










本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系列刷题文章中,我不仅会讲解多种解题思路及其优化,还会用多种编程语言实现题解,涉及到通用解法时更将归纳总结出相应的算法模板。
为了方便在PC上运行调试、分享代码文件,我还建立了相关的仓库:https://github.com/memcpy0/LeetCode-Conquest。在这一仓库中,你不仅可以看到LeetCode原题链接、题解代码、题解文章链接、同类题目归纳、通用解法总结等,还可以看到原题出现频率和相关企业等重要信息。如果有其他优选题解,还可以一同分享给他人。
由于本系列文章的内容随时可能发生更新变动,欢迎关注和收藏征服LeetCode系列文章目录一文以作备忘。
You are given a doubly linked list which in addition to the next and previous pointers, it could have a child pointer, which may or may not point to a separate doubly linked list. These child lists may have one or more children of their own, and so on, to produce a multilevel data structure, as shown in the example below.
Flatten the list so that all the nodes appear in a single-level, doubly linked list. You are given the head of the first level of the list.
Example 1:
Input: head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
Output: [1,2,3,7,8,11,12,9,10,4,5,6]
Explanation:
The multilevel linked list in the input is as follows:

After flattening the multilevel linked list it becomes:

Example 2:
Input: head = [1,2,null,3]
Output: [1,3,2]
Explanation:
The input multilevel linked list is as follows:
1---2---NULL
|
3---NULL
Example 3:
Input: head = []
Output: []
How multilevel linked list is represented in test case:
We use the multilevel linked list from Example 1 above:
1---2---3---4---5---6--NULL
|
7---8---9---10--NULL
|
11--12--NULL
The serialization of each level is as follows:
[1,2,3,4,5,6,null]
[7,8,9,10,null]
[11,12,null]
To serialize all levels together we will add nulls in each level to signify no node connects to the upper node of the previous level. The serialization becomes:
[1,2,3,4,5,6,null]
[null,null,7,8,9,10,null]
[null,11,12,null]
Merging the serialization of each level and removing trailing nulls we obtain:
[1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]
Constraints:
- The number of Nodes will not exceed
1000. 1 <= Node.val <= 105
题意:多级双向链表中,除了指向下一个节点和前一个节点指针之外,它还有一个子链表指针,可能指向单独的双向链表。这些子列表也可能会有一个或多个自己的子项,依此类推,生成多级数据结构。给你位于列表第一级的头节点,请你扁平化列表,使所有结点出现在单级双链表中。
解法1 DFS+链表(尾插法)
看起来挺复杂,但是这道题目实际很简单。使用DFS,先向 child 节点进行DFS,再对 next 节点进行DFS,同时用数组收集节点指针,最后形成一个单级双链表。十分类似二叉树的先序遍历,只要把多级双向链表看做二叉链表即可。整个算法的时间复杂度为
O
(
n
)
O(n)
O(n) ,空间复杂度为
O
(
n
)
O(n)
O(n) :
//C++ version
class Solution {
private:
vector<Node*> vi;
void dfs(Node* cur) {
if (cur == nullptr) return;
vi.push_back(cur);
dfs(cur->child);
dfs(cur->next);
}
public:
Node* flatten(Node* head) {
dfs(head);
for (int i = 0, n = vi.size(); i < n; ++i) {
if (i > 0) vi[i]->prev = vi[i - 1];
if (i < n - 1) vi[i]->next = vi[i + 1];
else vi[i]->next = nullptr; //置为nullptr
vi[i]->child = nullptr;
}
return head;
}
};
//执行用时:4 ms, 在所有 C++ 提交中击败了91.15% 的用户
//内存消耗:7.5 MB, 在所有 C++ 提交中击败了6.84% 的用户
改进代码,使用虚拟头结点,可以降低空间复杂度到 O ( 1 ) O(1) O(1) :
//C++ version
class Solution {
private:
Node dummyHead, *pre = &dummyHead;
void dfs(Node* head) {
if (head == nullptr) return;
head->prev = pre; pre->next = head; pre = pre->next;
Node *tempNext = pre->next, *tempChild = pre->child;
pre->next = pre->child = nullptr; //置为nullptr
dfs(tempChild);
dfs(tempNext);
}
public:
Node* flatten(Node* head) {
if (head == nullptr) return head;
dfs(head);
Node *newHead = dummyHead.next;
//否则可能报错The linked list...is not a valid doubly linked list.
dummyHead.next = nullptr, newHead->prev = nullptr;
return newHead;
}
};
//执行用时:4 ms, 在所有 C++ 提交中击败了91.15% 的用户
//内存消耗:7.1 MB, 在所有 C++ 提交中击败了88.14% 的用户
解法2 链表+递归
如果使用 flatten 函数本身的语义——将链表头为 head 的多级双向链表扁平化,并返回扁平化后的头结点,我们可以轻松写出递归版本。
为防止某些边界问题。仍然使用一个虚拟头结点 dummyHead 指向 head ,然后利用 head 指针分情况从前往后处理链表:
- 当前节点
head没有child节点:直接让head = head->next,即指针后移; - 当前节点
head有child节点:- 使用
flatten(head->child)递归处理,拿到扁平化后的头结点childHead - 然后保存
temp = head->next及将head->child置为空 - 再让
head和childHead相邻,即相互连接 - 然后往后找到扁平化后的
childHead链表的尾部,将其与temp建立相邻关系
- 使用
- 重复上两步,直到处理完整条链表
看起来有点繁琐,也确实比较麻烦。整个算法的时间复杂度为 O ( n 2 ) O(n^2) O(n2) ,空间复杂度为 O ( 1 ) O(1) O(1)(如果不计算递归深度):
//Java version
class Solution {
public Node flatten(Node head) {
Node dummyHead = new Node(0);
dummyHead.next = head;
while (head != null) {
if (head.child == null) head = head.next;
else {
Node childHead = flatten(head.child); //recursively process
Node temp = head.next;
head.child = null;
head.next = childHead; //和扁平化链表头部连接
childHead.prev = head;
while (head.next != null) head = head.next; //找到扁平化链表尾部
head.next = temp; //和扁平化链表尾部连接
if (temp != null) temp.prev = head;
head = temp;
}
}
return dummyHead.next;
}
}
//执行用时:1 ms, 在所有 Java 提交中击败了20.09% 的用户
//内存消耗:36.3 MB, 在所有 Java 提交中击败了74.22% 的用户
如果要优化整个算法的话,就不能使用 flatten 函数的语义,需要新创建一个函数 flattenHeadTail ,扁平化多级双向链表并返回扁平化的链表头部 childHead 和尾部 childTail ,头部和尾部之间视作一个整体,然后将这个扁平化链表插入到 head 和 head->next 中。
上述想法是很自然的,不过我们可以进一步优化。由于扁平化后的 childHead 实际上就是 head->child ,所以只需要返回扁平化后的链表尾结点,确保找尾结点的动作不会在每层发生。这样就将时间复杂度降低到了
O
(
n
)
O(n)
O(n) :
//Java version
class Solution {
private Node flattenReturnTail(Node head) {
Node last = head;
while (head != null) {
if (head.child == null) {
last = head;
head = head.next;
} else {
Node childLast = flattenReturnTail(head.child);
Node temp = head.next;
head.next = head.child; //和扁平化链表头部连接
head.child.prev = head;
head.child = null; //置为空
// if (childLast != null)
childLast.next = temp; //尾结点childLast一定非空; 和扁平化链表尾部连接
if (temp != null) temp.prev = childLast;
last = head;
head = childLast;
}
}
return last;
}
public Node flatten(Node head) {
flattenReturnTail(head); //函数不会改变头节点
return head;
}
}
//执行用时:0 ms, 在所有 Java 提交中击败了100.00% 的用户
//内存消耗:36.4 MB, 在所有 Java 提交中击败了45.99% 的用户
解法3 链表+迭代
既然可以用递归求解,那么自然也能用迭代求解。不过迭代是以段为单位进行扁平化,递归是以深度遍历方向进行扁平化,两种方式对每个扁平节点的处理顺序不同。以例1为例:
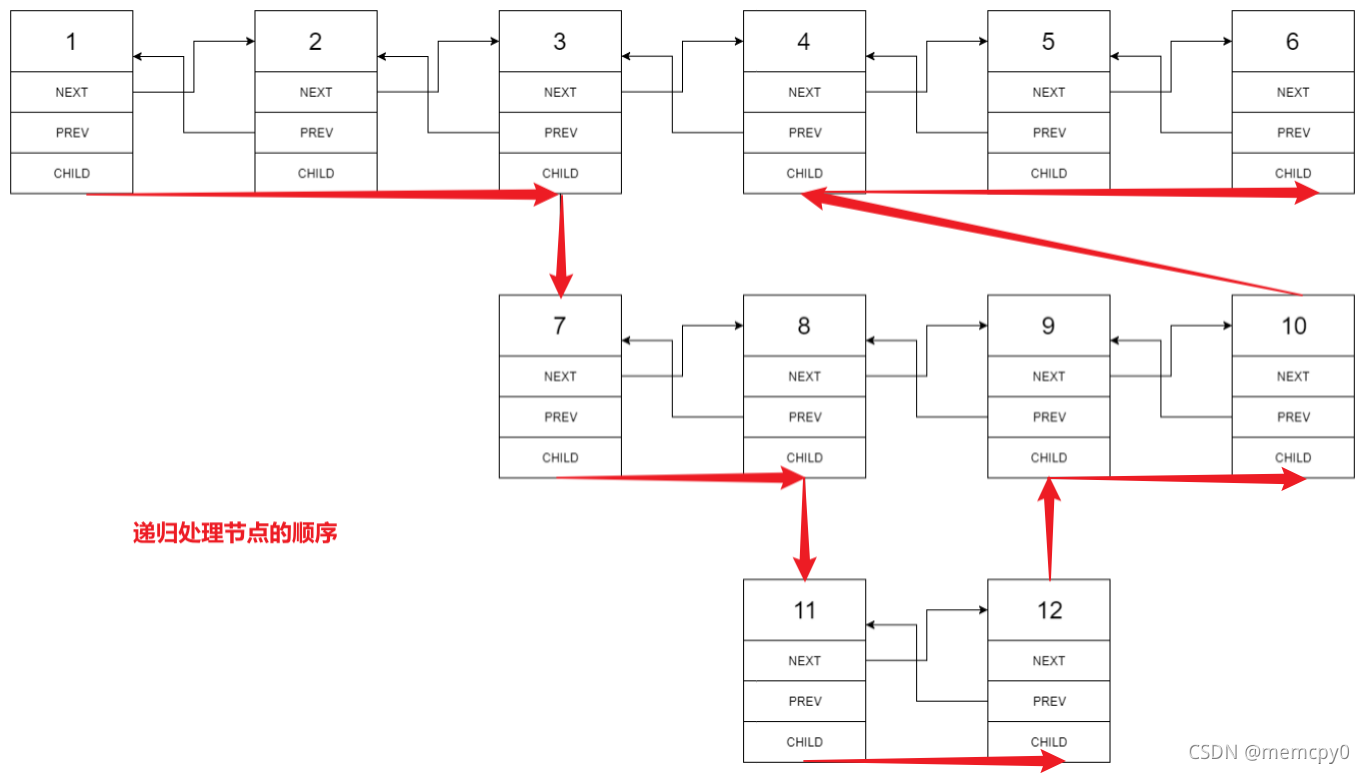
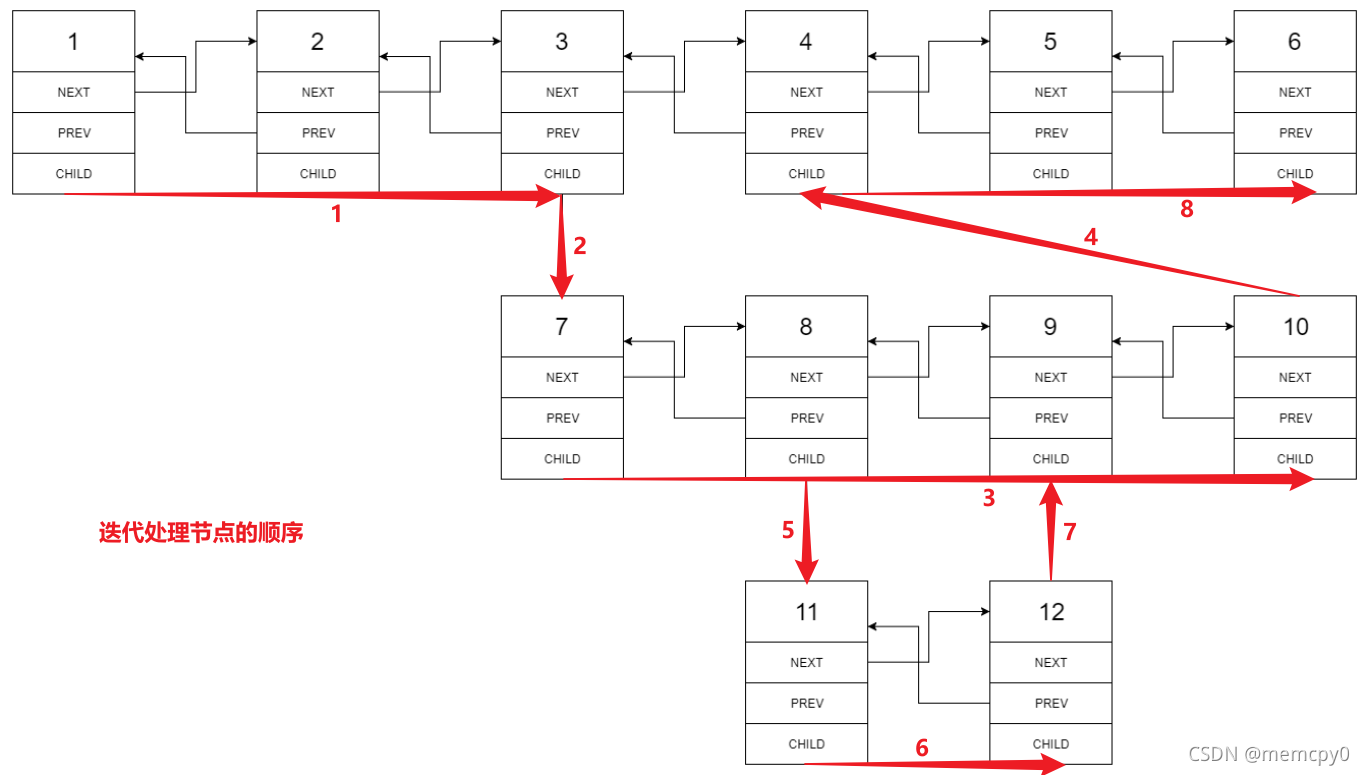
具体代码如下。由于迭代写法中每个节点被访问的次数仍为常数次,时间复杂度为 O ( n ) O(n) O(n) ,空间复杂度为 O ( 1 ) O(1) O(1) :
//Java version
class Solution {
public Node flatten(Node head) {
Node dummyHead = new Node(0);
dummyHead.next = head;
while (head != null) {
if (head.child == null) {
head = head.next;
} else {
Node temp = head.next;
head.next = head.child; //和扁平化链表头部连接
head.child.prev = head;
head.child = null; //置为空
Node last = head;
while (last.next != null) last = last.next;
last.next = temp;
if (temp != null) temp.prev = last; //和扁平化链表尾部连接
head = head.next;
}
}
return dummyHead.next;
}
}
//执行用时:0 ms, 在所有 Java 提交中击败了100.00% 的用户
//内存消耗:36.2 MB, 在所有 Java 提交中击败了88.99% 的用户


















 677
677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











