







有时候我们想在java程序中触发远程服务器上kettle job的执行,并且获得执行结果。kettle的carte提供了远程执行job和transfer的功能。
我使用的kettle是6.1版本,部署在linux服务器上,没有使用资源库。
下面介绍下各个步骤:为了方便以windows系统为例
1、开启carte服务,在kettle安装目录下,运行Carte.bat,直接上图
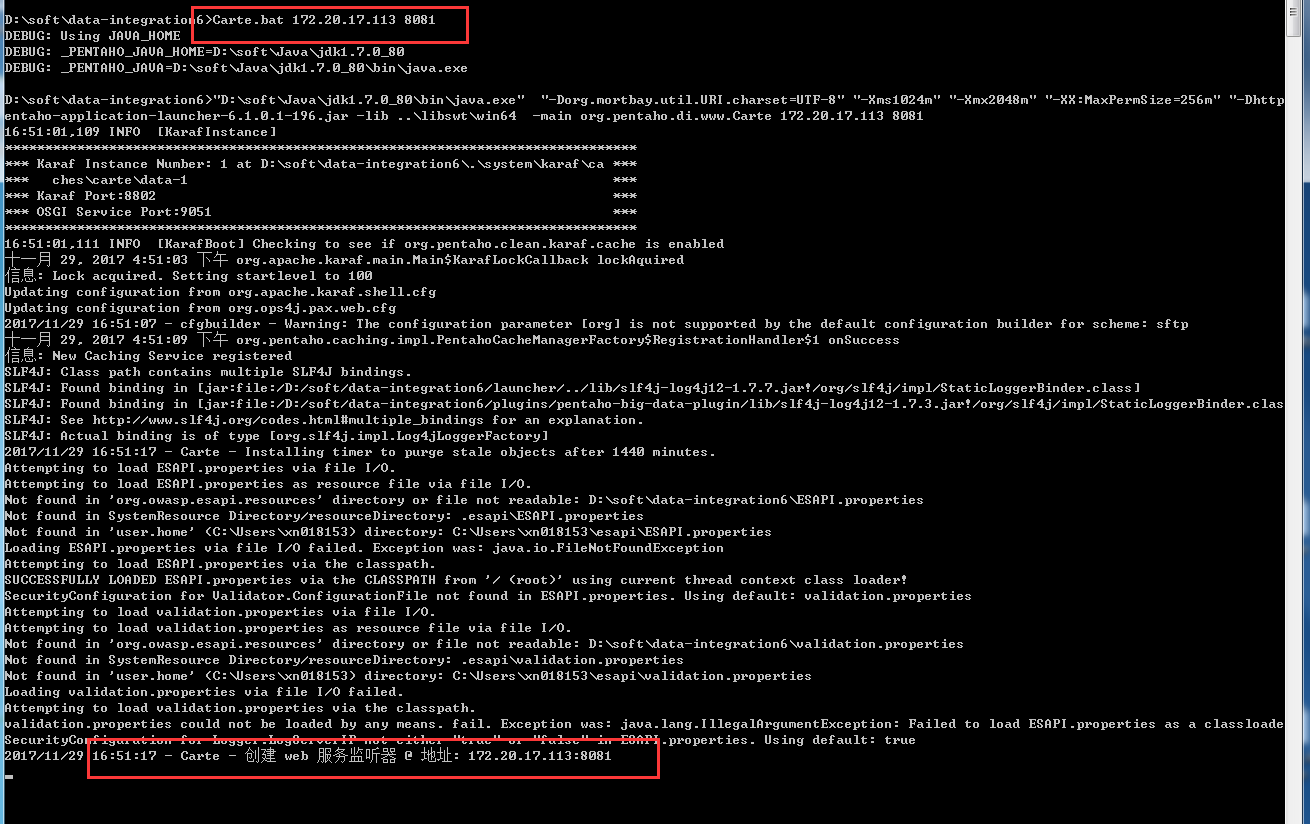
直接打Carte.bat后面不带任何参数就可以看到参数介绍,我这里在本机8081端口开启服务,看到最后的文字说明服务启动成功。
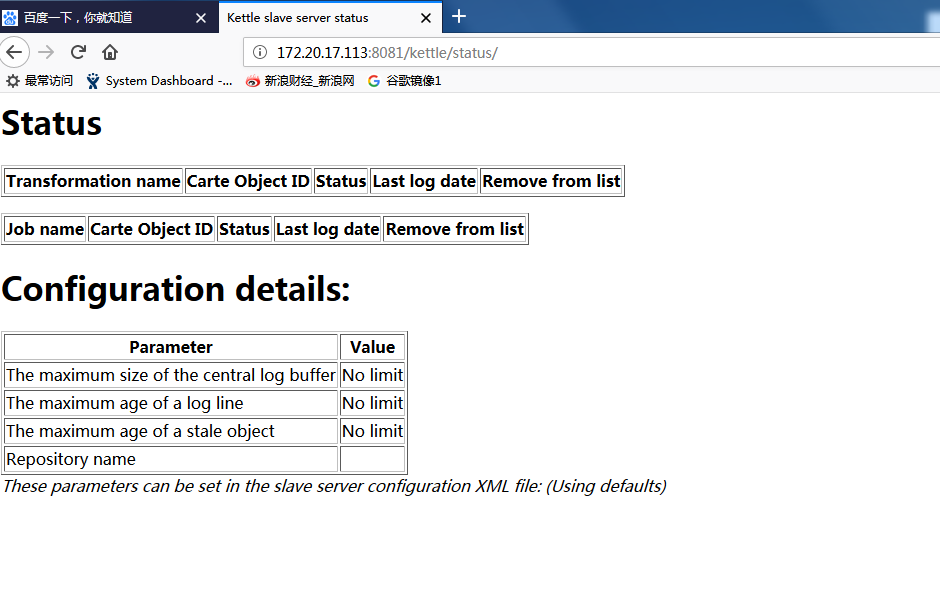
2、在浏览器中查看kettle 状态
在浏览器中输入http://172.20.17.113:8081,会提示输入密码,这里先直接输入cluster/cluster,然后可以进入,页面上会显示通过carte执行的job和transfer的状态。
那么这个用户名密码在哪设置呢?我找了半天,也是网上看前辈指引,原来是在kettle安装目录/pwd下面,大家可以看到有carte-config-8081到8084这些配置文件,还有carte-config-master-8080.xml,应该是做主从集群用的,先不管了。
打开carte-config-8081.xml就可以看到
<slaveserver>
<name>slave1-8081</name>
<hostname>localhost</hostname>
<port>8081</port>
<username>cluster</username>
<password>cluster</password>
<master>N</master>
</slaveserver>
端口号跟用户名密码的默认配置都在这里了。
3、使用java触发JOB执行。
下面介绍真正要做的事情了,建立java project。把kettle安装目录/lib下面相关jar包依赖上去。需要的包挺多的,懒得话全部依赖吧。我这边依赖这些包就够了,因为用到了spring读取文件的工具,也依赖了spring的包。

代码逻辑如下:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
|
这里因为job执行需要一些时间,我代码里面每隔5秒去拿一下结果,拿到结果确定job是否执行完成。
这时候如果我们去浏览器查看,可以看到job正在执行的状态。
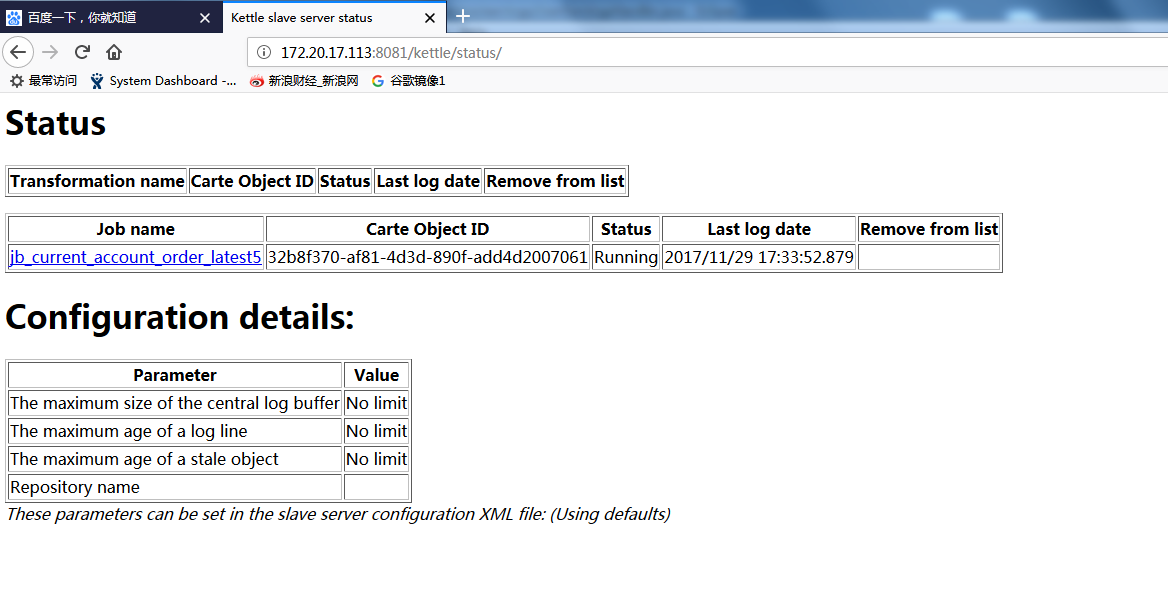
执行完成之后Running会变成Finish,如果有异常,status也会有提示。在命令行下面也会有job执行的日志信息。
大致过程就是这样,但是我研究的时候还是花了不少时间,网上资料不是很多,我这个算是完整介绍吧。















 142
142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









