









 本文概述了IEEE 802标准在局域网中的应用,重点介绍了标准以太网的演变,包括MAC子层的帧结构、物理层实现、从10Base到10Gigabit以太网的升级,以及全双工、交换式和桥接网络的变迁。详细讲解了快速以太网和千兆以太网的自动协商和编码技术,以及干兆以太网的全双工模式和物理层选择。
本文概述了IEEE 802标准在局域网中的应用,重点介绍了标准以太网的演变,包括MAC子层的帧结构、物理层实现、从10Base到10Gigabit以太网的升级,以及全双工、交换式和桥接网络的变迁。详细讲解了快速以太网和千兆以太网的自动协商和编码技术,以及干兆以太网的全双工模式和物理层选择。
我们知道,局域网 LAN 用于有限的地理范围,如一幢建筑物或一个学校的计算机网络。虽然为了共享资源这一目的,可以将 LAN 作为孤立的网络、用来连接一个组织内的计算机,但是,当今很多的 LAN 也连接到广域网 WAN 或因特网上。
局域网市场有多种技术,例如以太网、令牌环、令牌总线、FDDI 和 ATM LAN 。其中的某些技术只生存了一段时间,而如今最普遍应用的技术是以太网。在本章中,先简要地介绍IEEE标准项目802,它被设计来规范制造 LAN 以及不同 LAN 之间的互连。然后主要介绍以太局域网,以太网是使用最广泛的局域网协议。
虽然在过去的几十年,以太网经历了四代的发展,但是主要理念还是相同的,且已经对以太网进行了改进以满足市场的需求,并对新技术加以应用。
13.1 IEEE标准
1985 年,电气与电子工程师学会 IEEE 开始了一个项目,称为 Project 802 ,以设定标准使得不同制造商生产的设备之间能相互通信。项目802并不旨在代替OSI或因特网模型。相反,它说明了大多数局域网协议的物理层和数据链路层的功能。这一标准被美国国家标准协会 ANSI 所采用。1987年,国际标准化组织 OSI 也批准它成为一个国际标准,命名为ISO 8802。
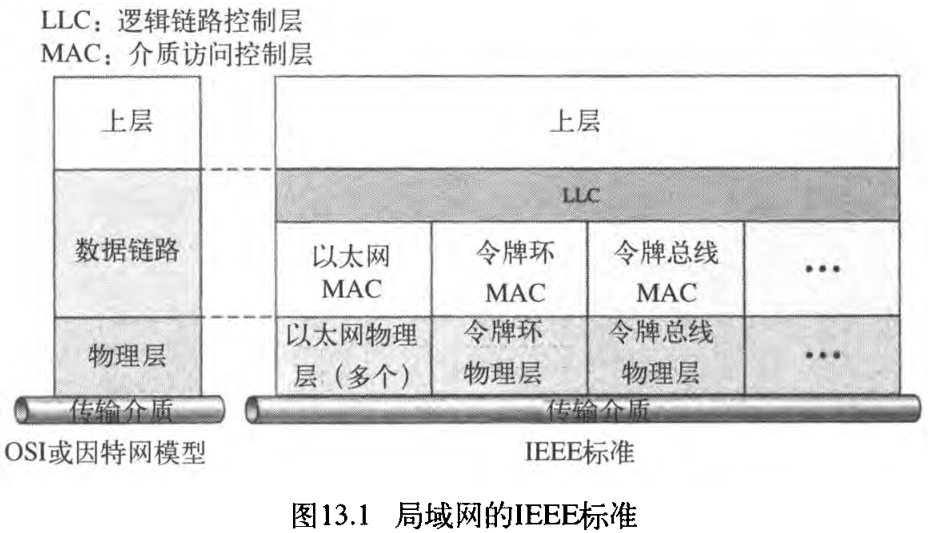
图13.1显示了802标准和传统的OSI模型之间的关系。IEEE将数据链路层分为两个子层:逻辑链路控制层 logical link control, LLC 和介质访问控制层 media access control, MAC 。IEEE也为不同的局域网协议制定了一些物理层标准。
13.1.1 数据链躇层
正如之前提到的那样,在IEEE标准中,数据链路层被分成两个子层:LLC 和 MAC 。
1. 逻辑链路控制层LLC
在【计算机网络】第三部分 数据链路层(11)中介绍了数据链路控制。数据链路层是用来处理封装成帧、流量控制和差错控制的。在IEEE项目802中,流量控制、差错控制和部分成帧的职能,都被集中到称为逻辑链路控制层的子层中。LLC和MAC两者都进行成帧处理。
LLC为所有的IEEE局域网提供一个单一的数据链路控制协议。在这方面,LLC不同于介质访问控制子层,后者为不同的局域网提供不同的协议。一个单一的 LLC协议,能使不同的局域网之间进行相互交换,因为它使MAC子层变得透明。图13.1显示了「为多个MAC协议服务的一个单一LLC协议」。
(1) 成帧
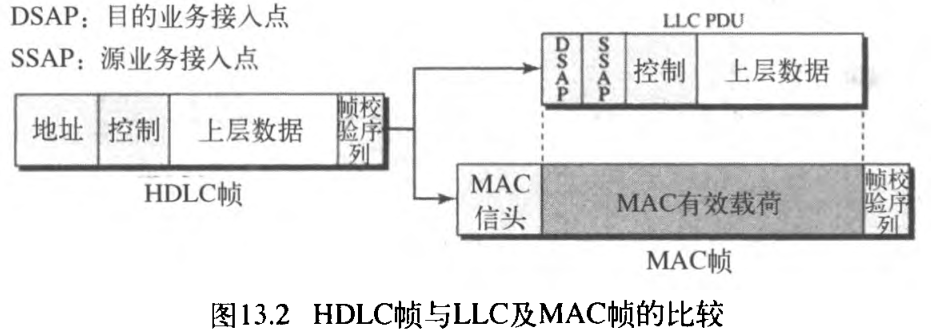
LLC定义了一个协议数据单元 PDU ,它在一定程度上与HDLC相似。头部包含一个控制字段(就像 HDLC中的一样),这个字段用以流量控制和差错控制。另两个头部字段界定了使用LLC的源和目的地的上层协议,这些字段称为目的业务接入点 destination service access point, DSAP 和源业务接入点 source service access point, SSAP 。
在典型的数据链路控制协议中定义的其他协议(如HDLC),被移入到了MAC子层中。换言之,HDLC中定义的帧被分为「LLC子层的PDU」和「MAC子层的一个帧」a frame defined in HDLC is divided into a PDU at the LLC sublayer and a frame at the MAC sublayer ,如图13.2所示。(?)
(2) LLC的需求
LLC的目的是为需要流量控制和差错控制的上层协议提供这些服务 provide flow and error control for the upper-layer protocols that actually demand these services 。例如,如果一个或几个局域网被应用于一个孤立的系统中,就需要LLC为应用层协议提供流量控制和差错控制。然而,多数上层协议诸如IP并不需要LLC的服务。因此,就此结束对LLC的介绍。
2. 介质访问控制层MAC
在【计算机网络】第三部分 数据链路层(12)中,介绍了包括随机访问、受控访问和通道化等的多种访问方法。IEEE项目802创造了一个称为介质访问控制层的子层,来为每个局域网定义特定的访问方法。例如,它定义CSMA/CD作为以太网的介质访问方法,令牌传递方法 token- passing method 为令牌环和令牌总线局域网 Token Ring and Token Bus LANs 的介质访问方法。
正如之前讨论的那样,MAC子层同样也有部分成帧的功能。与LLC子层相比较,MAC子层包含了一些独特的模块,每个模块都为相应的局域网协议定义了访问方法和成帧的格式。
13.1.2 物理层
物理层取决于网络的实现和使用的物理介质。IEEE为每个局域网的实现定义了详细的规范。例如,在标准以太网中虽然只有一个MAC子层,但是每种以太网的实现都有不同的物理层规范,稍后会作介绍。
13.2 标准以太网
最初的以太网是由施乐公司的Palo Alto研究中心(PARC)于1976年创建的。自此之后,它经历了四代发展:标准以太网 Standard Ethernet(
10
Mbps
10\textrm{Mbps}
10Mbps),快速以太网 Fast Ethernet(
100
Mbps
100\textrm{Mbps}
100Mbps),干兆以太网 Gigabit Ethernet(
1
Gbps
1\textrm{Gbps}
1Gbps)和
10
10
10 干兆以太网 Ten-Gigabit Ethernet (
10
Gbps
10\textrm{Gbps}
10Gbps) ,如图13.3所示。以太网定义了一些
1
Mbps
1 \textrm{Mbps}
1Mbps 协议 ,但它们没有发展起来。
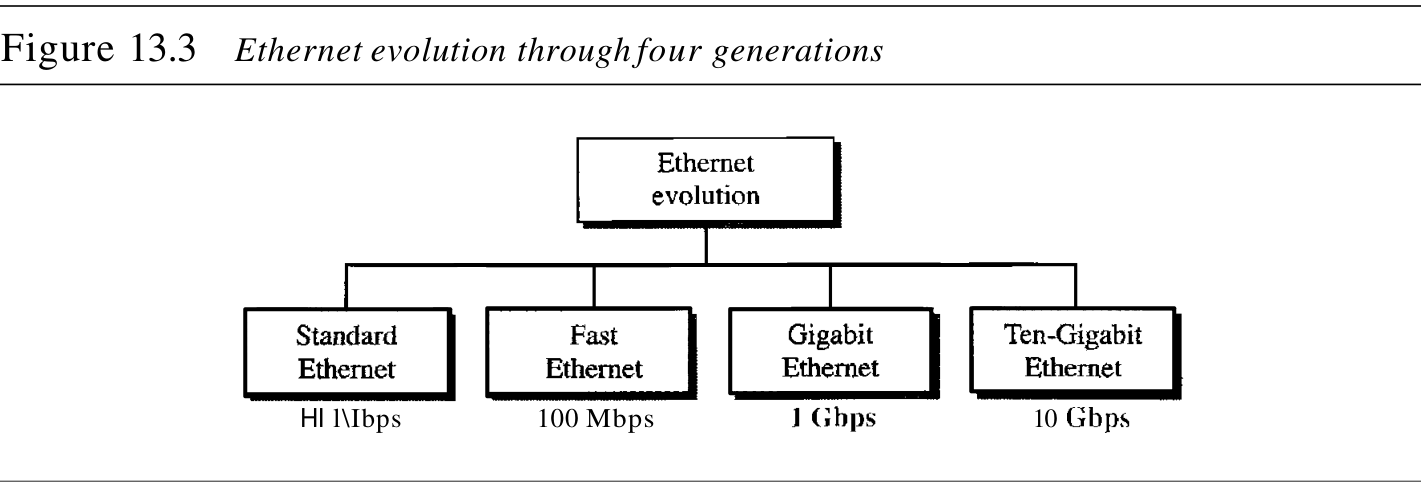
下面简要地介绍这四代以太网,先介绍标准(或传统)以太网。
13.2.1 MAC子层
在标准以太网中,MAC子层控制访问方法,还负责将来自上层的数据封装成帧并传输给物理层。
1. 帧的格式
以太网的帧包括
7
7
7 个字段:前导符、SFD、DA、SA、协议数据单元 PDU 的长度/类型、上层数据和CRC。MAC的帧格式如图13.4所示。对接收到的帧,以太网不提供确认的任何机制,所以将它称做不可靠的介质,确认必须在其高层完成。
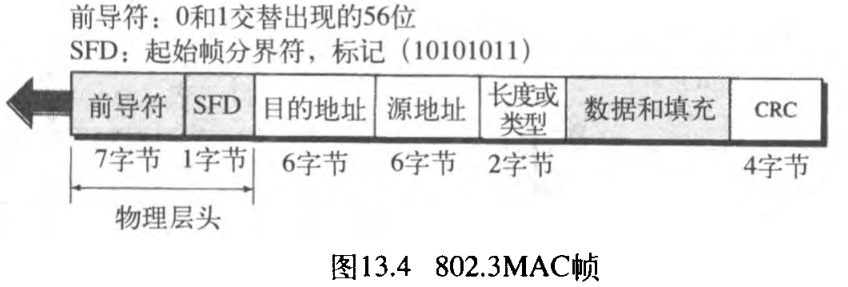
- 前导符
preamble。802.3帧的第一个字段包含 7 7 7 个字节,其中的 1 1 1 和 0 0 0 交替出现,以此通知接收系统有帧的到来、并且使其与输入的时钟同步。该模式仅提供一个通知和时钟脉冲。位模式容许站点在帧的开始可以丢弃一些位。实际上,前导符 是在物理层上加进去的,并不是帧的一个部分。 - 起始帧分界符
SFD。第二个字段占 1 1 1 个字节: 10101011 10101011 10101011 说明帧的开始。SFD通知站点「这是最后一个同步的机会」。最后的两位是 11 11 11 ,并且通知接收方下一个字段是目的地址。 - 目的地址
DA。这一字段为 6 6 6 个字节,包含目的站点或接收该分组的站点的物理地址。后面会简要地介绍目的地址。 - 源地址
SA。这一字段也是6个字节,包含分组的发送方的物理地址。后面会简要地介绍源地址。 - 长度/类型。这一字段定义为长度或类型字段。最初的以太网使用这个字段作为类型字段,定义使用MAC帧的上层协议。IEEE标准则使用它作为长度字段,定义数据字段的字节数。在今天两者都被普遍使用。
- 数据。这一字段的内容是由上一层协议封装的数据。它最少是 46 46 46 字节,最大是 1500 1500 1500 字节。如后面所述。
- CRC。最后字段为 4 4 4 字节的差错检测信息,在此情况下为CRC-32(第10章)。
2. 帧的长度
以太网对帧长度的最小值和最大值都有严格的规定。如图13.5所示。长度最小值的限定,是为了满足CMSA/CD正确运行的需要——以太网的帧必须有一个长度最小值:
512
512
512 位或
64
64
64 字节。长度的一部分是头部和尾部,如果将头部和尾部算为
18
18
18 字节(源地址
6
6
6 字节,目的地址
6
6
6 字节,长度或类型
2
2
2 字节及CRC
4
4
4 字节),那么来自上层的数据的最小长度是
64
−
18
=
46
64 - 18=46
64−18=46 字节。如果上层分组小于
46
46
46 字节,相差部分将会被填充满。

该标准定义帧长度的最大值(不包括前导符和 SFD 字段)为
1518
1518
1518 字节。如果减去头部和尾部的
18
18
18 字节,有效载荷的最大长度是
1500
1500
1500 字节。长度最大值的限定有两个历史原因。
- 第一,当以太网被设计出来时,存储器很贵:最大长度的限制有助于减小缓冲器的大小。
- 第二,长度最大值的限定防止了一个站点独占共享介质、而阻碍其他要发送数据的站点。
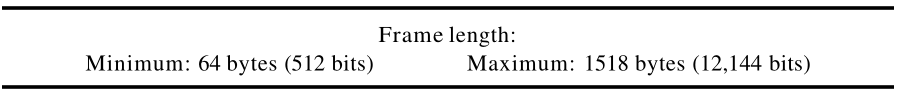
3. 寻址
以太网中的每个站点(例如一台电脑、工作站或一台打印机)都有自己的网络接口卡 network interface card, NIC ,简称为网卡。网卡安在站点内部、并给该站点提供一个
6
6
6 字节的物理地址。如图13.6所示,以太网地址是
6
6
6 字节的,通常用十六进制表示法 hexadecimal notation 来表示,字节间以冒号断开。

4. 单播地址、多播地址和广播地址
源地址永远是一个单播地址 unicast address一一帧只来自一个站点。然而目的地址既可以是单播地址,也可以是多播地址,还可以是广播地址 unicast, multicast, or broadcast 。图 13.7说明了如何区分单播地址和多播地址。如果目的地址字段第一个字节的最低位是
0
0
0 ,那么这个地址是单播地址,否则便是多播地址。
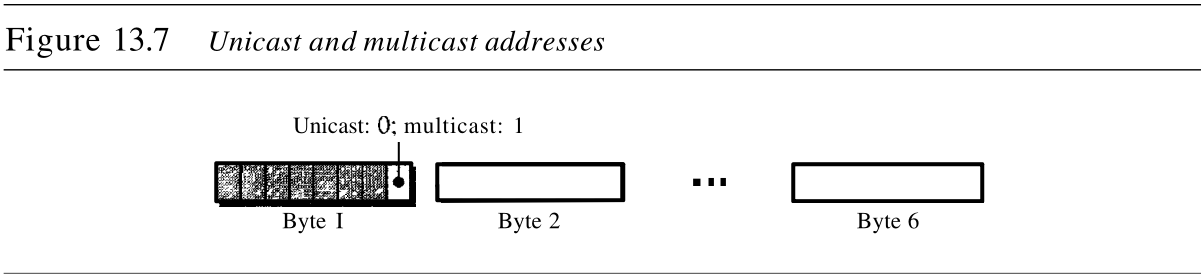
单播目的地址限定了只有一个接收方,发送方和接收方之间的关系是一对一的。多播目的地址定义了一组地址,发送方和接收方之间的关系是一对多的。广播地址是多播地址的一个特例:接收方是整个局域网中的所有站点。一个广播目的地址是
48
48
48 位
1
1
1(还有任播)。
【例3.1】定义下列目的地址的类型:
a. 4A: 30: 10: 21: 10: 1A
b. 47: 20: 1B: 2E: 08: EE
c. FF: FF: FF: FF: FF: FF
解:为了知道地址的类型,我们必须看左边第二个十六进制数字。如果是偶数,那么地址是单播地址。如果是奇数,那么地址是多播地址。如果所有的数字都是 F ,那么地址是广播地址(偶单奇多F广)。因此,得到以下答案:
a. 这是一个单播地址,因为 A 在二进制中是
1010
1010
1010(偶数)。
b. 这是一个多播地址,因为 7 在二进制中是
0111
0111
0111(奇数)。
c. 这是一个广播地址,因为所有的数字都是 F 。
在线发送地址的方法与将地址用十六进制表示能表示的方法不同。传输是从左到右的 left-to-right, byte by byte ,然而对每个字节而言,最低位被最先发送、而最高位被最后发送。这就意味着界定地址是单播地址还是多播地址的那一位最先到达接收方。
【例13.2】请说明地址 47: 20: 1B: 2E: 08: EE 是如何在线发送的。
解:地址被一个字节一个字节地从左向右发送,每个字节是一位一位地从右向左发送的,如下所示:
=> 11100010 00000100 11011000 01110100 00010000 01110111
5. 访问方法:CSMA/CD
IEEE802.3标准定义了,第一代
10
10
10 兆以太网即标准以太网使用1-持续的CSMA/CD方法(见第12章)。在一个以太网络中,一个帧从最大长度网络的一个端到另一端之间往返所需的时间、加上发送干扰序列所需的时间称为时隙 slot time 。时隙=往返时间+发送干扰序列所需时间。
以太网的时隙以位来定义,它是一个站点发送 512 512 512 位( 64 64 64 字节)所需的时间。这就意味着,实际的时隙取决于数据速率。对于传统的 10 Mbps 10\textrm{Mbps} 10Mbps 以太网来说是 51.2 μs 51.2\textrm{μs} 51.2μs 。
6. 时隙和冲突
选择 512 512 512 位的时隙并非偶然,这个选择使得CSMA/CD能发挥正确的功能。为了理解这点,看两种情况。
-
在第一种情况中,发送方发送一个 512 512 512 位的最小分组。在发送方能将整个分组发出之前,信号穿过网络并到达网络的终端。如果在网络的终端有另一个信号(最坏的情况),冲突就发生了。发送方有机会放弃发送帧,并发送一个干扰序列以提醒其他的站点。信号往返时间(取决于网络的长度)加上发送干扰序列所需的时间必须小于发送方发送最小的 512 512 512 位帧所需的时间(看网络的传输速率)。发送方必须在它发送整个帧之前意识到冲突的存在,否则,就太迟了。
-
在第二种情况中,发送方发送一个大于最小长度的帧(在 512 512 512 位和 1518 1518 1518 位之间)。这种情况下,如果发送方已经发送了第一个 512 512 512 位并没有听到冲突,它便能保证在这个帧的传输过程中不会发生冲突。原因是:
- 信号会在小于 1 / 2 1/2 1/2 时隙的时间内到达网络的终端。此后,如果所有的站点都遵循CSMA/CD协议,它们都已经检测到在线上这个信号的存在、并制止了自身的发送;
- 如果它们在
1
/
2
1/ 2
1/2 时隙的时间期满之前发送了信号,冲突便发生了,而发送方会检测到冲突。换言之,冲突只可能在时隙的前半段
the first half of the slot time发生,如果冲突真的发生了,发送方在时隙期间能检测到。
这就是说发送方发送第一个 512 512 512 位之后,它便能保证在这个帧的传输过程中不会有冲突发生。介质属于该发送方,而其他的站点不能使用介质。换言之,发送方只需要在发送第一个 512 512 512 位的时间内,"听"是否有冲突发生就可以了。
当然,如果有一个站点不遵循CSMA/CD协议的话,所有这些假设都是不成立的。在这种情况下,不是发生了冲突,而是一个站点被损坏了。
7. 时隙和最大网络长度
时隙和最大网络长度(冲突域)之间有关联(信号往返时间与最大网络长度有关)。这取决于在一个特定的介质中信号的传播速度。在大多数传输介质中,信号以
2
×
1
0
8
m
/
s
2 \times 10^8m/s
2×108m/s传播(是在空气中传播速度的
2
/
3
2/3
2/3 )。对传统以太网(传输速率为
10
Mbps
10\textrm{Mbps}
10Mbps )而言,(由于规定了时隙为发送
512
512
512 位的时间)计算如下:
最
大
长
度
=
传
播
速
度
×
(
时
隙
/
2
)
=
(
2
×
1
0
8
)
×
(
51.2
×
1
0
−
6
/
2
)
=
5120
m
最大长度=传播速度 \times (时隙 /2) \\ = (2 \times 10^8) \times (51.2 \times 10^{-6}/2) = 5 120m
最大长度=传播速度×(时隙/2)=(2×108)×(51.2×10−6/2)=5120m
当然,我们需要考虑中继器和接口的延迟、以及发送干扰序列所需的时间。这些将传统以太网的最大长度减少为 2500 2500 2500 米,仅仅是理论上的 48 % 48\% 48% 。
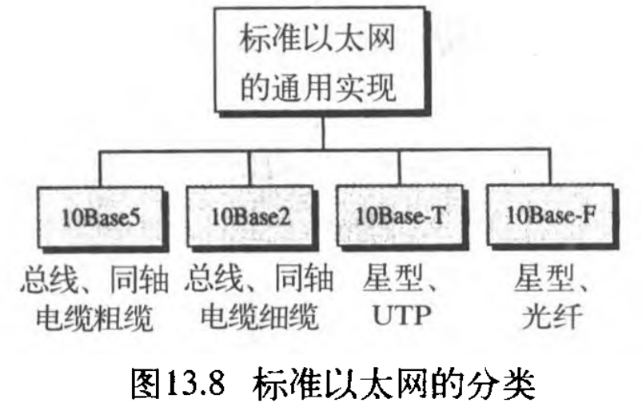
13.2.2 物理层
标准以太网定义了几种物理层的实现;如图13.8显示了其中最通用的四种。
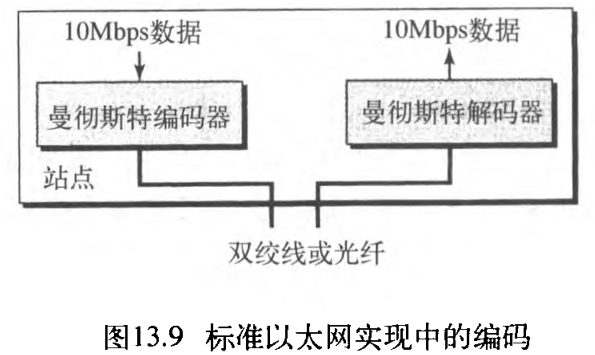
1. 编码和解码
所有标准的实现都使用
10
Mbps
10\textrm{Mbps}
10Mbps 的数字信号(基带)。在发送方,使用曼彻斯特方案将数据转换成数字信号,在接收方,信号又被转译成曼彻斯特码并被解码成数据。如在【计算机网络】第二部分 物理层和介质(4) 数字传输中看到的,曼彻斯特编码是自我同步的,在每一位的间隙提供一次转换。图13.9显示了标准以太网的编码图解。
2. 10Base5:粗缆以太网
第一个实现被称为 10Base5 ,粗缆以太网 thick Ethernet 或粗缆网 Thicknet 。这个别称是因电缆的粗细发展而来的,实际上粗略地说是橡胶软管的尺寸,并且非常坚硬不能用手弯曲。
10Base5是第一个以太网规范,它使用一个有外部收发器 transceiver(发送器/接收器)的总线拓扑,并通过一个外接口与粗轴电缆相连接。图13.10显示了一个10Base5实现的示意图。
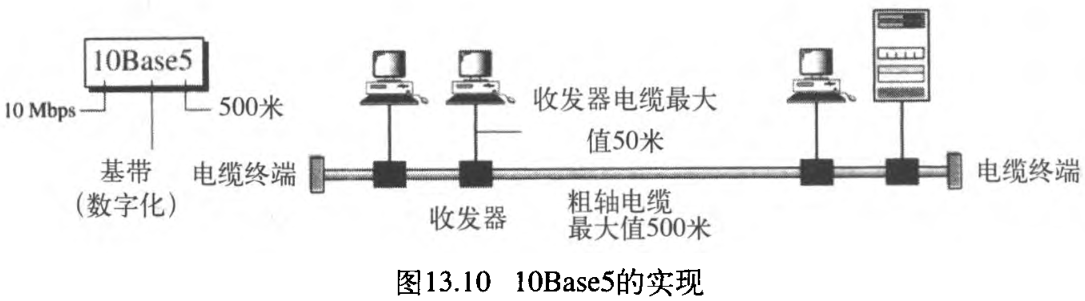
收发器负责传输、接收和检测冲突。收发器通过收发器电缆与站点连接,收发器电缆能为发送和接收提供独立的路径。这就意味着,冲突只会发生在粗轴电缆中。
粗轴电缆的长度最大不能超过 500 500 500 米,否则,便会出现信号的过分衰减。如果长度必须超过 500 500 500 米,最多分五个分段,每个分段的最大长度是 500 500 500 米,可以使用中继器连接。中继器在【计算机网络】第三部分 数据链路层(15) 连接局域网、主干网和虚拟局域网中介绍。
3. 10Base2:细缆以太网
第二个实现是 10Base2 ,细缆以太网 thin Ethernet ,或便宜网络 Cheapernet 。10Base2使用总线拓扑,电缆细多了但很有弹性。电缆可以被弯曲、以离站点很近。这种情况下,收发器通常是网卡 NIC 的一部分,被安装在站点内部。图13.11显示了一个10Base2实现的理论流程图。
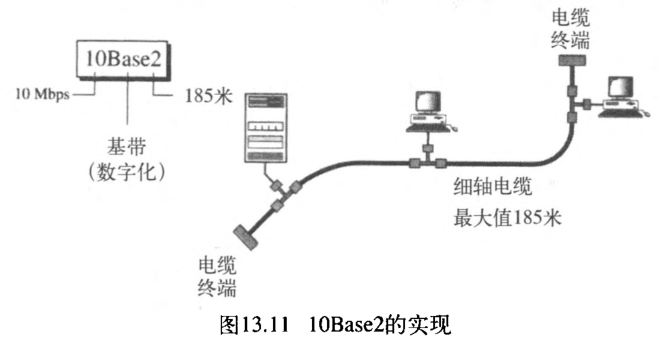
注意:这种情况下冲突发生在细轴电缆中。这个实现比10Base5的成本效益高,因为细轴电缆比粗轴电缆便直多了,且T型接口比分接头便宜。安装也因为细轴电缆的弹性变得简单多了。但是,因为细轴电缆中信号的高度衰减,每个分段的长度不能超过 185 185 185 米(接近 200 200 200 米)。
4. 10Base-T:双绞线以太网
第三个实现是 10Base-T 或者叫做双绞线以太网 twisted-pair Ethernet 。10Base-T使用物理星型拓扑结构,站点通过双绞线连接到一个网络集线器上,如图13.12所示。
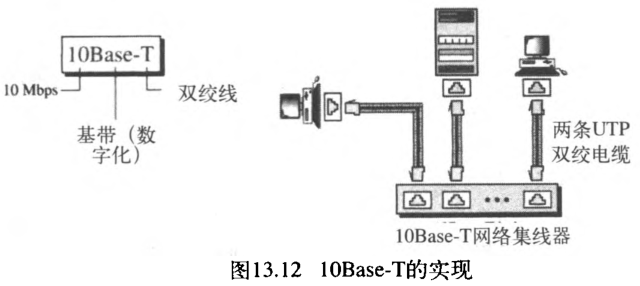
注意:双绞线在站点和网络集线器之间形成了两条路径(一条发送一条接收)。在这种情况下冲突发生在网络集线器中。与10Base5或10Base2相比较,可以看到就冲突而言,网络集线器实际上替代了同轴电缆的位置。双绞线的最大长度是
100
100
100 米,以使得双绞电缆的信号衰减最小。
5. 10Base-F:光纤以太网
虽然
10
10
10 兆光纤以太网有很多种类型,但其中最普遍的还是 10Base-F 。10Base-F使用一种星型拓扑,将站点与网络集线器相连接。如图13.13所示,站点使用两条光纤与网络集线器相连接。
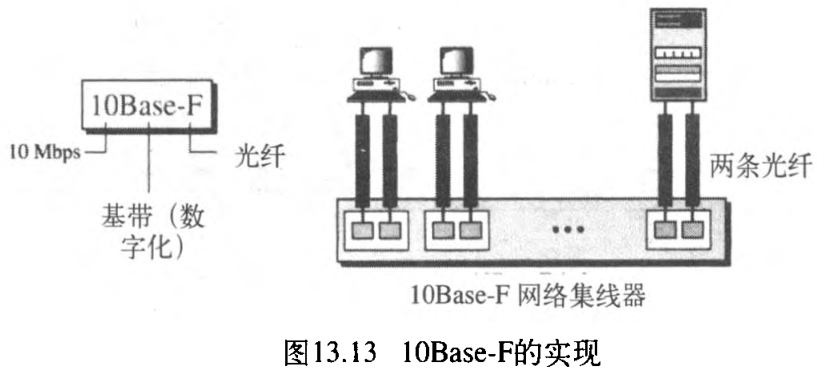
6. 总结
表13.1将标准以太网的实现做了一个总结。

13.3 标准的变化
10 Mbps 10 \textrm{Mbps} 10Mbps 标准以太网在升级为更高的传输速率之前,已经经历了一些变化。这些变化事实上为以太网的发展开辟了一条新路,使得与其他高传输速率的局域网相比,以太网变得更有竞争性。在这部分,介绍其中的一些变化。
13.3.1 桥接以太网
以太网发展的第一步是将局域网用网桥 bridge 分割。在以太局域网中,网桥有两个作用:提高带宽和分割冲突域。在【计算机网络】第三部分 数据链路层(15) 连接局域网、主干网和虚拟局域网介绍网桥。
1. 提高带宽
在非桥接以太局域网中,总能力
10
Mbps
10 \textrm{Mbps}
10Mbps 被所有要发送帧的站点共享,这些站点共享网络的带宽。如果只有一个站点要发送帧,它受益于总能力
10
Mbps
10 \textrm{Mbps}
10Mbps 。但是如果一个以上的站点要使用网络,能力就被共享了。例如,如果有两个站点要发送大量的帧,它们可能会轮流使用。当一个站点发送时,另一个站点停止发送。在这种情况下,可以认为平均每个站点发送的速度是
5
Mbps
5 \textrm{Mbps}
5Mbps 。图13.14说明了这种情况。
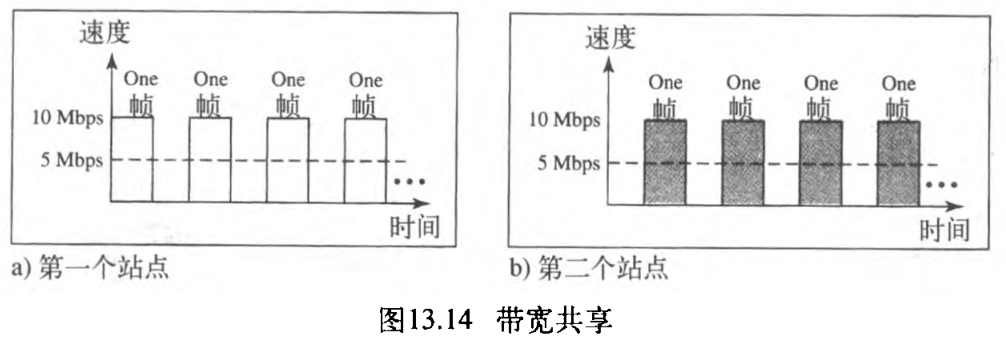
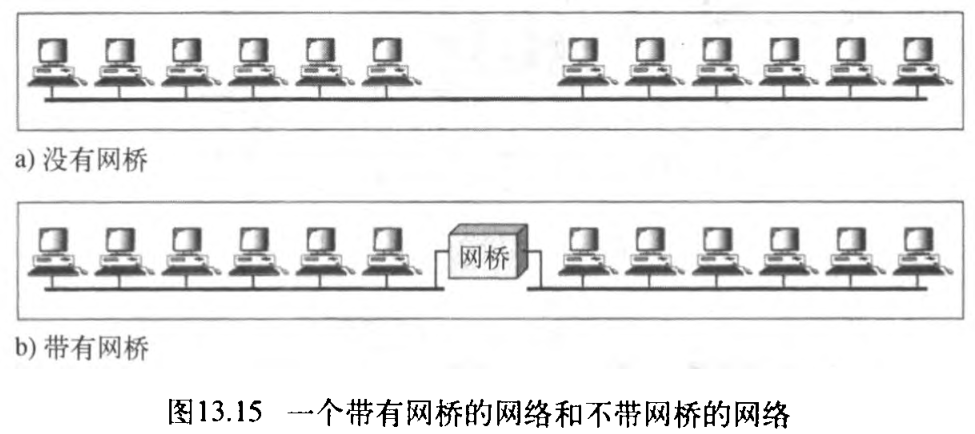
在【计算机网络】第三部分 数据链路层(15) 连接局域网、主干网和虚拟局域网中学到的网桥(类似两层交换机,可以过滤+转发帧)能在这里起作用,一个网桥将网络分成两个或更多的网络。
基于带宽,每个网络都是独立的。例如,图13.15中,一个有 12 12 12 个站点的网络被分成两个网络,每个网络有 6 6 6 个站点。每个网络的能力都是 10 Mbps 10\textrm{Mbps} 10Mbps 。 10 Mbps 10 \textrm{Mbps} 10Mbps 的能力在每个网络中被 6 6 6 个站点(实际上是 7 7 7 个,因为网桥在每个网络也算一个站点)所共享,而并非 12 12 12 个。在一个重负荷的网络中,假定流量并不经过网桥,每个站点理论上能达到 10 / 6 Mbps 10/6 \textrm{Mbps} 10/6Mbps 而不是 10 / 12 Mbps 10/12 \textrm{Mbps} 10/12Mbps 。
显而易见,如果进一步分割网络,能为每个部分得到更多的带宽。例如,如果使用一个四端口的网桥,每个站点能使用 10 / 3 Mbps 10/3 \textrm{Mbps} 10/3Mbps ,这是非桥接网络的 4 4 4 倍。
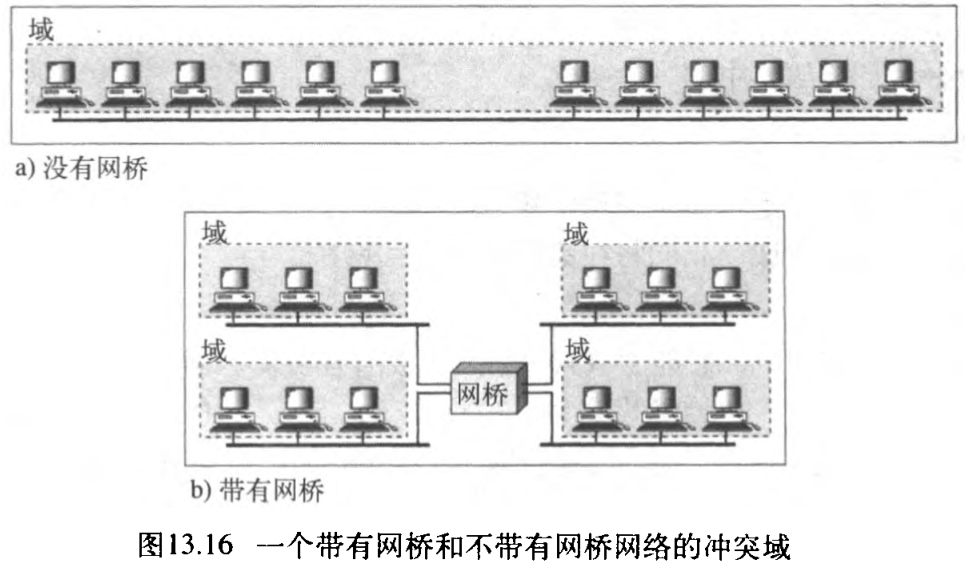
2. 分割冲突域
网桥的另一个优势就是分割冲突域 collision domain 。图13.16表示对于一个桥接网络和一个非桥接网络的冲突域的情况。从图中可以看到,在有桥接的情况下,冲突域会变得更小、而且冲突的概率大幅度减少。如果没有桥接,则有
12
12
12 个站点竞争访问介质,有了桥接之后,就只有
3
3
3 个站点竞争访问。
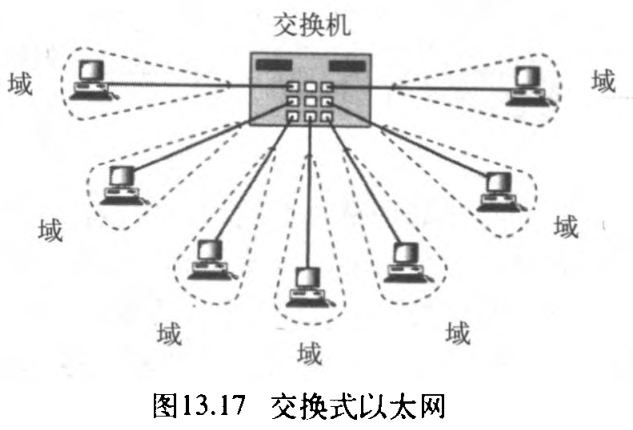
13.3.2 交换式以太网
桥接 LAN 的概念进一步扩展为交换 LAN 。与其将一个网络分割为
2
2
2 个到
4
4
4 个网络,为什么不将其分割成
N
N
N 个网络呢?这里的
N
N
N 是 LAN 上站点的个数。换句话说,如果有多个端口的网桥,为什么不能有
N
N
N 个端口的交换机呢?按这种说法,带宽仅由站点和交换机共享(每个
5
Mbps
5\textrm{Mbps}
5Mbps )。另外,冲突域也就分为
N
N
N 个。某种程度上,交换机使得「以太网局域网中的每个站点」都可以让自己获得整个网络的传输能力。
一个两层交换机 switch 就是一个
N
N
N 个端口的网桥,该网桥带有允许快速处理分组的附加功能。从桥接以太网到交换式以太网 switched Ethernet 的发展,对于开发更快的以太网是一个大的进步,正如将会看到的那样。图13.17表示一个交换 LAN 。
13.3.3 全双工以太网
10Base5和10Base2的一个局限,就是它们的通信是半双工的,10Base-T(和10Base-F)始终是全双工的。一个站点要么发送数据要么接收数据,但是不能同时进行。下一步就是从交换式以太网向全双工交换式以太网 full-duplex switched Ethernet 发展。
全双工模式将每一个域的能力从
10
Mbps
10\textrm{Mbps}
10Mbps 增加到
20
Mbps
20\textrm{Mbps}
20Mbps ,将每个域的传输能力翻倍,并取消了对CSMA/CD访问方法的需求。图13.18表示了在全双工模式下的交换式以太网。注意,在全双工模式的交换以太网中,在站点与交换机之间不是使用一条链路,而是使用两条链路:一个用于传送,另一个则用于接收。
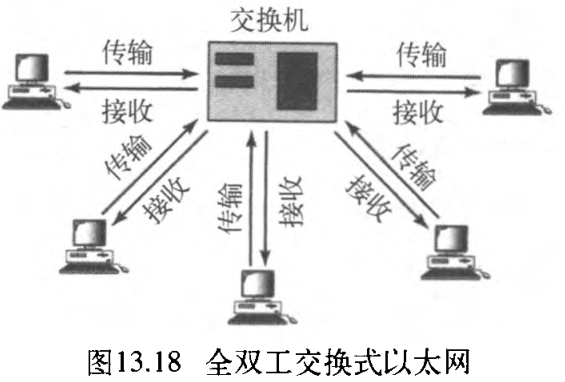
1. 不需要CSMA/CD
在全双工交换式以太网中,不需要CSMA/CD方法。在一个全双工交换式以太网中,每个站点都是通过两条分离的链路连接到交换机的。每个站点或交换机,都能够独立地发送或接收、而不必考虑冲突;在站点和交换机之间的每一条链路,都是点到点的专用链路,它们不再需要载波检测,也不再需要冲突检测。因此,MAC层的工作将变得更加容易,MAC子层的载波检测和冲突检测的功能可以不要了。
2. MAC控制层
标准以太网被设计为在MAC子层的无连接的协议,没有显式的流量控制和差错控制去通知发送方「帧已经无误地到达目的地」。在接收方接收到帧后,它不必发送肯定或否定的确认。为了在全双工交换式以太网中,提供流量控制和差错控制,在 LLC子层和MAC子层之间,又增加了一个新的子层,叫做MAC控制层 MAC control 。
13.4 快速以太网
设计快速以太网,是为了与诸如 FDDI 或光纤通道等的局域网协议相竞争。IEEE在802.3u 下创造了快速以太网。快速以太网是标准以太网的向后兼容,但是它的传输速度是
100
Mbps
100\textrm{Mbps}
100Mbps ,快了
10
10
10 倍。快速以太网的目标是:
- 将数据速率升级为 100 Mbps 100\textrm{Mbps} 100Mbps 。
- 使它能与标准以太网兼容。
- 保留 48 48 48 位地址。
- 保留相同的帧格式。
- 保留帧长度的最大值和最小值。
13.4.1 MAC子层
使以太网从 10 Mbps 10\textrm{Mbps} 10Mbps 向 100 Mbps 100\textrm{Mbps} 100Mbps 过渡,总的思想是不触及MAC子层。但做出的决定是放弃总线拓扑、而只保留星型拓扑。在星型拓扑中,正如我们之前介绍的,有两种选择:半双工和全双工。在半双工方法中,站点通过集线器连接;在全双工方法中,通过每个端口都带有缓冲区的交换机来进行连接。
对于半双工方法来说,访问方法是相同的(CSMA/CD)。对于全双工快速以太网而言,CSMA/CD是不必要的。然而,在实现时还是保留了CSMA/CD ,以便于和标准以太网向后兼容。
自动协商
快速以太网上增加的一个新特性就是自动协商 autonegotiation 。它允许一个站点或一个集线器有一定的能力范围。自动协商允许两个设备协商它们的运行模式和传输速率。它的设计更是处于以下的考虑:
- 为了使不兼容的设备间相互连接。例如,最大能力为 10 Mbps 10\textrm{Mbps} 10Mbps 的设备,可以和能力为 100 Mbps 100\textrm{Mbps} 100Mbps 的(在低速率下工作的)设备通信。
- 为了使一种设备有更多的功能。
- 为了使一个站点具有检测集线器的能力。
13.4.2 物理层
快速以太网的物理层比标准以太网复杂得多,随后将简要地加以介绍。
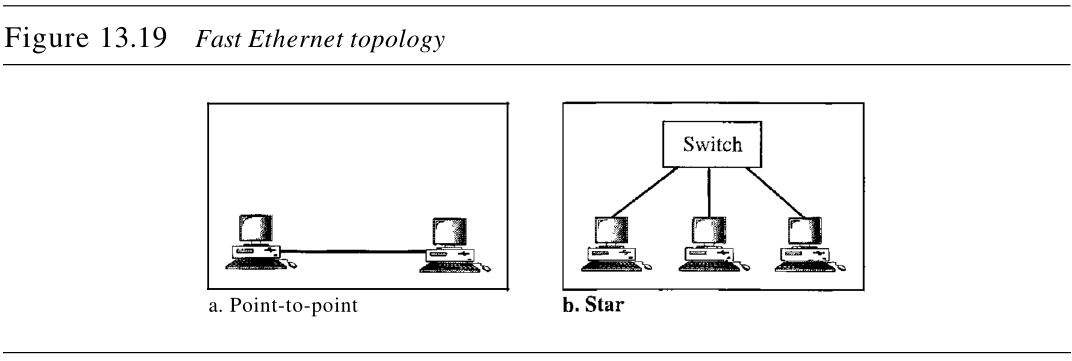
1. 拓扑结构
快速以太网被设计用来连接两个或两个以上的站点。如果只有两个站点,它们可以是点到点的连接。三个或三个以上的站点,就需要中间有一个集线器或交换机来连接,呈星型拓扑结构。如图13.19所示。
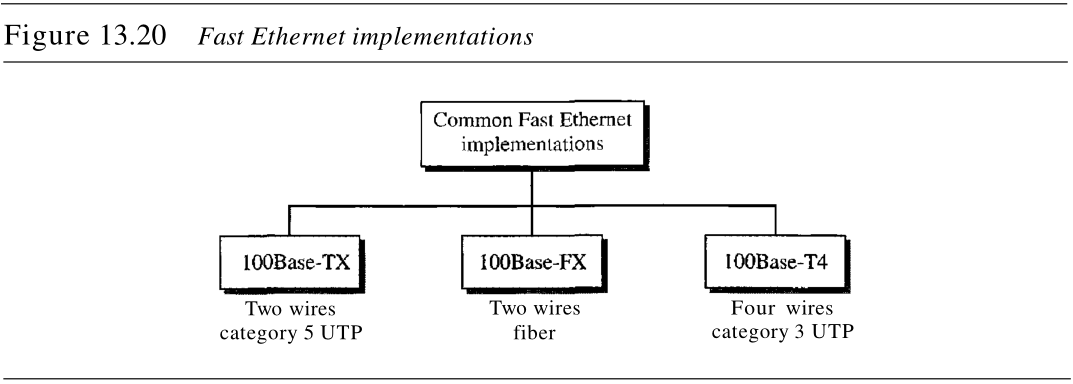
2. 实现
快速以太网在物理层的实现方式可分为两线或四线的。两线的实现可以是 5 5 5 类UTP(100Base-TX)或者光纤(100Base-FX)。而四线的实现则是仅有 3 3 3 类UTP(100Base-T4) 。如图13.20所示。
3. 编码
为了
100
Mbps
100\textrm{Mbps}
100Mbps 的传输速率,曼彻斯特编码需要
200
200
200 兆波特的带宽,这使得诸如双绞线这样的介质并不合适。因此,快速以太网的设计者寻求了其他可替代的编码/解码方案。然而,发现对于三种实现而言,一种编码方案的表现并不是同样的好。因此,选择了三种不同的编码方案(见图13.21)。
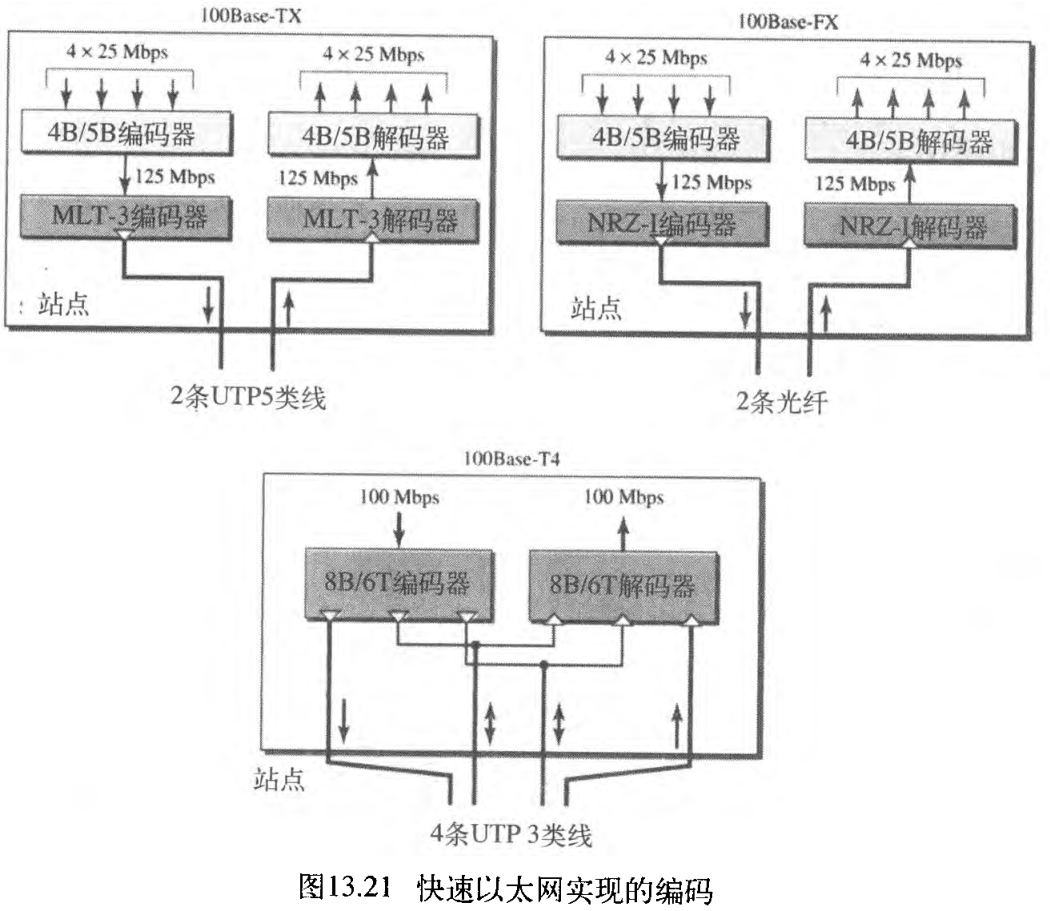
(1) 100Base-TX
对于这种实现而言,基于它有很好的带宽性能,选择 MLT-3 编码方案(见【计算机网络】第二部分 物理层和介质(4) 数字传输)。然而,MLT-3 却不是一个自我同步的线编码方案,故使用 4B/5B 块编码,通过防止长序列
0
0
0 和
1
1
1 的出现来实现位的同步。这将产生
125
Mbps
125 \textrm{Mbps}
125Mbps 的数据速率,并将其输入 MLT-3 进行编码。
(2) 100Base-FX
100Base-FX使用两条双光纤。通过使用简单的编码方案,光纤很容易就能满足高带宽的需求。100Base-FX的设计者,为这个实现选用了 NRZ-I 编码方案(见【计算机网络】第二部分 物理层和介质(4) 数字传输)。然而,NRZ-I 对于一长串的
0
0
0(或者
1
1
1 ,取决于编码)存在位同步的问题。为解决这一问题,设计者使用了与100Base-TX中相同的 4B/5B 块编码。块编码将比特率从
100
Mbps
100\textrm{Mbps}
100Mbps 提高到
125
Mps
125\textrm{Mps}
125Mps ,但对于光纤而言这很容易解决。
(3) 100Base-TX
网络能提供
100
Mbps
100\textrm{Mbps}
100Mbps 的传输速率,但需要使用
5
5
5 类UTP或者STP电缆。这对于已经安装了 voice-grade twisted-pair (category 3) 的建筑物,成本效益较低。一个称为100Base-T4的新标准,是为了使用
3
3
3 类或更高的UTP而设计的。为达到传输速度
100
Mbps
100\textrm{Mbps}
100Mbps ,这个实现要用四条UTP。
100Base-T4的编码/解码也复杂得多。因为该实现使用
3
3
3 类 UTP ,每条双绞线都不能轻松应对超过
25
M
25\textrm{M}
25M 波特的带宽。在这个设计中,在发送和接收之间有一对交换机。然而,三条
3
3
3 类UTP也只能处理
75
M
75\textrm{M}
75M 波特(每条
25
M
25\textrm{M}
25M 波特)。我们需要使用一个编码方案将
100
Mbps
100\textrm{Mbps}
100Mbps 转换成
75
M
75\textrm{M}
75M 波特的信号。正如【计算机网络】第二部分 物理层和介质(4) 数字传输中所介绍的,8B/6T 满足了这一需求。在 8B/6T 中,
8
8
8 个数据元素被编码成
6
6
6 个信号元素。这就意味着
100
Mbps
100\textrm{Mbps}
100Mbps 只需要
6
/
8
×
100
Mbps
6/8\times 100\textrm{Mbps}
6/8×100Mbps ,即
75
M
75\textrm{M}
75M 波特。
4. 总结
表13.2是对快速以太网实现的一个总结。

13.5 干兆以太网
对传输速度更高的需求,使得千兆以太网
1000
Mbps
1000\textrm{Mbps}
1000Mbps 应运而生。IEEE委员会称之为标准 802.3z 。千兆以太网设计的目标可总结如下:
- 将数据速率升级到 1 1 1 千兆。
- 使其与标准以太网或快速以太网相兼容。
- 使用相同的 48 48 48 位地址。
- 使用相同的帧格式。
- 保留帧长度的最大值和最小值。
- 支持快速以太网中定义的自动协商。
13.5.1 MAC子层
有关以太网发展的总的思想是尽量不触及到 MAC子层,但在实现
1
Gbps
1\textrm{Gbps}
1Gbps 的速率发送时,这种想法就不现实了。千兆以太网在介质访问方面有两个独特的方法:半双工或全双工方法。几乎所有的千兆以太网的实现都采用了全双工方法。然而,这里会简要地介绍半双工方法,以说明千兆以太网与前几代以太网是可以兼容的。
13.5.2 全双工模式、半双工模式
在全双工模式中,有一个中心交换机(全双工交换式以太网)将所有的电脑或其他交换机连接起来。每个交换机的每个进入端口都有缓存区,使数据在传输前得以存储。正如之前讨论的那样,在这种模式中不存在冲突。也就是说CSMA/CD是不必要的。缺少冲突意味着,电缆长度的最大值取决于电缆中信号的衰减程度,而不是冲突检测过程。
千兆以太网也能使用半双工模式,虽然事实上很少用到。在这种情况下,交换机被集线器所替代,集线器作为普通电缆的一部分就可能有冲突产生。半双工方法使用CSMA/CD。然而,正如我们之前所介绍的,这种方法下,网络的最大长度完全取决于帧大小的最小值。于是,定义了三种方法:传统方法,载波扩展方怯和帧突发方法。
- 传统方法:在传统方法中,保留了与传统以太网中相同的帧长度的最小值 512 512 512 位。然而,因为在千兆以太网中一位的长度是 10 Mbps 10\textrm{Mbps} 10Mbps 以太网中的 1 / 100 1 /100 1/100 ,因此千兆以太网的时隙时间是 512 bits × 1 / 1000 μ s 512\textrm{bits} \times 1 / 1000μs 512bits×1/1000μs ,即为 0.512 μ s 0.512μs 0.512μs 。时隙时间的减短,意味着能快 100 100 100 倍的时间检测到冲突。这就是说网络的最大长度是 25 25 25 米。这个长度也许对在一个房间内的所有站点是合适的,但也许还不足以长到可以连接一个办公室的所有电脑。
- 载波扩展方法:为了适应更长的网络,增加了帧长度的最小值。载波扩展方法定义的帧长度的最小值是 512 512 512 字节( 4096 4096 4096 位),即长度最小值是以前的 8 8 8 倍。这个方法使得站点给不满 4096 4096 4096 位的帧,增加了扩展位(填充)。在此方法中,网络长度的最大值也扩大了 7 7 7 倍,即 200 200 200 米。这就允许从集线器到站点的长度可以是 100 100 100 米。
- 帧突发方法:如果要发送的帧都比较短,那么载波扩展方法是非常低效的,因为每个帧都承载了冗余的数据。为了提高效率,提出了帧突发方法。在此方法中,发送成倍的帧、而不是给每个帧增加扩展。然而,为了使成倍的帧看上去像一个帧,要在帧间加以填充(这与载波扩展方法中的一样)而使通道不会空闲下来。换言之,这个方法使得其他的站点认为「有一个非常大的帧正在传输」。
13.5.3 物理层
千兆以太网的物理层比标准以太网或者快速以太网的物理层复杂得多。在此仅简要地讨论其中的某些特性。
1. 拓扑结构
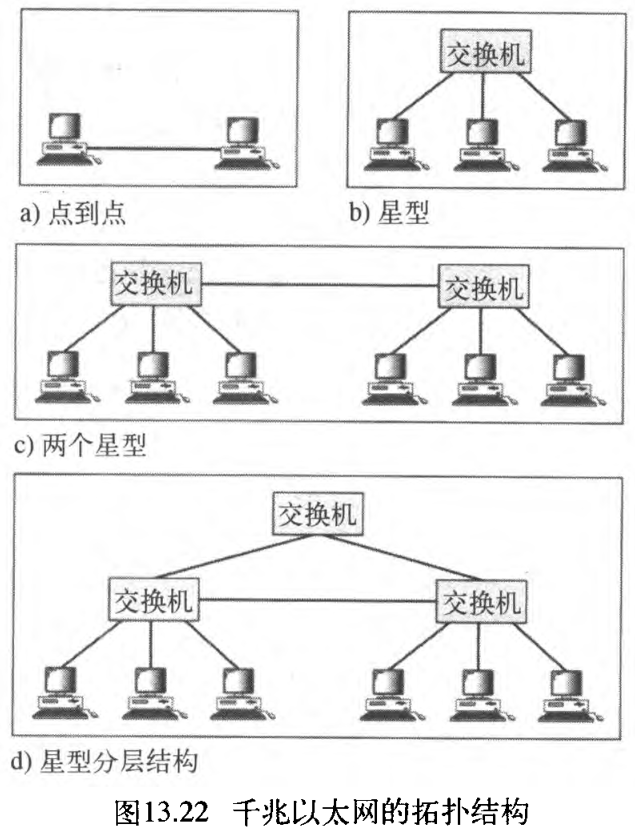
千兆以太网被设计用来连接两个或两个以上的站点。如果只有两个站点,它们可以是点到点的连接。三个或三个以上的站点就需要有一个集线器或交换机来连接,呈星型拓扑结构。另一种可行的配置是,将几个星型拓扑连接起来、或使得一个星型拓扑是另一个星型拓扑结构的一部分,如图13.22所示。
2. 实现
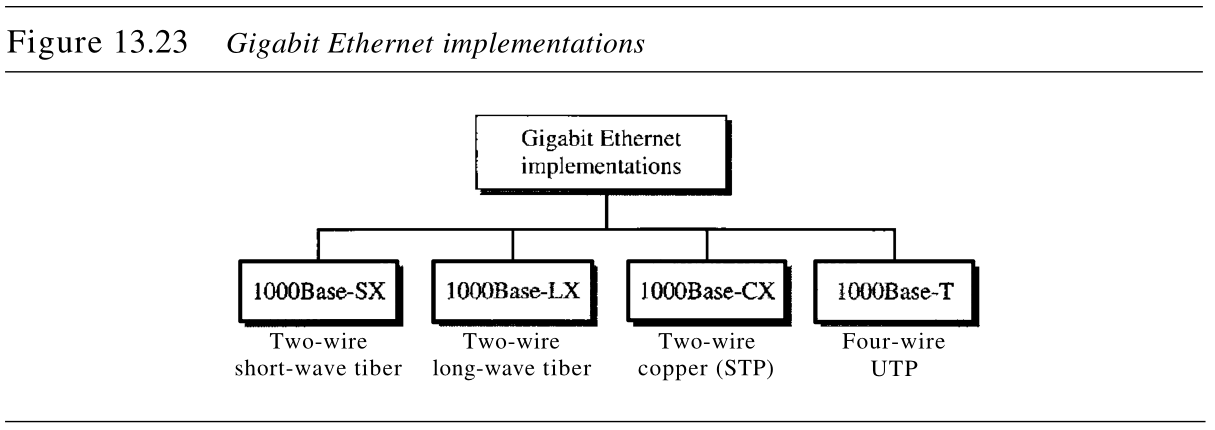
千兆以太网可以分为两线或四线的实现。两线的实现使用光纤(1000Base-SX,双光纤和短波激光源或1000Base-LX,双光纤和长波激光源)或STP(1000Base-CX)。四线的实现使用
5
5
5 类双绞线电缆(1000Base-T)。换言之,可以有四种实现,如图13.23所示。
1000Base-T的设计是为了满足某一类用户,这类用户已经为其他诸如快速以太网或电话服务等目的,进行了线路安装。
3. 编码
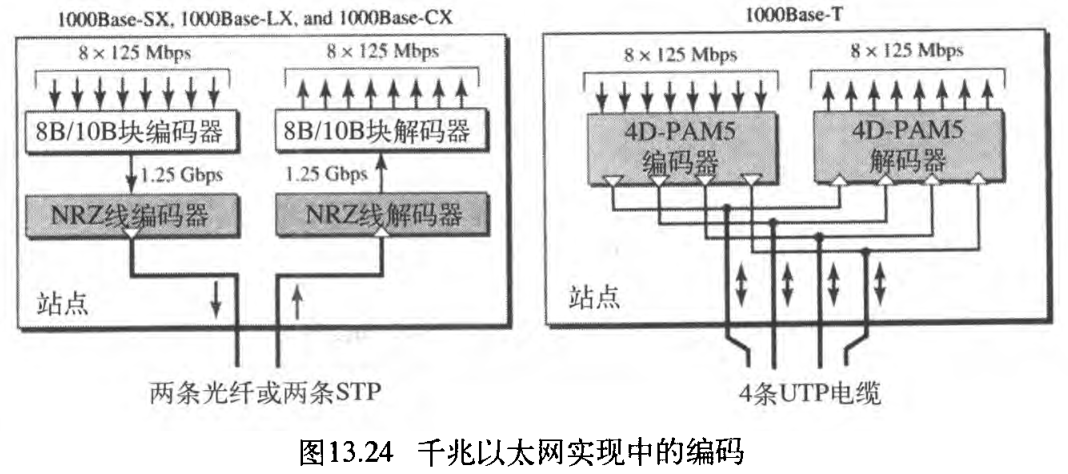
图13.24描述了这四种实现的编码/解码方案。
千兆以太网因为涉及的带宽太大(
2
G
2\textrm{G}
2G 波特),故不能使用曼彻斯特编码方案。两线实现使用 NRZ 方案,但是 NRZ 无法正确地进行自同步。为了实现位的自同步,特别是为了适应如此高的传输速率,使用了 8B/10B 块编码(见【计算机网络】第二部分 物理层和介质(4) 数字传输)。块编码避免了在数据流中出现长串的
0
0
0 或
1
1
1 ,但产生的数据流是
1.25
Gbps
1.25\textrm{Gbps}
1.25Gbps 。注意在此实现中,一条线路(光纤或STP)用来发送而另一条用来接收。
在四线实现中,因为每条线路要承载
500
Mbps
500\textrm{Mbps}
500Mbps ,这已经超出了
5
5
5 类UTP的承载能力,故更不可能让两条线路专门发送而让另两条专门接收。作为一个解决方案,使用了 4D-PAM5 编码方法来减小带宽(见【计算机网络】第二部分 物理层和介质(4) 数字传输)。该实现中的
4
4
4 条线路既用来输出又可用来输入,每条线路承载
250
Mbps
250\textrm{Mbps}
250Mbps ,这是在
5
5
5 类 UTP的承载能力范围内的。
4. 总结
表13.3对千兆以太网的实现作了一个总结。

13.5.4 10干兆以太网
IEEE委员会创造了
10
10
10 千兆以太网并称之为标准 802.3ae 。
10
10
10 千兆以太网的设计目标可总结如下:
- 将数据速率提升为 10 Gbps 10\textrm{Gbps} 10Gbps 。
- 使其与标准以太网、快速以太网和千兆以太网相兼容。
- 使用相同的 48 48 48 位地址。
- 使用相同的帧格式。
- 保留帧长度的最大值和最小值。
- 允许将现有的局域网与城域网
MAN或广域网WAN相互连接。 - 使得以太网与诸如帧中继和ATM(见第18章)等的技术相兼容。
1. MAC子层
10 10 10 千兆以太网只在全双工模式下运行,这意味着不存在竞争。 10 10 10 千兆以太网也不使用CSMA/CD。
2. 物理层
10 千兆以太网物理层的设计目标是在长距离内使用光纤。最常见的三种实现是:10GBase-S, lOGBase-L, 10GBase-E 。表13.4是对 10千兆以太网实现的总结。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











