







Tire树 又称字典树
Tire树 核心的思想是以空间换时间,每个节点下面分26叉,需要统计一个单词比如abc,这时候先找根节点,然后由a分支到a节点,然后在a节点里面找b分支,然后到b节点去找c分支,最后将该节点的单词计数器加1.
1.Tire树每个节点的定义
class TireNode
{
public:
char c;
int count;
TireNode *next[26];
TireNode()
{
c='0';
count=0;
for(int i=0;i<26;i++)
next[i]=NULL;
}
~TireNode()
{
for(int i=0;i<26;i++)
if(next[i]!=NULL)
delete next[i];
}
};2.Tire树遍历
在统计完节点后,对其遍历,目前我只弄了一个递归的遍历,过几天研究非递归的遍历
在遍历的过程中同时用一个最小堆保存当前的出现频率最高的单词,如果一旦新遍历的单词出现的次数大于堆顶元素,更新堆
算法描述
1.给定Tire树节点,如果该节点为NULL返回
2.将其节点字母压栈,如果该节点计数器不为0,记录之,并且利用该信息更新堆操作
3.以本方法遍历其26个后继节点
4.弹栈操作
void Travel(TireNode *node)
{
if(node==NULL)
return;
stk.PushIn(node->c);
if(node->count!=0)
{
stk.PrintStack(node->count);
heap.CMP(node->count,stk.GetTrace());
}
int i=0;
for(;i<26;i++)
Travel(node->next[i]);
stk.Pop(); //这里注意弹栈不要影响将来遍历的轨迹
}
3.在遍历的过程中对于更新堆的思路
1.建立一个 出现次数--单词 的映射,每次调整堆的时候,单词也要交换,但是这样做复制单词比较耗时
2.在1的基础上建立两层映射 出现次数---索引---单词,这样一来每次每次只有在更新堆的时候有单词的复制,在调整堆的时候只需要将索引和次数一起调整即可,不用额外去复制单词。实现如下所示
void shift(int low,int high) //堆排序调整
{
int temp[1][2];
temp[0][0]=map[low][0]; //记录次数
temp[0][1]=map[low][1]; //记录索引
int i=low;
int j=2*i;
int k;
bool finshed=false;
while(j<=high&&!finshed)
{
if(j<high&&map[j+1][0]<map[j][0])
j=j+1;
if(map[i][0]<map[j][0])
finshed=true;
else
{
k=map[i][0];
map[i][0]=map[j][0];
map[j][0]=k;
k=map[i][1];
map[i][1]=map[j][1];
map[j][1]=k;
i=j;
j=2*i;
}
}
map[i][0]=temp[0][0];
map[i][1]=temp[0][1];
}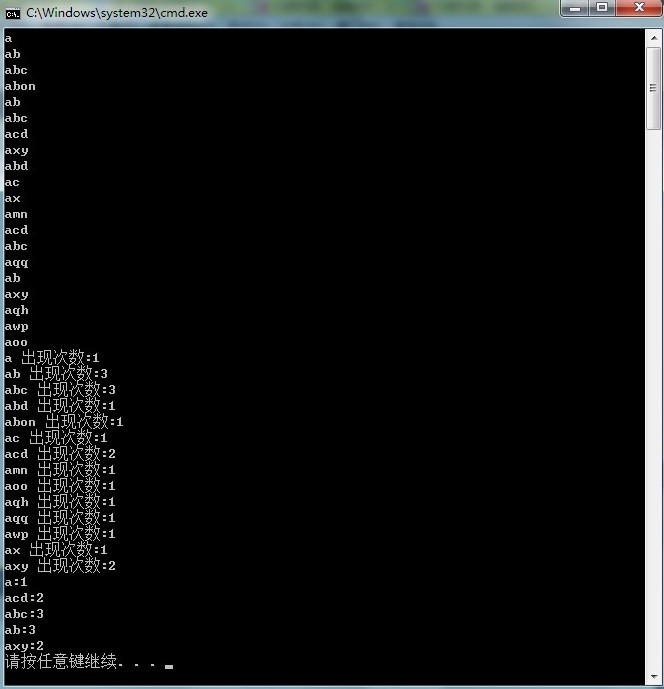
Tire树在实际应用中一般用于查找单词的前缀,统计单词的出现的次数,Baidu 的Suggestion的实现就是基于Tire树的。
4.复杂度分析
Tire树在查找时同时可以完成插入操作,因此完成统计用时为O(N*len)
遍历的时候最坏情况下每次都要更新堆,用时为O(N*(logK+len))
5.在实现中遇到的问题
1.在字符串拷贝时候自增计数器要加上
2.堆排序在计算下标时候用到乘法,方便起见,下标从1开始而不是0
3.在调用函数时分配在栈上面的变量是不能返回的如 char str[20]















 3824
3824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









