







一、 查找无用对象
垃圾回收的第一个步骤就是查找可回收对象实例,即不可能再被任何途径使用的对象。算法有 引用计数算法和可达性分析算法。
1. 引用计数算法
为每个对象添加一个引用计数器,每当有一个地方引用它,计数值加1;引用失效时,计数值减1.计数器为0时,对象不可能再被使用。
优势: 实现简单,判定效率高。
弊端: 无法解决对象间互相循环引用的问题
2. 可达性分析算法
通过一系列"GC Root"的对象为起点,往下搜索,搜索所走过的路径称为"引用链"。一个对象在 GC Root的引用链中没有相连,则对象不可用。
二、垃圾收集算法
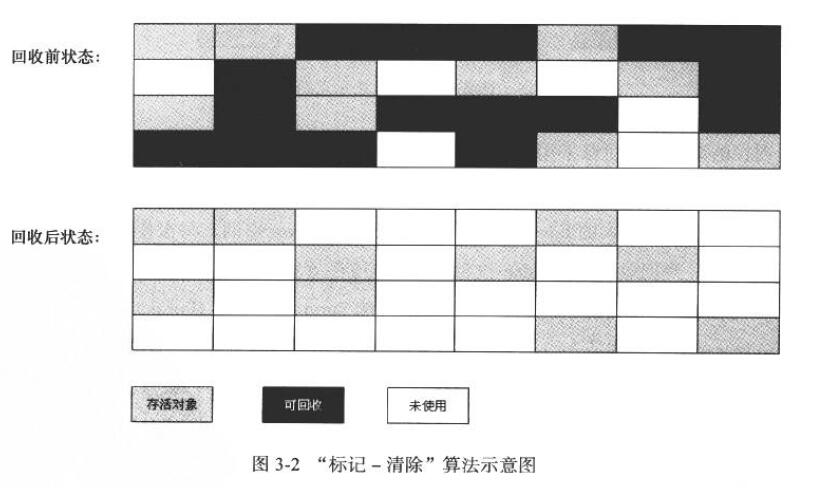
1. 标记-清除算法
最基础的收集算法。分两个阶段: 标记和收集。
弊端: 1. 标记和清除 这两个过程效率都不高
2. 清除后产生大量不连续的内存碎片
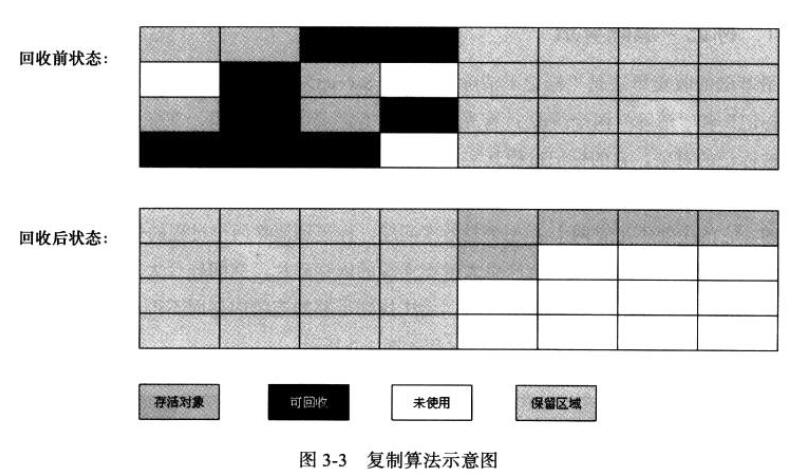
2. 复制算法
将内存按容量划分为大小相等的两块,每次只使用其中一块。当一块的内存用完,就将还存活的对象复制到另一块上,再把第一块内存空间清理掉。
弊端:将内存缩小了原来的一半
由于新生代的对象98%是"朝生夕死"的,所以并不需要按照1:1的比例划分内存空间。
将内存分为一个较大的Eden空间和两块较小的Survivor空间。 每次使用Eden和其中一块Survivor空间。回收时,将Eden和Survivor中还存活的对象复制到另一块Survivor中。最后清理掉Eden和用过的Survivor空间。
HotSpot虚拟机默认Eden和Survivor的大小比例是8:1
当Survivor空间不足时,进行分配担保,直接进入老年代。
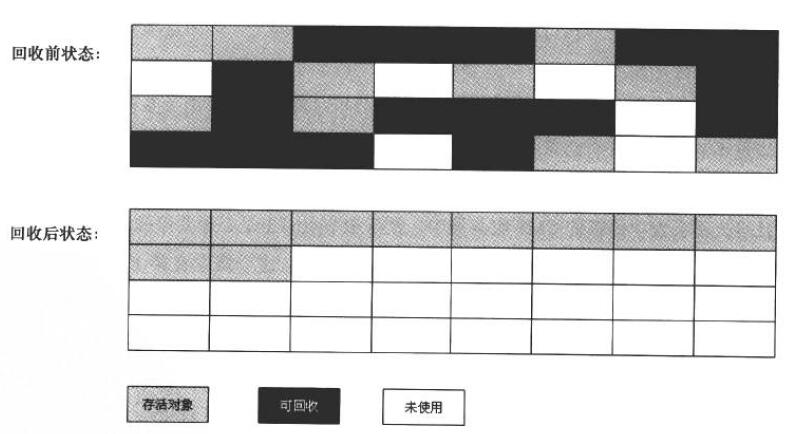
3. 标记-整理算法
标记完成后,让所有存活的对象都向一端移动,然后清理掉 端边界以外的内存。
4. 分代收集算法
将Java堆分为新生代和老年代。 在新生代使用 复制算法,在老年代使用 标记-清除 或者 标记-整理算法。
三、垃圾收集器
垃圾收集器是 垃圾收集算法的具体实现。
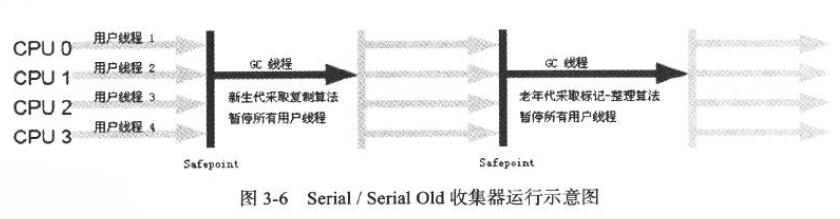
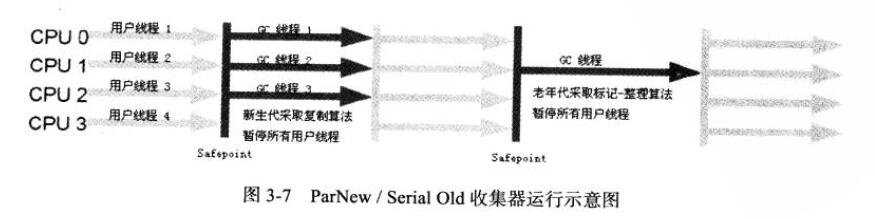
1. Serial 收集器
单线程收集器,新生代采取复制算法,老年代采取标记-整理算法。垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束。
2. ParNew 收集器
Serial 收集器的多线程版。
3. Parallel Scavenge收集器
新生代收集器,主要目标是达到一个可控制的吞吐量。吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)
4. Serial Old收集器
Serial收集器的老年代版本。
5. Parallel Old收集器
Parallel Scavenge收集器的老年代版本。
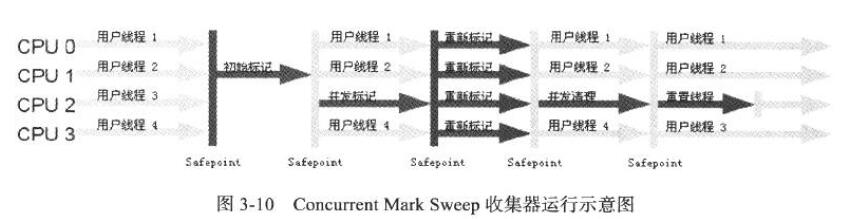
6. CMS(Concurrent Mark Sweep)收集器
CMS收集器是一种以获取最短回收停顿时间为目标的收集器。
CMS收集器基于"标记-清除"算法实现,整个过程分为4个步骤: 初始标记、并发标记、重新标记、并发清除。其中 并发标记和并发清除可以与用户线程一起工作。
弊端:1. 对CPU资源非常敏感。 在并发阶段,占用了部分线程,导致应用程序变慢,总吞吐量降低。CMS默认启动回收线程数是 (CPU数量+3) / 4
2. 无法处理浮动垃圾。 在CMS并发清理阶段用户线程产生的新垃圾,出现在标记过程中,CMS只能留待下次GC时处理掉。这些垃圾就是浮动垃圾
3. CMS采用的"标记-清除"算法,收集结束后会产生大量的空间碎片。
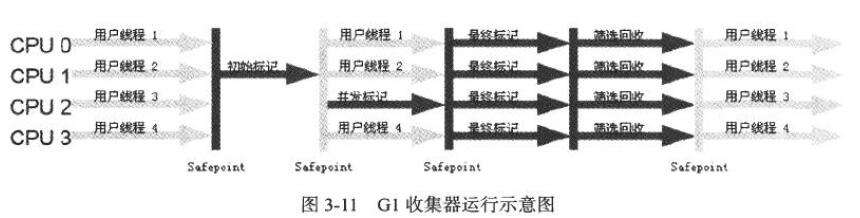
7. G1收集器
G1收集器是一款面向服务端应用的垃圾收集器。主要特点有: 并行和并发、分代收集、空间整合、可预测停顿。
G1收集器之前的其他收集器 的收集范围都是整个新生代或者老年代。但G1将整个Java堆划分为多个大小相等的独立区域(Region)。
G1收集器大致执行步骤为: 初始标记、并发标记、最终标记、筛选回收。
四、内存分配与回收策略
1. 对象优先在Eden分配。 当Eden区空间不足时,将发起一次Minor GC(新生代垃圾回收)
2. 大对象直接进入老年代
3. 长期存活对象将进入老年代。默认经过15次 Minor GC则晋升到老年代中。如果 Survivor空间中相同年龄的所有对象大小总和大于Survivor空间的一半,年龄大于等于该年龄的对象可直接进入老年代。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









