) = \{\{b_1,c_2\},\{b_2,c_3\},\{b_2,c_1\}\} ∏Y(σx1=a1(R))={{b1,c2},{b2,c3},{b2,c1}} - ∏ Y ( σ x 2 = a 2 ( R ) ) = { { b 3 , c 7 } , { b 2 , c 3 } } \prod {}_Y(\sigma _{x_2=a_2}(R)) = \{\{b_3,c_7\},\{b_2,c_3\}\} ∏Y(σx2=a2(R))={{b3,c7},{b2,c3}}
- ∏ Y ( σ x 3 = a 3 ( R ) ) = { { b 4 , c 6 } } \prod {}_Y(\sigma _{x_3=a_3}(R)) = \{\{b_4,c_6\}\} ∏Y(σx3=a3(R))={{b4,c6}}
- ∏ Y ( σ x 4 = a 4 ( R ) ) = { { b 6 , c 6 } } \prod {}_Y(\sigma _{x_4=a_4}(R)) = \{\{b_6,c_6\}\} ∏Y(σx4=a4(R))={{b6,c6}}
4. 4. 4. 求出像集 B C a i BC_{a_i} BCai 或者说 Y X Y_X YX 中包含了 ∏ Y ( S ) \prod {}_Y(S) ∏Y(S) 的 a i a_i ai,显然,只有 a i a_i ai 在 R R R 中的像集 包含了所有 ∏ Y ( S ) = ∏ B , C ( S ) \prod {}_Y(S) = \prod {}_{B,C}(S) ∏Y(S)=∏B,C(S) ,则 R ÷ S = { a 1 } R\div S = \{a_1\} R÷S={a1}。
关系代数定义了除法运算。但是实际运用中,当关系 R R R 真包含了关系 S S S 时, R ÷ S R\div S R÷S 才有意义。 R R R 能够被 S S S 除尽的充分必要条件是: R R R 中的属性包含 S S S 中的所有属性; R R R 中有一些属性不出现在 S S S 中。
R = ( X , Y ) , S = ( Y ) R = (X,Y), S = (Y) R=(X,Y),S=(Y): 可以这样理解 R ÷ S R \div S R÷S,即 R R R 中包含了 S S S 中全部属性值的那些元组,在 R R R 与 S S S 的属性名集合之差 R − S R - S R−S 即 X X X 上的投影。
2.5 关系演算
关系演算是以数理逻辑中的谓词演算为基础的,按谓词变元的不同,关系演算分为元组关系演算和域关系演算。这里先计算元组关系演算,再简单介绍域关系演算。
2.5.1 元组关系演算语言ALPHA
5. 实际练习【重点】
设一学生选课关系数据库,见下表,在
3
3
3 个关系中,除学号、年龄、学分、成绩属性的值为整型数外,其余均为字符串型。
s
t
u
d
e
n
t
(
s
n
o
,
s
n
a
m
e
,
s
e
x
,
a
g
e
,
d
e
p
t
,
p
l
a
c
e
)
c
o
u
r
s
e
(
c
n
o
,
c
n
a
m
e
,
c
r
e
d
i
t
,
p
c
n
o
)
s
c
(
s
n
o
,
c
n
o
,
g
r
a
d
e
)
\begin{aligned} &student(sno,sname,sex,age,dept,place)\\ &course(cno,cname, credit , pcno)\\ &sc(sno,cno,grade) \end{aligned}
student(sno,sname,sex,age,dept,place)course(cno,cname,credit,pcno)sc(sno,cno,grade)


(1)求年龄在
25
25
25 岁以下的女学生:
σ
a
g
e
<
25
∧
s
e
x
=
′
女
′
(
S
)
\sigma _{age\ <\ 25\ \wedge\ sex='女'}(S)
σage < 25 ∧ sex=′女′(S)
(2)求成绩在
85
85
85 分及以上的学生的学号和姓名:
∏
s
n
o
,
s
n
a
m
e
(
σ
g
r
a
d
e
>
85
(
s
t
u
d
e
n
t
⋈
s
c
)
)
\prod {}_{sno, sname}(\sigma _{grade\ >\ 85}(student \Join sc))
∏sno,sname(σgrade > 85(student⋈sc))
公共属性是
s
n
o
sno
sno。
(3)查询至少选修了一门其 直接先修课为
003
003
003 号课程 的课程的学生姓名。由于涉及到了先修课程号、学生姓名,必然涉及到course表,以及student表,还需要sc表。多表查询,需要自然连接。
∏
s
n
a
m
e
(
σ
p
c
n
o
=
′
00
3
′
(
s
t
u
d
e
n
t
⋈
s
c
⋈
c
o
u
r
s
e
)
)
\prod {}_{sname}(\sigma _{pcno='003'}(student \Join sc \Join course))
∏sname(σpcno=′003′(student⋈sc⋈course))
可以进一步优化,对于有选择运算的,优先进行选择,以减少笛卡尔积的规模;选择完毕后可以适当增加投影,投影那些后面的自然连接会用到的公共属性,和那些要求的属性。
∏
s
n
a
m
e
(
∏
s
n
o
,
n
a
m
e
(
s
t
u
d
e
n
t
)
⋈
s
c
⋈
∏
c
n
o
(
σ
p
c
n
o
=
′
00
3
′
(
c
o
u
r
s
e
)
)
\prod {}_{sname}(\prod {}_{sno,name}(student) \Join sc \Join \prod {}_{cno}(\sigma _{pcno='003'}(course))
∏sname(∏sno,name(student)⋈sc⋈∏cno(σpcno=′003′(course))
(4)求选修数据库课程的学生的姓名和成绩。
∏
s
n
a
m
e
,
g
r
a
d
e
(
σ
c
n
a
m
e
=
′
数
据
库
′
(
s
t
u
d
e
n
t
⋈
s
c
⋈
c
o
u
r
s
e
)
)
\prod {}_{sname, grade}(\sigma _{cname='数据库'}(student \Join sc \Join course))
∏sname,grade(σcname=′数据库′(student⋈sc⋈course))
同样可以进行优化:
∏
s
n
a
m
e
,
g
r
a
d
e
(
∏
s
n
o
,
s
n
a
m
e
(
s
t
u
d
e
n
t
)
⋈
s
c
⋈
∏
c
n
o
(
σ
c
n
a
m
e
=
′
数
据
库
′
(
c
o
u
r
s
e
)
)
)
\prod {}_{sname, grade}(\prod {}_{sno, sname}(student) \Join sc \Join \prod {}_{cno}(\sigma _{cname='数据库'}(course)))
∏sname,grade(∏sno,sname(student)⋈sc⋈∏cno(σcname=′数据库′(course)))
(5)查询没有选择
005
005
005 号课程的学生的学号。
下面的式子是错误的!
∏
s
n
o
(
σ
c
n
o
≠
′
00
5
′
(
S
C
)
)
\prod{}_{sno}(\sigma _{cno \ne '005'}(SC))
∏sno(σcno=′005′(SC))
因为这样是从 选了课程 的学生中进行查找,没有考虑到那些没选课的学生;而且,这样做也会输出那些 选了005号课程但也选了其他课程的学生。因此是大错特错的!
我们应该先找到选了005号课程的学生,然后从所有学生中减去这部分学生。
∏
c
n
o
(
s
t
u
d
e
n
t
)
−
∏
c
n
o
(
σ
c
n
o
=
′
00
5
′
(
S
C
)
)
\prod {}_{cno}(student) - \prod {}_{cno}(\sigma _{cno = '005'}(SC))
∏cno(student)−∏cno(σcno=′005′(SC))
(6)查询没有选择
005
005
005 号课程的学生姓名与年龄。
同上:
∏
s
n
a
m
e
,
a
g
e
(
s
t
u
d
e
n
t
)
−
∏
s
n
a
m
e
,
a
g
e
(
s
t
u
d
e
n
t
⋈
σ
c
n
o
=
′
00
5
′
(
S
C
)
)
\prod {}_{sname,age}(student) - \prod {}_{sname, age}(student \Join \sigma _{cno = '005'}(SC))
∏sname,age(student)−∏sname,age(student⋈σcno=′005′(SC))
(7)查询选择了全部课程的学生的姓名和学号。
这个怎样做呢?需要用除法,用学生选课表
÷
\div
÷ 课程表,得到选修了全部课程的学生的学号。然后用得到的学号和学生表进行自然连接。
∏
s
n
o
,
c
n
o
(
s
c
)
÷
∏
c
n
o
(
c
o
u
r
s
e
)
⋈
∏
s
n
a
m
e
,
s
n
o
(
s
t
u
d
e
n
t
)
\prod {}_{sno,cno}(sc) \div \prod {}_{cno}(course) \Join \prod {}_{sname, sno}(student)
∏sno,cno(sc)÷∏cno(course)⋈∏sname,sno(student)
(8)查询至少选择了两门课程的学生学号。
这个题目更麻烦了,需要用差运算,用全部的学生学号-没有选的-选了一门的学生学号。其实简单的想,可以用自己与自己进行笛卡尔积,这里用列号进行区分。
∏
[
1
]
(
σ
[
1
]
=
[
4
]
∧
[
2
]
≠
[
5
]
(
s
c
×
s
c
)
)
\prod {}_{[1]} (\sigma _{[1] = [4]\ \wedge\ [2] \ne [5]} (sc \times sc))
∏[1](σ[1]=[4] ∧ [2]=[5](sc×sc))
6. 关系代数基本运算总结【重点】
关系代数基本运算是五种:交,差,笛卡尔积,投影,选择:
- 投影: ∏ A 1 , A 2 , . . . , A k ( R ) \prod {}_{A_1,A_2,...,A_k}(R) ∏A1,A2,...,Ak(R) 实现关系属性列的指定;
- 选择: σ F ( R ) \sigma _{F}(R) σF(R) 实现关系行的选择;
- 并: R ∪ S R \cup S R∪S 实现两个关系的合并或者说关系中元组(行)的插入;
- 差: R − S R - S R−S 实现关系中元组(行)的删除;
- 积: R × S R \times S R×S 实现两个关系的无条件全连接。
非基本运算可以用基本运算来表示:
- 交: R ∩ S = R − ( R − S ) R \cap S = R - (R - S) R∩S=R−(R−S);
- 条件连接: R ⋈ i θ j = σ [ i ] θ [ m + j ] ( R × S ) R \Join_{i\ \theta\ j} = \sigma_{[i]\ \theta\ [m + j]} (R \times S) R⋈i θ j=σ[i] θ [m+j](R×S)
- 等值连接: R ⋈ A = B S = σ R . A = S . B ( R × S ) R \Join _{A\ =\ B} S = \sigma_{R.A = S.B}\ (R \times S) R⋈A = BS=σR.A=S.B (R×S)
- 自然连接: R ⋈ S = ∏ A 1 , A 2 , . . . , A k ( σ R . B 1 = S . B 1 ∧ . . . ∧ R . B k = S . B k ( R × S ) ) R \Join S = \prod_{A_1,A_2,...,A_k}\ (\sigma _{R.B_1 = S.B_1\ \wedge\ ...\ \wedge\ R.B_k = S.B_k}\ (R \times S)) R⋈S=∏A1,A2,...,Ak (σR.B1=S.B1 ∧ ... ∧ R.Bk=S.Bk (R×S)),其中 B 1 , B 2 , . . . , B k B_1,B_2,...,B_k B1,B2,...,Bk 为 R R R, S S S 的公共属性,而 A 1 , A 2 , . . . , A k A_1,A_2,...,A_k A1,A2,...,Ak 为从 R R R 与 S S S 的属性集中去掉 S . B 1 , S . B 2 , . . . , S . B k S.B_1,S.B_2,...,S.B_k S.B1,S.B2,...,S.Bk 后剩余的属性;
- 除法:设关系
R
(
X
,
Y
)
R(X,Y)
R(X,Y),
S
(
Y
,
Z
)
S(Y,Z)
S(Y,Z),
X
X
X、
Y
Y
Y、
Z
Z
Z 为属性集,
R
÷
S
R \div S
R÷S 的过程如下:
( 1 ) . (1). (1). T = ∏ X ( R ) T = \prod _X(R) T=∏X(R);
( 2 ) . (2). (2). W = ( T × ∏ Y ( S ) ) − R W = (T \times \prod {}_Y(S)) - R W=(T×∏Y(S))−R:算出 T × ∏ Y ( S ) T\times \prod{}_Y(S) T×∏Y(S) 中不存在于 R R R 中的元组;
( 3 ) . (3). (3). V = ∏ X ( W ) V = \prod{}_X(W) V=∏X(W);
( 4 ) . (4). (4). R ÷ S = T − V R \div S = T - V R÷S=T−V
⇒ R ÷ S = ∏ X ( R ) − ∏ X ( ( ∏ X ( R ) × ∏ Y ( S ) ) − R ) \Rightarrow R \div S = \prod{}_X(R) - \prod{}_X\Big(\big(\prod_X(R) \times \prod_Y(S)\big) - R\Big) ⇒R÷S=∏X(R)−∏X((∏X(R)×∏Y(S))−R)
四、扩充的关系运算
随着数据库的发展和应用情况,关系运算被扩展。
1. 广义投影
设有关系模式 R R R,对其进行广义投影运算 ∏ F 1 , F 2 , . . . , F n ( R ) \prod{}_{F_1,F_2,...,F_n}(R) ∏F1,F2,...,Fn(R),其中 F 1 , . . . , F n F_1,...,F_n F1,...,Fn 涉及到 R R R 中常量和属性的算术表达式。通过这种广义投影运算对投影进行扩充。
例:若将查出的学生关系
s
t
u
d
e
n
t
student
student 中学号为
000101
000101
000101 学生的年龄加
1
1
1 岁,可以用广义投影运算表示为:
∏
s
n
o
,
s
n
a
m
e
,
s
e
x
,
a
g
e
=
a
g
e
+
1
(
σ
s
n
o
=
′
00010
1
′
(
s
t
u
d
e
n
t
)
\prod {}_{sno, sname,sex,age=age+1}(\sigma_{sno='000101'}(student)
∏sno,sname,sex,age=age+1(σsno=′000101′(student)
2. 赋值
设有相容的关系 R R R 和 S S S ,则通过赋值运算可以对关系 R R R 赋予新的关系 S S S,记为: R ← S R \leftarrow S R←S,其中 S S S 是通过关系代数运算得到的关系。通过赋值,可以把复杂的关系表达式化为若干个简单的表达式进行运算。特别是对于插入、删除和修改操作来说,很方便。
例:在关系
c
o
u
r
s
e
course
course 中新增一门新课:(099, 电子商务, 2, 003),可以用赋值操作表示如下:
c
o
u
r
s
e
←
c
o
u
r
s
e
∪
{
099
,
电
子
商
务
,
2
,
003
}
course \leftarrow course \cup \{099,电子商务,2,003\}
course←course∪{099,电子商务,2,003}
例:设学号为 200108 的学生因故退学,在关系 student 和 sc中将其相关记录删除,可表示为:
s
t
u
d
e
n
t
←
s
t
u
d
e
n
t
−
(
σ
s
n
o
=
′
20010
8
′
(
s
t
u
d
e
n
t
)
)
s
c
←
s
c
−
(
σ
s
n
o
=
′
20010
8
′
(
s
c
)
)
\begin{aligned} &student \leftarrow student - (\sigma _{sno='200108'}(student))\\ &sc \leftarrow sc - (\sigma _{sno='200108'}(sc))\end{aligned}
student←student−(σsno=′200108′(student))sc←sc−(σsno=′200108′(sc))
对关系进行修改时,可以先将要修改的元组删除,再将新元组插入即可。
3. 几种外连接
(1). 外连接
设有关系 R R R 和 S S S,它们的公共属性组成的集合为 Y Y Y,则对 R R R 和 S S S 进行自然连接时,在 R R R 中可能存在某些元组,无法在 Y Y Y 上与 S S S 的任一元组相等;同样对于 S S S 也是如此,可能存在某些元组无法在 Y Y Y 上与 R R R 的任一元组相等。那么当 R ⋈ S R \Join S R⋈S 时,这些元组都会被舍弃。
如果不舍弃这些元组,并且在这些元组新增加的属性上赋空值,这种操作就被称为“外连接”。表示如下……
我在 KaTeX \href{https://katex.org}{\KaTeX} KATEX 找了半天,没看到外连接的符号,算了。
(2). 左外连接
如果只保存
R
R
R 中原来要舍弃的元组,则称为
R
R
R 与
S
S
S 的 “左外连接”。表示为:
R
⟖
S
R\ ⟖\ S
R ⟖ S
(3). 右外连接
如果只保存 S S S 中原来要舍弃的元组,则称为 R R R 与 S S S 的 “右外连接”。
4. 半连接
设有关系 R R R 和 S S S,则 R R R 和 S S S 的自然连接只在关系 R R R 或 S S S 的属性集上的投影,称为“半连接”。 R R R 和 S S S 的半连接记作 R ⋉ S R \ltimes S R⋉S, S S S 与 R R R 的半连接记作 R ⋊ S R \rtimes S R⋊S 或者 S ⋉ R S \ltimes R S⋉R 。
5. 聚集
关系的聚集是指根据关系中的一组值,经过统计计算得到一个值作为结果。
比较常用的有 max , min , a v g , s u m , c o u n t \max,\min,avg,sum,count max,min,avg,sum,count 等。使用聚集函数时需要在前面写上符号 G G G。
例:对于学生-选课关系数据库的统计:
(1)求男同学的平均年龄:
G
a
v
g
(
a
g
e
)
(
σ
s
e
x
=
′
男
′
(
s
t
u
d
e
n
t
)
)
G\ avg(age)(\sigma _{sex='男'}(student))
G avg(age)(σsex=′男′(student))
(2)计算年龄不小于
20
20
20 岁的学生人数:
G
c
o
u
n
t
(
s
n
o
)
(
σ
a
g
e
≥
20
(
s
t
u
d
e
n
t
)
)
G\ count(sno)(\sigma _{age\ge 20}(student))
G count(sno)(σage≥20(student))
(3)计算选修数据库课程的平均分数:
G
a
v
g
(
g
r
a
d
e
)
(
∏
c
n
o
(
σ
c
n
a
m
e
=
′
数
据
库
′
(
c
o
u
r
s
e
)
)
⋈
s
c
)
G\ avg(grade)(\prod _{cno}(\sigma _{cname='数据库'}(course)) \Join sc)
G avg(grade)(∏cno(σcname=′数据库′(course))⋈sc)
6. 外部并
设有关系 R R R 和 S S S, R R R 和 S S S 的外部并得到一个新关系,其属性由 R R R 和 S S S 中的所有属性组成,公共属性仅取一次,其元组由属于 R R R 或属于 S S S 的元组组成,且元组在新增加的属性上填上空值。
7. 重命名
- ρ x ( E ) ρ_x(E) ρx(E):其含义为 给一个关系表达式赋予名字。它返回表达式 E E E 的结果,并把名字 x x x 赋给 E E E。
- ρ x ( A 1 , A 2 , … … , A n ) ( E ) ρ_x(A_1,A_2,……,A_n)(E) ρx(A1,A2,……,An)(E):其含义为返回表达式 E E E 的结果,并把名字 x x x 赋给 E E E,同时将各属性更名为 A 1 , A 2 , … … , A n A_1,A_2,……,A_n A1,A2,……,An 。
实际上,关系可以被看做一个最小的关系代数式,可以将重命名运算施加到 关系 或 属性 上,得到具有不同名字的 同一关系 或 不同属性名的 同一关系 。这对同一关系多次参与同一运算时很有用。
例:设关系
R
(
姓
名
,
课
程
,
成
绩
)
R(姓名,课程,成绩)
R(姓名,课程,成绩),求数学成绩比王红同学高的学生。
解:因为在同一关系上难以进行比较,采用重命名运算:
∏
S
.
姓
名
(
(
σ
课
程
=
′
数
学
′
∧
姓
名
=
′
王
红
′
(
R
)
)
⋈
R
.
成
绩
<
S
.
成
绩
(
σ
课
程
=
′
数
学
′
ρ
S
(
R
)
)
)
\prod {}_{S.姓名}((\sigma _{课程='数学' \wedge 姓名='王红'}(R)) \Join_{R.成绩 \lt S.成绩} (\sigma _{课程='数学'}\ \rho_S(R)))
∏S.姓名((σ课程=′数学′∧姓名=′王红′(R))⋈R.成绩<S.成绩(σ课程=′数学′ ρS(R)))
8. 扩充运算示例【重点】
需要注意的是,无论是外连接,还是半连接,都是基于自然连接之上的。这些连接的例子,有
R
R
R 和
S
S
S 关系如下:

自然连接
R
⋈
S
R \Join S
R⋈S 是建立在公共属性
X
,
Y
X,Y
X,Y 上的等值连接,连接后需要抛弃
S
S
S 中多余的公共属性
S
.
X
,
S
.
Y
S.X,S.Y
S.X,S.Y,保留
R
R
R 中没有的
S
S
S 的属性
S
.
Z
S.Z
S.Z,保留
S
S
S 中没有的
R
R
R 的属性
R
.
W
R.W
R.W。

可以看出,画了紫色下划线的这两个元组,无法在公共属性上与另一个关系中的任一元组相等,因此在自然连接中会被舍弃。

如果保留左边
R
R
R 的那些要被舍弃的元组,并在新的属性
Z
Z
Z 上赋空值的话,这就是左外连接:

如果保留右边
S
S
S 的那些要被舍弃的元组,并在新的属性
R
.
W
R.W
R.W 上赋空值的话,这就是右外连接:

如果同时保留两边要舍弃的元组,并在各自新的属性上赋空值,这就是外连接:

注意,这些都是要被舍弃的元组!它们不会发生自然连接!
半连接基于自然连接,但和外连接不同,半连接仅仅保留一边的属性。

对于
R
⋈
S
R\Join S
R⋈S,保留
R
R
R 的属性,
R
R
R 和
S
S
S 的半连接记作
R
⋉
S
R \ltimes S
R⋉S,
S
S
S 与
R
R
R 的半连接记作
S
⋉
R
S \ltimes R
S⋉R:

另外,需要清楚的是外部并,并运算是集合运算,基于同类关系;外部并可以对不同类的关系进行运算,其结果的属性列为
R
R
R 和
S
S
S 属性列的并集,其中公共属性只取一次;结果的行为
R
R
R 和
S
S
S 记录的并集,只不过它们各自对新增的属性列填上空值:

五、实际练习
1、设有下图所示的5个关系表
R
R
R、
S
S
S、
T
T
T、
U
U
U和
V
V
V,请写出下列各种运算结果。

(1)
R
∪
S
R∪S
R∪S
解:

(2)
R
∩
S
R∩S
R∩S
解:

(3)
R
×
S
R×S
R×S
解:

(4)
U
÷
V
U÷V
U÷V
解:可得,公共属性为
Z
,
W
Z,W
Z,W:
a
.
a.
a.
∏
X
,
Y
(
U
)
=
{
(
a
,
b
)
,
(
c
,
a
)
}
\prod {}_{X,Y}(U) = \{(a,b),(c,a)\}
∏X,Y(U)={(a,b),(c,a)};
b
.
b.
b.
∏
Z
,
W
(
V
)
=
{
(
e
,
f
)
,
(
c
,
d
)
}
\prod {}_{Z,W}(V) = \{(e,f),(c,d)\}
∏Z,W(V)={(e,f),(c,d)};
c
.
c.
c. 求像集如下:
- 对于 ( a , b ) (a,b) (a,b),有 ∏ Z , W ( σ X = a ∧ Y = b ( U ) ) = { ( c , d ) , ( e , f ) } \prod {}_{Z,W}\Big(\sigma _{X=a\ \wedge\ Y = b}(U)\Big) = \{(c,d),(e,f)\} ∏Z,W(σX=a ∧ Y=b(U))={(c,d),(e,f)};
- 对于 ( c , a ) (c,a) (c,a),有 ∏ Z , W ( σ X = c ∧ Y = a ( U ) ) = { ( c , d ) } \prod {}_{Z,W}\Big(\sigma _{X=c\ \wedge\ Y = a}(U)\Big) = \{(c,d)\} ∏Z,W(σX=c ∧ Y=a(U))={(c,d)}.
d . d. d. 可以发现,包含了 ∏ Z , W ( V ) ∏{}_{Z,W}(V) ∏Z,W(V) 的只有 ( a , b ) (a,b) (a,b),所以 U ÷ V = { ( a , b ) } U \div V = \{(a,b)\} U÷V={(a,b)}.
(5)
R
R
R 与
T
T
T 的外部并
解:

(6)
U
U
U 与
T
T
T 的外连接、左外连接及右外连接
解:

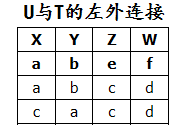

(7)
T
⋈
S
T ⋈ S
T⋈S

2、已知学生表
S
S
S、仼课表
C
C
C 和选课表
S
C
SC
SC 如下所示,试用关系代数表示下列查询。
- S(sno,sname,sex,age)
- C(cno,cname,teacher)
- SC(sno,cno,grade)
(1)查询"张景林"老师所授课程号和课程名。
答:
∏
c
n
o
,
c
n
a
m
e
(
σ
t
e
a
c
h
e
r
=
′
张
景
林
′
(
C
)
)
\prod {}_{cno, cname}(\sigma _{teacher='张景林'}(C))
∏cno,cname(σteacher=′张景林′(C))
(2)查询选修课程名为"C语言"或者"数据库"的学生号。
答:
∏
s
n
o
(
∏
c
n
o
(
σ
c
n
a
m
e
=
′
C
语
言
′
∨
c
n
a
m
e
=
′
数
据
库
′
(
C
)
)
⋈
S
C
)
\prod {}_{sno}\bigg(\prod {}_{cno}\Big(\sigma _{cname='C语言'\ \vee\ cname = '数据库'}(C)\Big) \Join SC\bigg)
∏sno(∏cno(σcname=′C语言′ ∨ cname=′数据库′(C))⋈SC)
(3)查询"高晓灵"同学所选俢课程的课程号及课程名。
答:
∏
c
n
o
,
c
n
a
m
e
(
∏
s
n
o
(
σ
s
n
a
m
e
=
′
高
晓
灵
′
(
S
)
)
⋈
S
C
⋈
C
)
\prod {}_{cno, cname}\bigg(\prod {}_{sno}\Big(\sigma _{sname='高晓灵'}(S)\Big) \Join SC \Join C\bigg)
∏cno,cname(∏sno(σsname=′高晓灵′(S))⋈SC⋈C)
(4)查询至少选俢两门课程的学生学号。
答:
∏
[
1
]
(
σ
[
1
]
=
[
4
]
∧
[
2
]
≠
[
5
]
(
S
C
×
S
C
)
)
\prod {}_{[1]} (\sigma _{[1] = [4]\ \wedge\ [2] \ne [5]} (SC \times SC))
∏[1](σ[1]=[4] ∧ [2]=[5](SC×SC))
(5)查询全部学生都选修的课程的课程号和课程名。
答:
∏
s
n
o
,
c
n
o
(
S
C
)
÷
∏
s
n
o
(
S
)
⋈
∏
c
n
o
,
c
n
a
m
e
(
C
)
\prod {}_{sno,cno}(SC) \div \prod {}_{sno}(S) \Join \prod {}_{cno, cname}(C)
∏sno,cno(SC)÷∏sno(S)⋈∏cno,cname(C)
(6)查询至少选修"张景林"老师所授全部课程的学生姓名。
答:
∏
s
n
a
m
e
(
∏
s
n
o
,
s
n
a
m
e
(
S
)
⋈
(
∏
s
n
o
,
c
n
o
(
S
C
)
÷
∏
c
n
o
(
σ
t
e
a
c
h
e
r
=
′
张
景
林
′
(
C
)
)
)
)
\prod {}_{sname}\Bigg(\prod {}_{sno,sname}(S) \Join \bigg( \prod {}_{sno,cno}(SC)\div \prod {}_{cno}(\sigma _{teacher='张景林'}(C))\bigg) \Bigg)
∏sname(∏sno,sname(S)⋈(∏sno,cno(SC)÷∏cno(σteacher=′张景林′(C))))
除法运算的定义:除法运算 ÷ \div ÷ 是同时从关系的水平和垂直方向进行运算。
给定关系
R
(
X
,
Y
)
R(X,Y)
R(X,Y) 和
S
(
Y
,
Z
)
S(Y,Z)
S(Y,Z),
X
,
Y
,
Z
X,Y,Z
X,Y,Z 为属性组。
R
÷
S
R \div S
R÷S 为:元组在
X
X
X 上的分量值
x
x
x 的 像集
Y
x
Y_x
Yx ,包含 关系
S
S
S 在属性组
Y
Y
Y 上投影
π
y
(
S
)
\pi_y(S)
πy(S) 的 集合。形式定义:
R
÷
S
=
{
t
n
[
X
]
∣
t
n
∈
R
∧
π
y
(
S
)
⊆
Y
x
}
R \div S = \{\ t_n[X]\quad |\quad t_n \in R \wedge \pi_y(S) \subseteq Y_x\}
R÷S={ tn[X]∣tn∈R∧πy(S)⊆Yx}
这个概念非常抽象,我反正是没有听懂的。所以,这里通过一个实例来说明除法运算的求解过程:
设有关系
R
、
S
R、S
R、S 如图所示,求
R
÷
S
R÷S
R÷S 的结果:

求解步骤过程:
-
第一步:找出被除关系 R R R 和关系 S S S 中 相同的属性列,即 Y Y Y 属性。关系 S S S 中对 Y Y Y 做投影(即将 Y Y Y 无重复的列举出);所得结果如下:

-
第二步:找出被除关系 R R R 中与 S S S 中不相同的属性列,即 X X X 属性。关系 R R R 中对 X X X 做投影(即将 X X X 无重复的列举出);所得结果如下:

-
第三步:求关系 R R R 中 X X X 属性对应的 像集 Y Y Y。根据关系 R R R 的记录,可以得到与 X 1 X_1 X1 值有关的记录,如图3所示,与 X 2 X_2 X2 有关的记录,如图4所示:

-
第四步:判断包含关系。 R ÷ S R÷S R÷S 其实就是判断关系 R R R 中 X X X 各个值 x x x 的像集 Y x Y_x Yx 是否包含关系 S S S 中属性 Y Y Y 的所有值。对比即可发现:
- X 1 X_1 X1 的像集只有 Y 1 Y_1 Y1,不能包含关系 S S S 中属性 Y Y Y 的所有值,所以排除掉 X 1 X_1 X1;
- X 2 X_2 X2 的像集包含了关系 S S S 中属性 Y Y Y 的所有值,所以 R ÷ S R÷S R÷S 的最终结果就是 X 2 X_2 X2。
也许现在有点明白除法运算是如何操作的了,下面来引申一下,除法运算可以解决什么问题呢?
e
.
g
.
e.g.
e.g. 设有关系
R
,
S
R,S
R,S 以及
R
S
RS
RS,如图所示,求
R
S
÷
S
RS÷S
RS÷S 的结果:

重复一遍上面的求解过程:
- 找到 关系 R S RS RS 和 S S S 中相同的属性列 课 程 名 课程名 课程名,即为 Y Y Y 属性,对其投影,得到 π 课 程 名 ( R S ) = { 语 文 , 数 学 } \pi_{课程名}(RS) = \{语文, 数学\} π课程名(RS)={语文,数学}。
- 找到关系 R S RS RS 中和 S S S 不相同的属性列 学 生 名 学生名 学生名,即为 X X X 属性,对其投影,得到 π 学 生 名 ( R S ) = { 张 三 , 李 四 } \pi_{学生名}(RS) = \{张三, 李四\} π学生名(RS)={张三,李四}。
- 对于 X X X 属性中的每一个分量值 x x x,有像集 Y x Y_x Yx:张三的像集为 { 语 文 , 数 学 } \{语文, 数学\} {语文,数学};李四的像集为 { 语 文 } \{语文\} {语文}。
- 判断包含关系,只有张三包含了关系 S S S 中的属性 Y Y Y 的所有值,因此求得结果为: { 张 三 } \{张三\} {张三}。
所以,可以容易看出来 R S ÷ S RS÷S RS÷S 在这里解决的问题就是:“得到选修了所有课程的学生”。 R S ÷ S RS÷S RS÷S 的意义就是:“在 R R R 和 S S S 的联系 R S RS RS 中,找出与 S S S 中 所有的元组有关系 的 R R R 元组”。
除法运算的定义:除法运算 ÷ \div ÷ 是同时从关系的水平和垂直方向进行运算。
给定关系
R
(
X
,
Y
)
R(X,Y)
R(X,Y) 和
S
(
Y
,
Z
)
S(Y,Z)
S(Y,Z),
X
,
Y
,
Z
X,Y,Z
X,Y,Z 为属性组。
R
÷
S
R \div S
R÷S 为:元组在
X
X
X 上的分量值
x
x
x 的 像集
Y
x
Y_x
Yx ,包含 关系
S
S
S 在属性组
Y
Y
Y 上投影
π
y
(
S
)
\pi_y(S)
πy(S) 的 集合。形式定义:
R
÷
S
=
{
t
n
[
X
]
∣
t
n
∈
R
∧
π
y
(
S
)
⊆
Y
x
}
R \div S = \{\ t_n[X]\quad |\quad t_n \in R \wedge \pi_y(S) \subseteq Y_x\}
R÷S={ tn[X]∣tn∈R∧πy(S)⊆Yx}
这个概念非常抽象,我反正是没有听懂的。所以,这里通过一个实例来说明除法运算的求解过程:
设有关系
R
、
S
R、S
R、S 如图所示,求
R
÷
S
R÷S
R÷S 的结果:
求解步骤过程:
-
第一步:找出被除关系 R R R 和关系 S S S 中 相同的属性列,即 Y Y Y 属性。关系 S S S 中对 Y Y Y 做投影(即将 Y Y Y 无重复的列举出);所得结果如下:
-
第二步:找出被除关系 R R R 中与 S S S 中不相同的属性列,即 X X X 属性。关系 R R R 中对 X X X 做投影(即将 X X X 无重复的列举出);所得结果如下:
-
第三步:求关系 R R R 中 X X X 属性对应的 像集 Y Y Y。根据关系 R R R 的记录,可以得到与 X 1 X_1 X1 值有关的记录,如图3所示,与 X 2 X_2 X2 有关的记录,如图4所示:
-
第四步:判断包含关系。 R ÷ S R÷S R÷S 其实就是判断关系 R R R 中 X X X 各个值 x x x 的像集 Y x Y_x Yx 是否包含关系 S S S 中属性 Y Y Y 的所有值。对比即可发现:
- X 1 X_1 X1 的像集只有 Y 1 Y_1 Y1,不能包含关系 S S S 中属性 Y Y Y 的所有值,所以排除掉 X 1 X_1 X1;
- X 2 X_2 X2 的像集包含了关系 S S S 中属性 Y Y Y 的所有值,所以 R ÷ S R÷S R÷S 的最终结果就是 X 2 X_2 X2。
也许现在有点明白除法运算是如何操作的了,下面来引申一下,除法运算可以解决什么问题呢?
e
.
g
.
e.g.
e.g. 设有关系
R
,
S
R,S
R,S 以及
R
S
RS
RS,如图所示,求
R
S
÷
S
RS÷S
RS÷S 的结果:
重复一遍上面的求解过程:
- 找到 关系 R S RS RS 和 S S S 中相同的属性列 课 程 名 课程名 课程名,即为 Y Y Y 属性,对其投影,得到 π 课 程 名 ( R S ) = { 语 文 , 数 学 } \pi_{课程名}(RS) = \{语文, 数学\} π课程名(RS)={语文,数学}。
- 找到关系 R S RS RS 中和 S S S 不相同的属性列 学 生 名 学生名 学生名,即为 X X X 属性,对其投影,得到 π 学 生 名 ( R S ) = { 张 三 , 李 四 } \pi_{学生名}(RS) = \{张三, 李四\} π学生名(RS)={张三,李四}。
- 对于 X X X 属性中的每一个分量值 x x x,有像集 Y x Y_x Yx:张三的像集为 { 语 文 , 数 学 } \{语文, 数学\} {语文,数学};李四的像集为 { 语 文 } \{语文\} {语文}。
- 判断包含关系,只有张三包含了关系 S S S 中的属性 Y Y Y 的所有值,因此求得结果为: { 张 三 } \{张三\} {张三}。
所以,可以容易看出来 R S ÷ S RS÷S RS÷S 在这里解决的问题就是:“得到选修了所有课程的学生”。 R S ÷ S RS÷S RS÷S 的意义就是:“在 R R R 和 S S S 的联系 R S RS RS 中,找出与 S S S 中 所有的元组有关系 的 R R R 元组”。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











