







ScalersTalk成长会机器学习小组第7周学习笔记
本周主要内容
- 优化目标
- 最大间隔
- 最大间隔分类的数学背景
- 核函数
I
- 核函数
- 使用支持向量机
本周主要知识点:
一、优化目标
- 从另一个角度看logistic回归
hθ(x)=1(1+e−θTx)
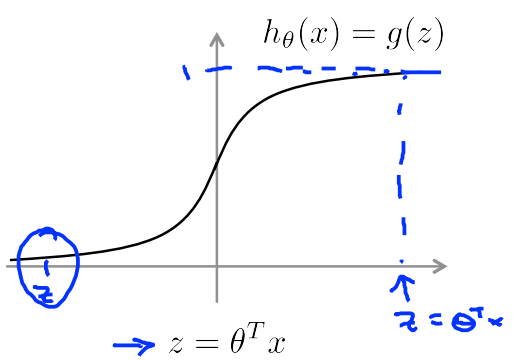
if
y=1
, 我们需要
hθ(x)≈1,θTx>>0
if
y=0
, 我们需要
hθ(x)≈0,θTx<<0
- 从另一个角度看logistic回归
- 损失函数:
−(yloghθ(x))+(1−y)log(1−hθ(x))
=−ylog11+e−θTx+(1−y)log(1−11+e−θTx)
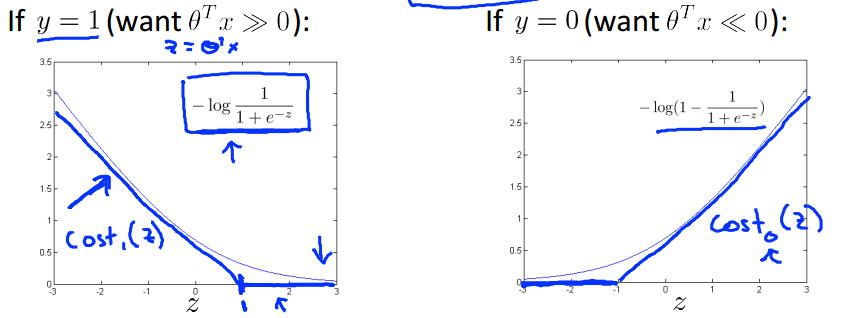
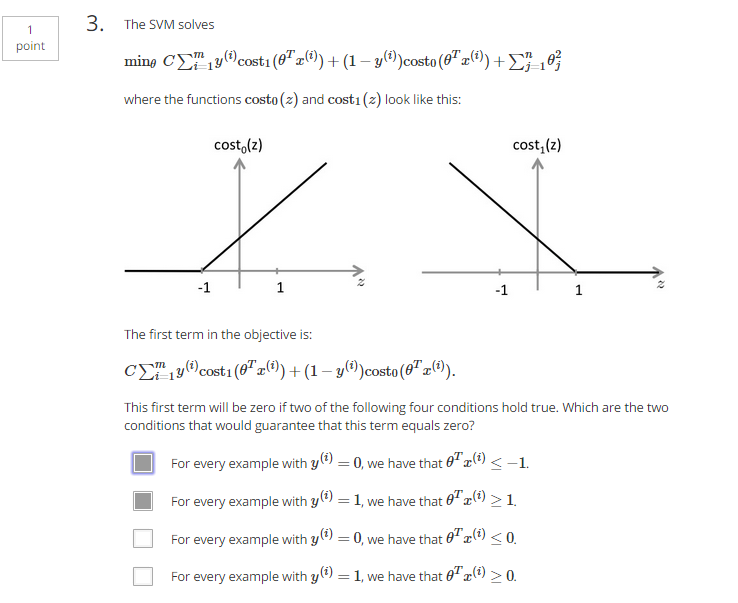
- 支持向量机和logistic回归损失函数:
logistic回归:
支持向量机:

二、最大间隔的含义
- 优化求解目标函数:
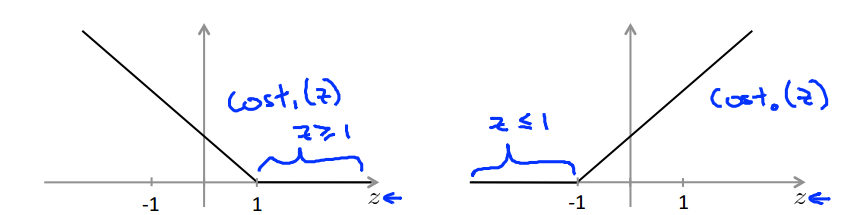
if
y=1
, 我们需要
θTx≥1,而不是≥0
if
y=0
, 我们需要
θTx≤−1,而不是≤0
- 支持向量机的决策边界:
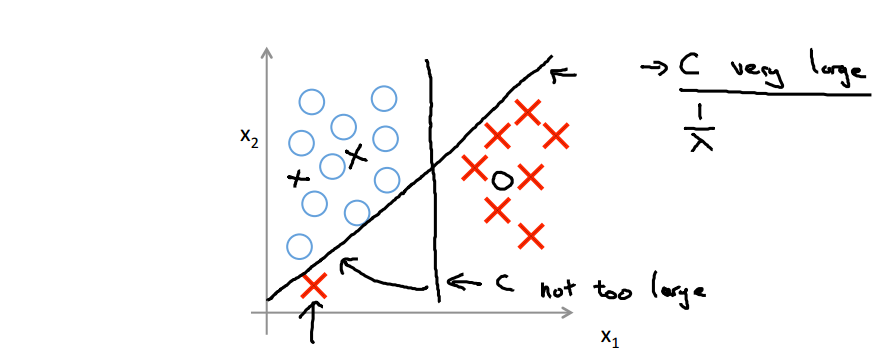
当C为一个很大的值:

- 支持向量机:线性可分场合
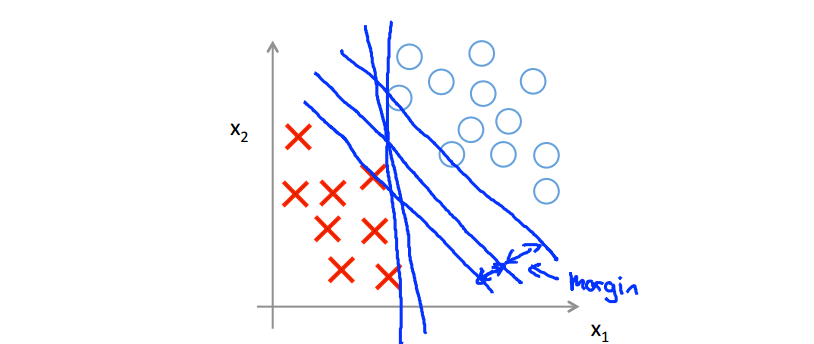
- 支持向量机:最大间隔在存在异常值场合
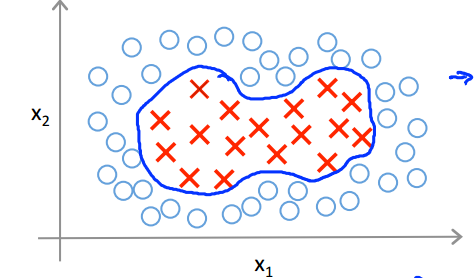
四、核函数
I
- 非线性决策边界:
- 模型预测:
对样本进行预测,具有下面形式:
if
这里由于是多项式展开形成的特征,一下子计算量变得不可估计,看看如何通过核函数来降维。
- 核函数:
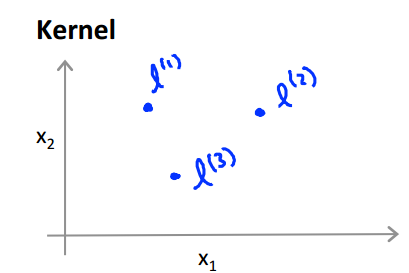
给定 x 场合,计算一个新的特征,这个特征依赖于其临近的标记点:
给定 x 场合:
- 核函数和相似度函数:
在给定 x 临近
在给定 x 远离
- 核函数例子:
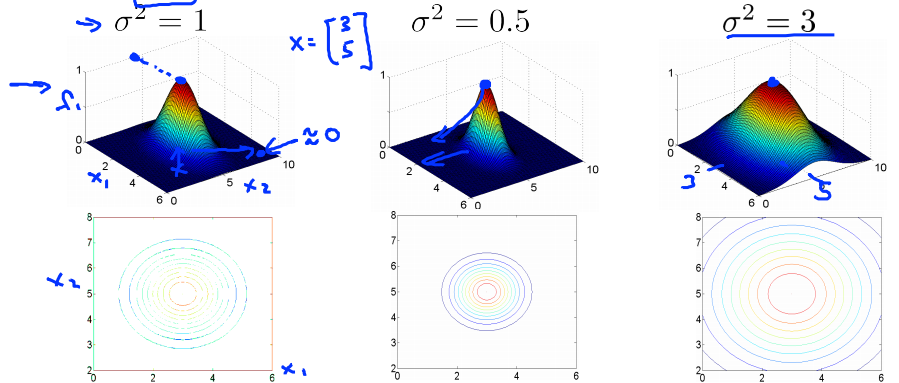

f1≈1
,
f2≈0
,
f3≈0
对于靠近
l(1)
的点计算等式:
对于远离 l(1) 、 l(2) 、 l(3) 的点计算等式:
五、核函数 II
- 如何选择标记点:
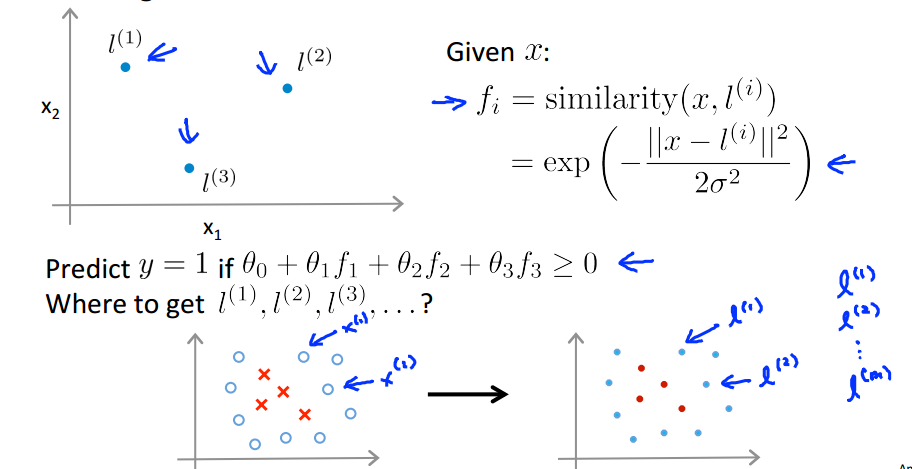
- SVM的核函数:
- SVM的核函数:
大家还记得线性不可分时的SVM那张图,特征的维数灾难通过核函数解决了。
公式最右侧的 12∑jmθ2j 被替换成立 θTMθ ,这样是为了适应超大的训练集。 - SVM的参数选择:
六、使用SVM - 使用软件包来求解参数
θ
:
- 核函数的相似度函数如何写:
记得在使用高斯核函数时不要忘记对特征做归一化。 - 其他的核函数选择:
并不是所有的核函数都合法的,必须要满足Mercer定理。 - 多项式核:
衡量x与l的相似度:
(xTl)2
(xTl)3
(xTl+1)3
通用的公式:
(xTl+Con)D
如果它们是相似的,那么內积就会很大。 - String kernel:
如果输入时文本字符
用来做分类
Chi-squared kernel
Histogram intersection kernel(直方图交叉核) - SVM的多分类:
Many packages have built in multi-class classification packages
Otherwise use one-vs all method
Not a big issue - SVM和Logistic 回归的比较:
六、作业






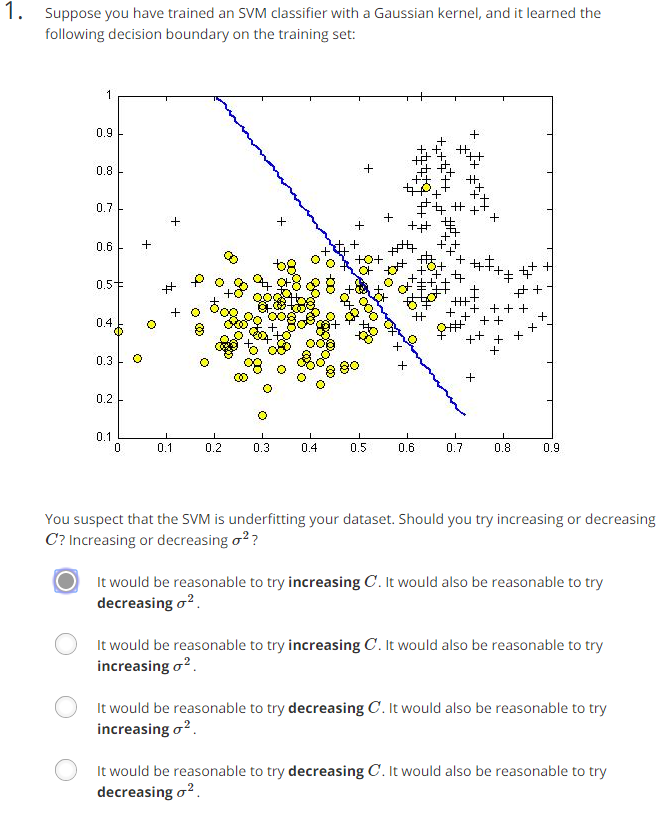
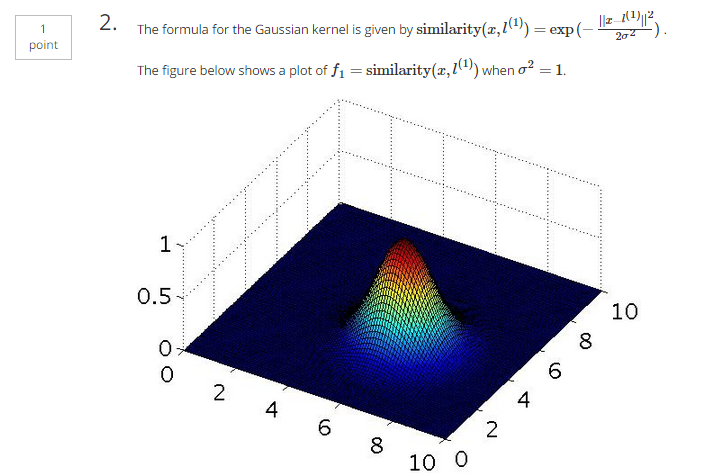
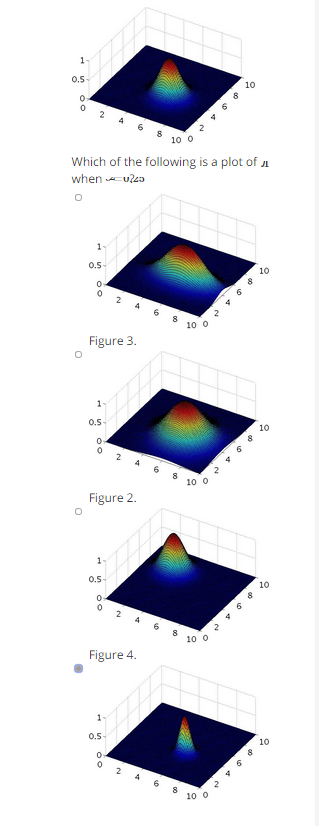


function sim = gaussianKernel(x1, x2, sigma)
%RBFKERNEL returns a radial basis function kernel between x1 and x2
% sim = gaussianKernel(x1, x2) returns a gaussian kernel between x1 and x2
% and returns the value in sim
% Ensure that x1 and x2 are column vectors
x1 = x1(:); x2 = x2(:);
% You need to return the following variables correctly.
sim = 0;
% ====================== YOUR CODE HERE ======================
% Instructions: Fill in this function to return the similarity between x1
% and x2 computed using a Gaussian kernel with bandwidth
% sigma
%
%
sim = exp(-(x1 - x2)' * (x1 - x2) / (2*(sigma^2)));
% =============================================================
end
dataset3Params.m:
function [C, sigma] = dataset3Params(X, y, Xval, yval)
%EX6PARAMS returns your choice of C and sigma for Part 3 of the exercise
%where you select the optimal (C, sigma) learning parameters to use for SVM
%with RBF kernel
% [C, sigma] = EX6PARAMS(X, y, Xval, yval) returns your choice of C and
% sigma. You should complete this function to return the optimal C and
% sigma based on a cross-validation set.
%
% You need to return the following variables correctly.
C = 1;
sigma = 0.3;
% ====================== YOUR CODE HERE ======================
% Instructions: Fill in this function to return the optimal C and sigma
% learning parameters found using the cross validation set.
% You can use svmPredict to predict the labels on the cross
% validation set. For example,
% predictions = svmPredict(model, Xval);
% will return the predictions on the cross validation set.
%
% Note: You can compute the prediction error using
% mean(double(predictions ~= yval))
%
smallest_error=1000000;
c_list = [0.01; 0.03; 0.1; 0.3; 1; 3; 10; 30];
s_list = c_list;
for c = 1:length(c_list)
for s = 1:length(s_list)
model = svmTrain(X, y, c_list(c), @(x1, x2) gaussianKernel(x1,x2,s_list(s)));
predictions = svmPredict(model, Xval);
error = mean(double(predictions ~= yval));
if error < smallest_error
smallest_error = error;
C = c_list(c);
sigma = s_list(s);
end
end
end
% =========================================================================
end
emailFeatures.m:
function x = emailFeatures(word_indices)
%EMAILFEATURES takes in a word_indices vector and produces a feature vector
%from the word indices
% x = EMAILFEATURES(word_indices) takes in a word_indices vector and
% produces a feature vector from the word indices.
% Total number of words in the dictionary
n = 1899;
% You need to return the following variables correctly.
x = zeros(n, 1);
% ====================== YOUR CODE HERE ======================
% Instructions: Fill in this function to return a feature vector for the
% given email (word_indices). To help make it easier to
% process the emails, we have have already pre-processed each
% email and converted each word in the email into an index in
% a fixed dictionary (of 1899 words). The variable
% word_indices contains the list of indices of the words
% which occur in one email.
%
% Concretely, if an email has the text:
%
% The quick brown fox jumped over the lazy dog.
%
% Then, the word_indices vector for this text might look
% like:
%
% 60 100 33 44 10 53 60 58 5
%
% where, we have mapped each word onto a number, for example:
%
% the -- 60
% quick -- 100
% ...
%
% (note: the above numbers are just an example and are not the
% actual mappings).
%
% Your task is take one such word_indices vector and construct
% a binary feature vector that indicates whether a particular
% word occurs in the email. That is, x(i) = 1 when word i
% is present in the email. Concretely, if the word 'the' (say,
% index 60) appears in the email, then x(60) = 1. The feature
% vector should look like:
%
% x = [ 0 0 0 0 1 0 0 0 ... 0 0 0 0 1 ... 0 0 0 1 0 ..];
%
%
for i=1:length(word_indices)
row = word_indices(i);
x(row) = 1;
end
% =========================================================================
end
processEmail.m:
% Look up the word in the dictionary and add to word_indices if
% found
% ====================== YOUR CODE HERE ======================
% Instructions: Fill in this function to add the index of str to
% word_indices if it is in the vocabulary. At this point
% of the code, you have a stemmed word from the email in
% the variable str. You should look up str in the
% vocabulary list (vocabList). If a match exists, you
% should add the index of the word to the word_indices
% vector. Concretely, if str = 'action', then you should
% look up the vocabulary list to find where in vocabList
% 'action' appears. For example, if vocabList{18} =
% 'action', then, you should add 18 to the word_indices
% vector (e.g., word_indices = [word_indices ; 18]; ).
%
% Note: vocabList{idx} returns a the word with index idx in the
% vocabulary list.
%
% Note: You can use strcmp(str1, str2) to compare two strings (str1 and
% str2). It will return 1 only if the two strings are equivalent.
%
for i=1:length(vocabList)
if(strcmp(str , vocabList(i)))
word_indices = [word_indices; i];
end
end














 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









