







题目是这样的:给定一个单向链表,遍历一遍,从中选出M点,要求每个节点被选中的概率相同。
这主要是一个概率论的问题,既然是单向链表,分两种来讨论
1.如果我们事先就知道链表的长度
那么这个问题就变为一个经典的抽签问题--在不知道前面人抽到的结果情况下,每个人抽中奖的概率是一样的
证明如下:
(1).假设一个票箱里面有N张票,其中M张是奖票,那么第一个人抽中的概率是M/N,抽不中的概率是(N-M)/N
(2).第二个人来抽签,他不知道前面一个人抽中否,如果第一个人抽中,那么奖票少了一张,他中奖的概率为(M-1)/(N-1),前面一个人没有中奖,他中奖的概率为M/(N-1),那么由全概率公式得到他中奖的概率为 M/N * (M-1)/(N-1)+(N-M)/N * M/(N-1),可以算一下结果为 M/N,也就是说第二个和第一个中奖的概率是一样的。
然后以此类推,这是一个古典概率类型。
2.不知道链表长度。
这个在很多场合都是有用的,比如一个网站每天的访问量是不确定的,要从每天访问的URL里面尽可能公平的抽出一些来进行分析。
如果不知道总长度,我们在任意时刻可以知道已经访问了多少节点了,即为now,以及我们需要抽取的数目m,我们每次可以以m/now的概率来确定是否需要保存当前的节点。但是问题出现了,一个节点在当前如果被保存了那么显然对于越往后的节点越不公平,因为随着now的增加,它们的now'>now,所以显然被选中的概率会变小。
看到m/now,我们会思考,怎么样保证在now'->now+1后更新所有被选中的概率呢?最好这个因子是now/now',因为这样更新后的每个节点的概率就依然会保持m/now',这样一想就可以这样,每次同样以m/now'选择节点,如果被选中,就将原来被选中的任意一个替换掉。这样一来,每个之前保存的节点不被替换掉的概率是m/now * now/now'=m/now',也就是说继续保持选择状态全部更新为m/mow'。这样随着递增,每个节点被选中的概率一直都是m/now,保证了公平性。
以下是实现中的关键代码:
int PickNode(node *head,int count)
{
if(head==NULL||count<0)
return -1;
node *p=head;
int total=0; //记录目前统计的数目
int *data=new int[count]; //从中抽多少个数据
int pos;
int range; //结果统计区间
srand((unsigned)time(NULL));
while(p!=NULL)
{
total++;
pos=ulrand()%total;
if(pos<count)
data[pos]=p->value;
p=p->next;
}
cout<<"生成完毕,设定统计区间"<<endl;
cin>>range;
int temp=total/range;
int *sta=new int[temp];
for(int i=0;i<temp;i++)
sta[i]=0;
for(int i=0;i<count;i++)
sta[data[i]/range]++;
for(int i=0;i<temp;i++)
cout<<i*range<<"~"<<(i+1)*range<<"段:"<<sta[i]<<endl;
return 0;
}产生大随机数的方法先产生一个小的随机数,然后将产生的随机数组合起来:
unsigned long ulrand(void) {
return (
(((unsigned long)rand()<<24)&0xFF000000ul)
|(((unsigned long)rand()<<12)&0x00FFF000ul)
|(((unsigned long)rand() )&0x00000FFFul));
}先输入队列长度,要选出的元素个数,然后筛选完毕,统计各个数段的个数,看是否均匀。以1千万为长度,然后以50万为区间进行统计。结果如下:
抽取10000个元素: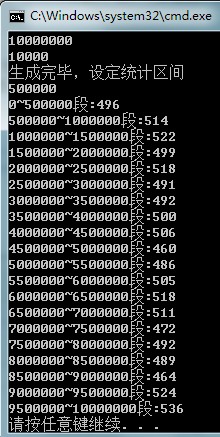
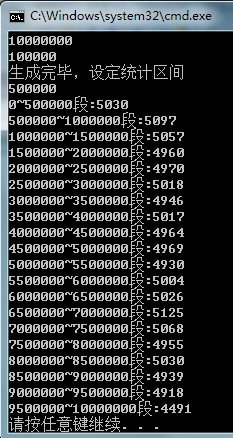
另外还有一个要注意,在生成随机数的时候,如果直接调用rand(),需要为它指定参数,以得到不同的随机序列,另外他生成的随机数受stdlib.h中定义的RAND_MAX限制,如果要生成足够大的随机数应该生成几次,然后取它的不同位赋给一个新的数,比如第一次生成的低10位对应新数的低10位,第二次对应11~20位,依此类推,这样就可以得到一个足够大的随机数了。















 8299
8299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









