







一、算法简介
TF-IDF是一种用于信息检索和数据挖掘的常用加权技术,其全称为Term Frequency-Inverse Document Frequency。它被用来评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
TF-IDF的计算公式是:TF-IDF(t,d) = TF(t,d) × IDF(t)。其中,TF代表词频(Term Frequency),表示一个词在特定文档中出现的频率。IDF代表逆文档频率(Inverse Document Frequency),表示一个词在语料库中出现的普遍程度。
一个词在特定文档中出现的频率越高,TF值越大,表示该词在该文档中越重要。而一个词在语料库中出现的频率越低,IDF值越大,表示该词具有较好的区分能力。因此,TF-IDF值越大,表示该词在特定文档中越重要。
二、算法运用
搜索引擎:在搜索引擎中,TF-IDF常被用于计算查询串和文档之间的匹配度。如果一个关键词在某篇文档中出现的频率高,同时在其他文档中出现的频率低,那么该词就具有很好的区分能力,能够提高文档和查询串的匹配度。
自动提取关键词:通过TF-IDF计算,可以确定每个单词的权重,并将权重最大的N个单词作为文章的关键词。
找出相似文章:使用TF-IDF算法,可以找出两篇文章的关键词,然后计算两个向量的余弦相似度,值越大表示两篇文章越相似。
信息过滤:TF-IDF可以用于信息过滤,通过计算查询串和文档之间的相似度,将不相关的文档过滤掉。
文本分类:TF-IDF可以用于文本分类,通过提取文本特征,将文本分成不同的类别。
三、算法步骤
第一步,计算词频:

考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。
第二步,计算逆文档频率:
这时,需要一个语料库(corpus),用来模拟语言的使用环境。
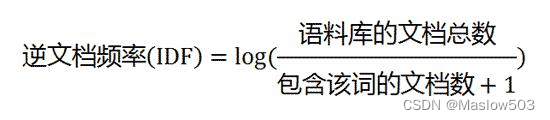
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
第三步,计算TF-IDF:
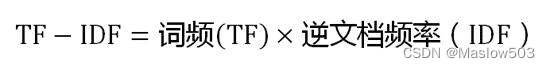
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
TF-IDF 代码实现
import jieba
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
# 定义一个更复杂的文本集
documents = [
'这是第一篇文章。这是一篇关于机器学习和人工智能的文章。',
'这是第二篇文章,和第一篇文章类似。它也涉及到机器学习和人工智能的主题。',
'这是第三篇文章,和前两篇文章完全不同。它讨论的是自然语言处理和文本挖掘的算法。',
'这是第四篇文章,它涉及到深度学习和神经网络的最新进展。',
'这是第五篇文章,它是一篇关于数据分析和数据可视化的文章。它介绍了如何使用Python进行数据分析和可视化。'
]
# 自定义jieba分词函数
def tokenize_with_jieba(text):
return ' '.join(jieba.cut(text))
# 对所有文档应用jieba分词
preprocessed_documents = [tokenize_with_jieba(doc) for doc in documents]
# 创建TF-IDF模型对象,使用自定义的分词器(这里其实是identity,因为分词已经在前面完成了)
vectorizer = TfidfVectorizer(tokenizer=lambda x: x.split()) # 这里我们不需要再次分词,所以只是简单地分割空格
# 将文本集转换为TF-IDF矩阵
tfidf_matrix = vectorizer.fit_transform(preprocessed_documents)
# 将TF-IDF矩阵转换为pandas DataFrame
df = pd.DataFrame(tfidf_matrix.toarray(), columns=vectorizer.get_feature_names_out())
# 输出每个单词的权重
print("单词\t权重值")
for index, row in df.iterrows():
for word, weight in zip(df.columns, row):
print(f"文档{index + 1}的'{word}'\t{weight}")
输出结果:

四、算法优缺点
TF-IDF的优点是简单快速,而且容易理解。缺点是有时候用词频来衡量文章中的一个词的重要性不够全面,有时候重要的词出现的可能不够多,而且这种计算无法体现位置信息,无法体现词在上下文的重要性。如果要体现词的上下文结构,那么你可能需要使用word2vec算法来支持。















 1005
1005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









