






用于在线乘车订单调度的知识转移深度强化学习
Zhaodong Wang ∗† Zhiwei (Tony) Qin ∗‡ Xiaocheng Tang ∗‡ Jieping Ye § Hongtu Zhu § ∗ Equal contribution † Washington State University, Pullman, WA Email: zhaodong.wang@wsu.edu ‡ DiDi Research America, Mountain View, CA Email: {qinzhiwei,xiaochengtang}@didiglobal.com § DiDi Chuxing, Beijing, China Email: {yejieping,zhuhongtu}@didiglobal.com
摘要:骑乘调度是骑乘共享平台上的一项中心操作任务,用于持续匹配驾驶员和乘客。在这项工作中,我们将骑乘调度问题建模为一个马尔可夫决策过程,并提出基于深度Q网络和行动搜索的学习解决方案,以优化骑乘共享平台上驾驶员的调度策略。我们使用滴滴乘车共享平台上的真实时空出行数据,为这项具有挑战性的决策任务培训和评估调度代理。大型调度系统通常支持多个具有不同供需设置的地理位置。为了提高学习的适应性和效率,我们提出了一种新的迁移学习方法——相关特征渐进迁移,以及两种现有的方法,使知识在空间和时间空间都能迁移。通过大量实验,我们展示了深度强化学习算法的学习和优化能力。我们进一步表明,通过将知识从源城市转移到目标城市或跨同一城市内的时间空间而学习的调度策略显著优于未进行转移学习的调度策略。
关键词——乘车调度、深度强化学习、迁移学习、时空挖掘。
一、导言
随着全球定位系统(GPS)应用在如今的共享乘车市场中的广泛应用,可以收集大量的出行数据,为提供更智能的服务提供了巨大的机会,并导致对需求预测[1]、[2]、驾驶路线规划[3]、[4]和订单调度[5]、[6]等研究领域的兴趣激增。我们的工作重点是订单调度。为共享乘车平台构建智能调度系统面临两大挑战。
第一个挑战是提高调度效率。
之前的工作(如[7])侧重于如何以最少的旅行距离或上车时间为代价,让共享乘车的驾驶员与乘客匹配。[8]中的工作旨在通过涉及组合优化问题[9]来提高全局顺序匹配的成功率。更高的成功率将提供更好的用户体验,但这不应该是唯一需要优化的指标。之前的另一项研究[10]提出了一种针对巡航出租车司机的收入优化方法。它利用强化学习帮助驾驶员在巡航路线上做出决策。在历史轨迹日志上进行训练后,可以提高巡航效率。巡航轨迹(训练数据在〔10〕)中只考虑出租车闲置时的位置状态(船上没有顾客)。然而,由于乘客出行会改变驾驶员的位置,如果培训数据仅包含空闲巡航日志,则全局优化仍然存在局限性。
另一个挑战是可伸缩性。对于一个支持多个城市的大型平台,考虑到一次性优化整个乘车共享平台的复杂性以及不同城市之间的不同供需设置,通常会将订单调度问题分解(通常按自然地理边界),并将重点放在单个城市上。然而,由于每个优化问题的规模和大量城市,在平台上为每个城市构建新模型的计算效率不高,而且难以扩展。尽管不同城市的交通模式通常不同,但它们可能仍有一些共同的特性。
例如,我们可以想象,在不同的城市中,市中心和住宅区之间的高峰时间交通需求可能是相似的。与其将每个城市视为一个全新的问题,还不如实现知识的跨城市转移和共享,这样学习就可以在全球范围内进行,而不是孤立在一个狭窄的领域。这通常被称为迁移学习[11],[12],已成功应用于许多领域,如多任务学习[13],[14]、深度强化学习[15]–[17]和表征学习[18],[19]。
为了解决上述挑战,我们考虑从单司机视角的订单调度问题,其中驾驶员被分配了一系列行程请求,目标是使整个一天的总收入最大化。[20]最近的工作表明,通过使用基于历史数据的乘客需求和出租车供应模式的学习和规划方法,在这方面取得了巨大成功。特别是,[20]将该问题建模为马尔可夫决策过程(MDP),并使用动态规划在离散表格状态空间中执行策略评估。然而,这种方法的局限性主要有三个方面。首先,基于不同的实时因素(如交通供给和需求),状态值可能会有很大的变化,但通常情况下,表格模型很难实时纳入和响应此类上下文信息。换句话说,代理必须能够根据在线条件对历史数据进行概括。第二,不同城市的出行构成了不同的MDP,可能有许多共同的结构。表格法将每个MDP单独处理,并不能提供一种可行的跨城市知识转移机制。
最后,[20]中的政策改进是一个单独的步骤,必须在线执行至少一天。要实现收敛,通常需要几十次评估改进迭代,这可能需要几周的时间。理想情况下,我们希望采用一种非策略性的方法,它可以更有效地学习,同时避免直接在线学习的风险。
我们在本文中的贡献是一种深度强化学习方法来克服这些局限性。我们基于无模型RL的最新进展,提出了一种基于Q学习的订单调度框架[21],[22]。产生一个控制每一步决策的最优策略的关键是估计驱动因素的状态作用值函数。这个函数告诉我们,在给定的供需环境下,在特定的地点和时间,就长期目标做出的决策有多好。具体来说,我们的方法属于深度Q网络(DQN)框架,具有执行动作搜索的额外能力。我们的方法有效地结合了历史数据和简单的合成辅助数据来训练深度强化学习代理,即使在没有完整的模拟环境时也能工作。由此产生的Q网络可以用作多司机调度系统中的一个组件。DQN通过达到和超越人类水平玩各种Atari游戏,展示了它的学习能力[22]。我们在本文中表明,它在驾驶员和调度系统的学习策略方面同样强大。
与表格状态值函数相比,使用深度网络还具有利用经过培训的知识和加快跨不同城市学习的优势。考虑到强化学习通常在开始时学习速度较慢,转移相关的先验知识[23]为促进学习过程提供了一个有效的解决方案。我们提出了一种新的订单调度转移学习方法,以利用来自源城市的知识转移,证明重用先前的模型可以提高目标城市的培训性能。改进包括三个方面:更高的起跳(即。
更好的初始解),更快的收敛学习,更高的收敛性能。
在接下来的内容中,我们将在第二节中制定我们的MDP,并在第三节中描述我们针对乘车共享平台上的大规模订单调度问题定制的深度Q网络方法。在第四节中,我们提出了一种新的转移学习方法,以及两种现有的方法,允许我们在空间和时间空间中转移知识。我们通过第五节中使用滴滴平台的真实出行数据进行的大量实验,展示了我们的深度强化学习方法的学习和优化能力,以及所提出的转移学习方法在学习速度方面的优势。我们在第六节中用几句结束语结束本文。
二、MDP公式
我们的基本MDP公式遵循[20]的公式,主要区别在于我们的方法使用更细粒度的状态和动作信息,具有供需上下文特征,并学习状态-动作-价值函数。代理是从驾驶员的角度定义的。行程转换包括取单和完成:驾驶员与行程单匹配并前往行程起点位置。这趟旅行把司机带到了目的地。司机从这次过渡中立即获得奖励(旅行费)。过渡也可能导致驾驶员空转。对于本文的其余部分,我们将考虑空闲驱动器运动作为零奖励行程。我们在下面列出了MDP配方的关键要素。
状态,s是司机的地理坐标,以及当司机被派去执行行程指令时的时间(以秒为单位),即s:=(l,t),其中l是GPS坐标对(纬度,经度)和时间。请注意,它可能不同于乘客所处行程的实际起点。
此外,s可能包含(l,t)处的其他上下文特征,例如(l,t)附近的需求、供应和订单履行的统计数据,表示为f。在这种情况下,扫描可以从(l,t)扩展到(l,t,f)。我们还区分了工作日和周末的时间。在本文的其余部分中,我们分别用s和st表示一个状态s的land t分量。
动作a是指将特定行程分配给驾驶员,该行程仅由行程目的地和下车时间定义。让当前状态
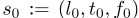
为指定行程时驾驶员的位置、时间和上下文,下一个状态
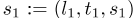
为下车位置、时间和上下文。然后,动作是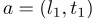 。所有符合条件的操作的空间都用A表示。
。所有符合条件的操作的空间都用A表示。
奖励,r是为旅行收取的总费用,是沙a的函数。
一集是完整的一天,从早上0:00到晚上23:59。
因此,终端状态是具有对应于23:59 pm的t分量的状态。我们在所有这些转换中设置s1,在这些转换中,行程跨越午夜,成为终端状态。
状态行动价值函数Q(s,a)是指如果驾驶员从状态开始并采取行动a,那么在一集结束前,他/她将获得的预期累积奖励。数学上,
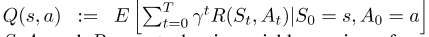
,其中S、A和S、A和r的稀有随机变量版本分别为;这是到终端状态的过渡步数,γ是未来奖励的贴现因子。我们将时间空间离散为10分钟的步数,γ是一个阶数跨越的时间步数的倍数。
策略,π(a | s)是一个函数,它将状态s映射到行动空间(随机策略)或特定行动(确定性策略)上的分布。关于学习的Q(s,a)的贪婪策略由
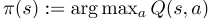
给出。
状态值函数,V(s):如果司机从状态开始并遵循政策π,他/她在一集结束前将获得的预期累积奖励。假设使用贪婪策略w.r.t.Q函数,则状态值
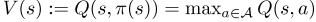
。
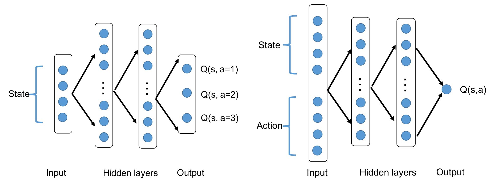
图1:左:图[22]中的Q网络。右图:本文中的Q网络。
三、 DEEP Q-行动搜索网络
为了解决第二节中制定的MDP,我们采用无模型方法,并使用[22]中提出的DQN框架。与[22]的偏差有两个方面:首先,在神经网络结构上,由于连续的动作空间,Q(s,a)不能被枚举,我们使用状态和动作(s,a)作为网络输入,qvalue作为单一输出,而vanilla DQN假设一个小的离散动作空间,只使用状态作为输入,并使用与每个动作的动作值对应的多个输出。这两种情况下的隐藏层可以是完全连接的层,也可以是卷积层,具体取决于具体的应用。图1显示了结构对比。
其次,由于订单调度MDP公式中的动作空间在技术上是连续的,因此我们开发了一个动作搜索机制(见第III-B和III-C节),为每个转换定义一个离散的动作空间。算法的伪代码如算法III.2所示。
在DQN框架中,通过反向传播的小批量更新本质上是解决具有以下损失函数的自举回归问题的一个步骤,其中θ′是上一次迭代的Q网络的权重,a是动作空间。
为了提高训练稳定性,我们使用了[24]中提出的双DQN。具体而言,目标Q网络Q̂与原始Q网络定期保持和同步。修改(1)中的目标,以便通过目标网络评估argmax:
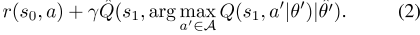
A.模型培训建立模拟城市规模驾驶员-乘客动态的真实订单调度环境非常具有挑战性,更不用说将从模拟器学习的值函数应用于实际设置了。另一方面,数据仓库中通常有大量的历史出行数据。
因此,我们选择使用历史行程数据进行培训。
这使我们的方法不同于传统的强化学习方法,因为训练中没有明确的模拟环境。相反,我们根据一些现有行为政策生成的历史数据,并辅以简单的合成数据,对我们的代理人进行培训,我们将在第III-B和III-C节中描述这些数据。每次行程x定义代理人状态的转变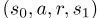 。这些转换体验从数据仓库中一个接一个地检索(就像它们是从模拟器生成的一样),并存储在回放存储器中,类似于[22]。然后,每一次迭代都会从这个重播内存中抽取一小批样本。我们在算法III.2中陈述了基于DQN的训练算法,并在后续章节中解释了各种算法元素。
。这些转换体验从数据仓库中一个接一个地检索(就像它们是从模拟器生成的一样),并存储在回放存储器中,类似于[22]。然后,每一次迭代都会从这个重播内存中抽取一小批样本。我们在算法III.2中陈述了基于DQN的训练算法,并在后续章节中解释了各种算法元素。
B.行动搜索从第二节中回顾,一项行动的形式为(l,t)。
由于GPS坐标和时间都是连续的,所以精确计算(1)中的max-Q项是不容易的。此外,t组分与l组分有依赖关系,因为它反映了行程的持续时间。因此,从行动空间进行随机抽样是不合适的。因此,我们通过构造作用Ã(s)的近似可行空间,发展了一种计算该项的近似方案。这个符号明确了动作空间对搜索开始的状态的依赖性。我们没有搜索所有有效的动作,而是在源于s附近的历史行程中进行搜索:
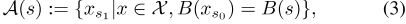
,其中X是所有行程的集合,B(s)是s所属的离散化时空bin。对于空间离散化,我们使用六边形箱系统,在这里的例子中,六边形箱由其中心点坐标表示。x s 0和x s 1分别是行程x的s 0和s 1分量。搜索空间越大,评估每个行动点的价值网络所需的计算就越多。我们将操作搜索空间中允许的操作数设置为一个调整参数,并在必要时进行随机采样,而不进行替换。同样的搜索程序也用于政策评估,我们使用历史行程数据模拟驾驶员白天的轨迹。
C.由于某些时空区域(例如清晨的某个偏远地区)的训练数据稀疏,扩展的动作搜索可能会返回一个空集。在这种情况下,我们在空间和时间空间中执行扩展的动作搜索。
第一个搜索方向是停留在最后一个下车位置并等待一段时间,这相当于保持l-分量s l恒定并前进st,直到发生以下情况之一(s’是搜索状态):1) 如果Ã(s′)非空,则返回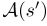 。2) 如果达到终端状态,则返回终端状态。3) 如果s′t超过等待时间限制,则返回s′。第二个搜索方向是通过分层搜索sin的相邻六边形箱来进行空间扩展。如图2所示。对于每层L六边形箱,我们在适当的时间间隔内搜索,以考虑从s到达目标六边形箱所需的行程时间。例如,旅行时间估计可以通过地图服务获得,这超出了本文的范围。我们用B(s,L)表示与s相邻的L层时空箱,用
。2) 如果达到终端状态,则返回终端状态。3) 如果s′t超过等待时间限制,则返回s′。第二个搜索方向是通过分层搜索sin的相邻六边形箱来进行空间扩展。如图2所示。对于每层L六边形箱,我们在适当的时间间隔内搜索,以考虑从s到达目标六边形箱所需的行程时间。例如,旅行时间估计可以通过地图服务获得,这超出了本文的范围。我们用B(s,L)表示与s相邻的L层时空箱,用
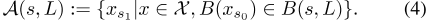
表示源自B(s,L)中任何箱的历史行程集。当Ã(s,L)为非空且返回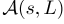 时,我们停止增加L。否则,我们返回
时,我们停止增加L。否则,我们返回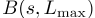 ,即六边形箱子的中心点及其相关时间分量。L max基本上控制动作空间的大小。算法III.1总结了完整的动作搜索。我们可以将动作搜索视为将一个时空垃圾箱连接到另一个垃圾箱,方法是让司机等待,或将没有乘客的司机移动到另一个位置,以便获得订单。
,即六边形箱子的中心点及其相关时间分量。L max基本上控制动作空间的大小。算法III.1总结了完整的动作搜索。我们可以将动作搜索视为将一个时空垃圾箱连接到另一个垃圾箱,方法是让司机等待,或将没有乘客的司机移动到另一个位置,以便获得订单。
D.终点状态值根据第二节中终点状态的定义,很明显,无论位置s l如何,st接近事件视界末端的Q(s,a)应接近于零。根据动态规划算法的思想,我们在训练开始时向回放缓冲区添加以s1为终端状态的转换。我们发现,它有助于在训练的早期获得正确的终端状态动作值。这一点很重要,因为DQN(即(2))的小批量更新中的状态s 0的目标值是通过对它们之后的状态值进行自举来计算的。由于具有终端状态的训练样本在整个数据集中所占的百分比非常小,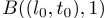 ,因此小批量的统一采样将导致在没有足够监督的情况下学习终端状态值,这导致远离终端的许多状态的值安装了错误的目标,从而减慢了学习过程。
,因此小批量的统一采样将导致在没有足够监督的情况下学习终端状态值,这导致远离终端的许多状态的值安装了错误的目标,从而减慢了学习过程。
E.经验增强原始训练数据是给定历史政策产生的经验,可能没有充分探索轨迹空间。特别是,当驾驶员处于历史上很少有从那里出发的行程的状态时,我们的行动搜索可能会要求驾驶员等待一段时间,或在没有乘客的情况下巡航,然后再开始行程。然而,数据中可能很少有这样的转换。如果代理人员接受了原始行程数据的培训,那么在驾驶员进入罕见状态的情况下,它将无法学会做出正确的决策。我们缓解这个问题的方法是通过行动搜索获得的过渡来补充原始训练体验。具体来说,我们将在小批量更新(2)期间,通过以下第III-B节和第III-C节生成的动作搜索体验添加到回放内存中,以补充现有的训练数据。
F.评估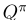 要学习给定状态下驾驶员的平均值,一种方法是学习生成训练数据的策略π的Qπ。为此,我们只需将(2)中的“argmax”替换为“mean”。由此产生的算法类似于预期的SARSA[25]。价值网络的培训目标是代表驾驶员在政策π下所有可能行动的平均价值。关于
要学习给定状态下驾驶员的平均值,一种方法是学习生成训练数据的策略π的Qπ。为此,我们只需将(2)中的“argmax”替换为“mean”。由此产生的算法类似于预期的SARSA[25]。价值网络的培训目标是代表驾驶员在政策π下所有可能行动的平均价值。关于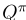 的贪婪或集体贪婪的调度策略(见第III-G节)是一步策略改进。
的贪婪或集体贪婪的调度策略(见第III-G节)是一步策略改进。
G.多司机调度环境中的部署真实环境本质上是多代理的,因为多个司机同时执行乘客命令。
尽管如此,我们学习到的单驱动程序值函数仍可以以与[20]中类似的方式部署在多代理环境中。在每个决策点(调度),我们将调度窗口中收集的订单分配给一组驱动程序,以最大化分配的总价值
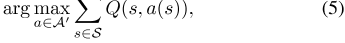
其中a(s)是一个分配函数,用于将订单从池中分配给驱动程序s;A′是订单池中所有赋值函数的空间;S是可用的免费驱动程序集(及其状态)。匹配部分可以通过标准匹配算法解决,例如匈牙利方法(又称KM算法)。具体来说,我们使用单驱动值函数来计算KM算法的双边图的边权重。我们将这种调度策略统称为贪婪的w.r.t.Q。
H.表格形式的状态值(V-值)在[20]中,学习表格形式的状态值函数V(·),以计算与行程分配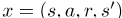 相对应的边缘权重,其中沙子s’没有上下文特征。
相对应的边缘权重,其中沙子s’没有上下文特征。
As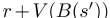 是Q(s,a)的样本近似值,ax:=r+V(B(s′)− V(B(s))是与行程分配x相关的优势,并用作边缘权重。我们记得B(s)是与s相关联的时空bin。
是Q(s,a)的样本近似值,ax:=r+V(B(s′)− V(B(s))是与行程分配x相关的优势,并用作边缘权重。我们记得B(s)是与s相关联的时空bin。
我们的方法能够直接利用上述框架。
我们可以从学习到的qf函数生成表格V函数,如下所示:对于每个具有单元中心s的时空单元B(s),
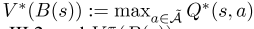
,对于Q∗ 通过算法III.2和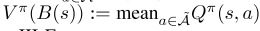 ]
]
学习,通过以下III-F获得Qπ。

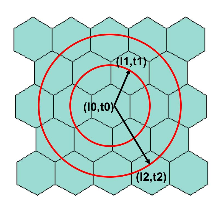
图2:动作搜索。红色圆圈线覆盖了相邻的L0六边形箱的前两层。箭头表示在时间t1>t0时搜索到以l1(第一层)为中心的六边形仓,以及在时间t2>t1时搜索到以l2为中心的六边形仓。被内部红圈覆盖的时空垃圾箱是。

四、 多城市换乘
调度系统必须负责大量城市的订单。培训一个覆盖所有城市的单一调度代理在计算上是不允许的,而且部署的灵活性有限。此外,如果我们将整个调度视为一组针对不同城市的独立优化问题,那么计算成本也相当高。例如,使用6核CPU、单GPU计算资源设置,使用一个月的数据优化中国一个中等城市的调度策略模型需要大约30小时才能收敛。在这种情况下,转移先验知识(即重用以前训练过的模型)可能是一个可行的解决方案。更重要的是,由于非凸性,深度学习会受到局部最优解的影响,如果训练从更好的初始点开始,或者遵循更好的梯度方向,这将来自知识转移,那么深度学习可能会达到更高的收敛性能。
由于城市结构、发展水平和许多其他因素,不同城市的交通模式将不完全相同。然而,它们可能有一些共同的特点,比如早晚交通的高峰时间,以及从住宅区到商业区的出行需求。利用DQN的近似函数(即非线性网络),我们知道如何构建策略模型。换言之,DQN的制定为我们提供了许多灵活的方法来传递学到的政策。与[20]相比,对于表格形式的价值函数,这也是一个优势,因为不涉及函数逼近器,所以每个城市的学习政策都非常独特,因此不适用于知识转移。
我们考虑了三种改进目标城市训练的方法,包括微调、渐进网络和相关特征渐进转移(CFPT)。这些转移方法的共同想法是使用从源城市学习的经过训练的网络权重。网络结构如图3和图4所示。
微调[26]仍然是迁移学习的常用方法。在源城市上训练网络后,我们将权重传递给目标城市的网络。如图3所示,我们使用从源城市学习到的权重初始化所有完全连接层的权重,并让它们可以在目标城市数据上进行训练。然后,通过反向传播对网络进行微调。
渐进式网络[15]通过与目标网络的横向连接来利用经过训练的权重。连接函数定义为:
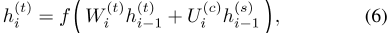
,其中W(t)i表示目标网络第一层的权重矩阵,U(c)i表示来自源任务网络的横向连接权重矩阵。h(t)i和h(s)i分别是目标网络和源网络中第一层的输出。f(·)是激活函数。为了执行权重传递,我们首先训练一个源网络,如图1所示,然后将其连接到目标网络,如图3所示。在传输过程中,我们也会调整源网络的输出层(半透明圆)。
CFPT:由于州空间的多样性,并不是所有的州元素都适用于不同的城市。在训练过程中,我们没有使用将所有州元素作为一个整体的完全连接的网络,而是为源城市构建并训练一个并行渐进结构,如图4所示,连接与图6中的连接相同。此外,网络输入还分为两部分:s表示直观上不适合目标城市的要素,f表示可适应的要素。在源城市的训练期间,网络的所有权重都是可训练的。对于目标城市,我们使用相同的结构构建网络,尤其是重用源城市模型中的累进部分(如图4中的绿色块所示)的权重,该模型采用直接输入。CFPT的主要创新之处在于:在源城市的培训阶段,我们已经将网络拆分为平行流,图4中的底流(用于未来传输)只负责输入f。两个流的每个相同层级层中的神经元数量是原始完全连接网络的一半,这将大大减少可训练参数的总数。
在这项工作中,我们定义了相关特征输入,即时空位移向量和实时上下文特征的串联。使用第二节中的符号,三元组时空位移向量计算为(s1)− s 0)。5元组上下文特征向量包含实时事件计数,例如空闲驱动程序的实时数量,以及过去1分钟内创建的订单的实时数量。
与绝对GPS位置相比,上述相关特征与调度需求、供应和订单履行的统计有关。一般来说,它们作为不同城市的输入可能更具适应性,这就是为什么我们将原始网络输入分成两个子空间的原因。
图3说明了上述三种方法之间的输入空间差异。注意,s=(s0,s1)已经包含了动作输入A(行程目的地),这在第二节中有定义。
五、实验
在本节中,我们将讨论实验设置和结果。我们使用从滴滴调度平台获得的历史ExpressCar出行数据作为我们的培训数据。数据集分为训练集(2/3)和测试集(1/3)。每个小批量都可以被视为Q(状态动作)值函数上的一组小样本点。我们使用了贴现系数γ=0。9 . 对于所有基于DQN的方法,我们使用了一个大小为100000的重播缓冲区。我们用总体平均值和标准偏差对所有状态向量进行归一化。我们发现,这种预处理对于稳定的训练是必要的。对于训练结果,我们使用1000集的滑动窗口来计算奖励曲线,总训练时间为40000集。对于测试结果,我们在培训期间设置了五个测试点:0%、25%、50%、75%和100%。在每个训练检查点,我们拍摄当前网络的快照,并在测试数据集上对其进行评估,以随机初始状态进行5次100集的试验。
A.单代理评估环境由于过渡数据完全是历史数据,且不一定形成完整的事件,我们根据过去的行程数据(测试集)构建了一个单驾驶员调度环境,用于直接、明确地评估从学习值函数生成的策略。基本上,我们假设司机在目的地让乘客下车后,他/她将被分配一个新的行程请求,从上一个目的地附近开始。如有必要,可根据第III-C节增加搜索空间,以涵盖在最后一个下车区附近没有历史旅行的情况。下一步由给定策略从操作搜索输出中选择,可以是产生费用的行程或等待/重新定位操作的组合。如果该行动涉及历史旅行,则与该行动相关的奖励为实际旅行费用;否则奖励为零(等待或重新定位)。我们使用按比例计算的奖励百分比(给定城市的标准化常数相同)作为绩效指标。我们对多个事件(天)进行模拟,计算获得的累积奖励,并对这些事件进行平均。
为了绘制训练曲线,我们使用与训练步骤相同的速度,对学习到的Q值函数使用贪婪策略,逐步引导agent通过该环境。除了原始的时空输入空间外,我们发现上下文特征也有利于训练,如图5所示。因此,在下面的部分中,我们使用扩展的状态空间作为网络输入。
B.基线DQN培训我们为中国的四个城市建立了三个隐藏密集层和ReLU激活的Q网络,并培训了调度策略,分别用A、B、C和D表示。它们跨越不同的人口规模和地理区域。
我们在表一中总结了这四个城市的特点。
为了展示算法III.2作为基线方法的优化改进,我们首先将其与第III-F节中提到的政策评估进行了基准测试。图6比较了DQN和政策评估的训练曲线,其中前者是最大化累积奖励,后者只是在学习评估产生历史数据的现行政策,如第V-A节所述。带有标准偏差误差条的测试曲线如图7所示。
从性能曲线可以看出,我们的算法III.2能够学习优化节目顺序收入。图8显示了训练小批量的平均Q值,我们在所有情况下都观察到了值函数的收敛。如第III-H节所述,我们计算表格形式的状态值函数,并按图9中的时间id绘制120个随机采样位置单元的状态值:每个点表示未来潜在的奖励,以γ=0贴现。9,所以状态值是在衰减的未来范围内计算的。我们看到,状态值函数正确地捕捉到了折扣累积奖励时间空间中的单调递减性。然而,不同城市之间的学习结果或改进并不相同。在我们的实验中,我们发现,对于那些出行数据较少的小城市(由于这些地区的用户较少),例如bin图6b,优化改善不如大城市,例如D市。这是因为在这些订单需求较轻的城市,出行模式要简单得多,我们目前的订单调度系统[8]几乎可以实现司机和客户之间的最佳匹配。这也表明政策改进的潜在收益不大。然而,在调度负荷较大、出行数据量较大的城市,优化效果更为明显,如图6d所示。
C.迁移改进为了在目标城市实现稳健有效的网络培训,我们进行了两种类型的迁移实验,包括空间迁移和时间迁移。在空间转移方面,在上一节提到的四个实验城市中,A城市被用作源城市,而其他三个城市被用作目标城市。对于时间转移,使用一个月数据训练的城市模型作为源,而使用后一个月数据训练的相同城市的模型作为目标。我们使用前一节V-B中经过训练的网络权重作为先验知识。在每种类型的迁移实验下,我们将比较和讨论三种迁移方法的学习性能,包括微调、渐进网络和相关特征渐进迁移(CFPT)。
培训曲线和测试检查点如图10所示。为了突出显示结果,我们展示了从实际调度系统中的历史出行数据中采样的累积事件奖励的平均值。与普通的DQN培训相比,我们可以看到以下改进:1)目标城市将受益于jumpstart,这是一开始提高的初始性能;2) 学习效率更高,这意味着在训练过程中会更早地收敛;3) 收敛性能较好。然而,这三种方法的有效性是不同的。特别是,CFPT优于其他两种转移方法,表明如果与绝对时空状态(l,t)分开使用,在线特征f可以更有助于跨不同城市的学习适应。原有的渐进网络的弱点在于它没有考虑所有状态/特征元素之间的相关性差异。由于微调的灾难性遗忘特性,随着权值的更新,先验知识很容易被遗忘,并且我们也看到收敛性能的改善不太明显。时间转移结果如图11所示。虽然转移是在同一个城市内进行的,但CFPT的表现将明显优于基线精细化方法,后者直接复制上个月的网络并继续培训。
为了深入了解知识转移如何改善目标城市的培训,我们比较了培训期间每个批次的平均Q值。以City das为例,我们可以发现图12中Q值曲线之间的明显差异。对于原始的DQN训练,即使平均Q值几乎收敛,仍然存在明显的方差。相比之下,对于CFPT,批次的方差要小得多。这种差异可能表明,通过先前训练网络的横向连接,目标训练中“梯度下降”的方向更加明确。换句话说,转移先验知识可以有效地指导学习方向。
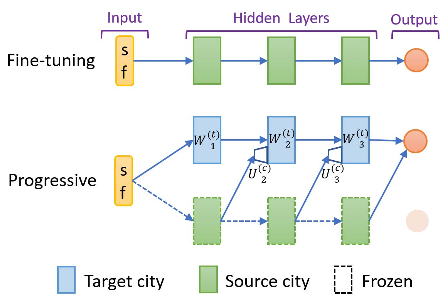
图3:微调和渐进式网络的结构。我们使用来自源城市的训练权重初始化绿色块。冰冻层将在目标训练期间保持转移的重量。
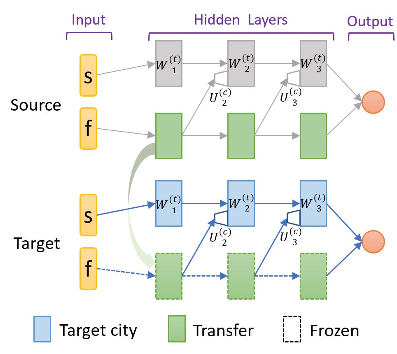
图4:CFPT网络:我们分离输入空间,只传输显示为绿色块的网络权重。
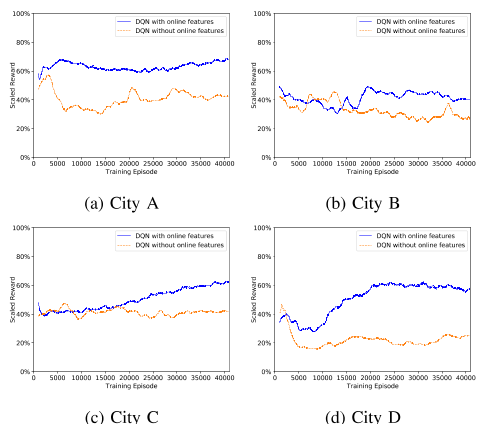
图5:两种输入类型之间的比较:原始时空状态和具有扩展上下文特征的状态。
表一:实验中中国四个城市的基本特征。
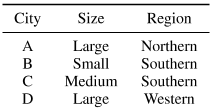
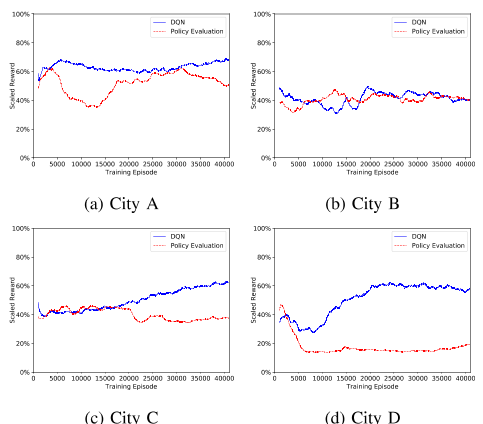
图6:DQN在四个城市的动作搜索训练曲线。
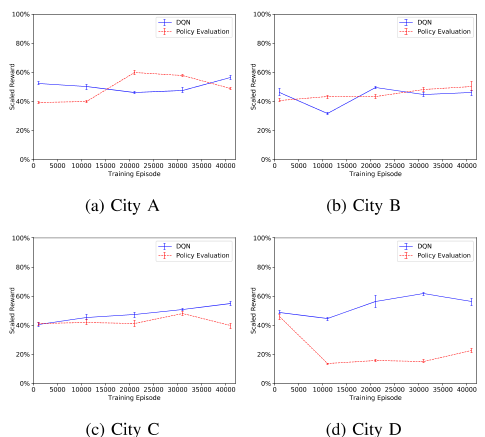
图7:在训练阶段的5个不同检查点,在四个城市使用行动搜索对DQN进行测试评估。
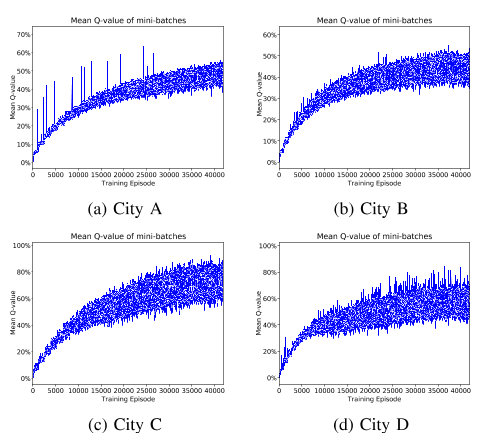
图8:训练小批量的平均Q值。
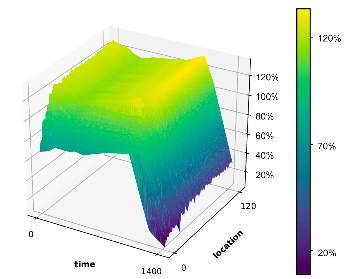
图9:D市120个取样位置箱的V值。
六、 结论
本文提出了一种基于DQN的滴滴出行调度平台订单收入优化方法。
与可枚举输出动作的普通DQN不同,我们将连续动作空间(行程目的地)编码为输入状态空间的一部分,并提供相应的动作搜索方法。我们表明,我们的应用程序能够从单个驱动程序的角度优化时空问题。通过展示因城市交通模式的多样性而产生的不同学习结果,我们知道不同城市的学习过程并不简单。作为对抗这种多样性的解决方案,我们评估了两种现有的迁移学习方法:微调和渐进式网络,并提出了一种基于在线特征的自适应方法——CFPT。
结果表明,在处理新模式时,重用训练模型可以加快学习速度,提高鲁棒性。特别是,通过关注不同领域的相关特征,CFPT可以实现最有效的传输,并且优于其他方法。
我们提出的优化方法是从单个驱动程序的角度出发,从局部角度出发。为了克服静态环境假设,我们可以使用多智能体强化学习方法来学习调度策略。我们还可以训练一个全局价值函数来学习一个集中的政策。
我们将这些想法作为未来的研究方向。
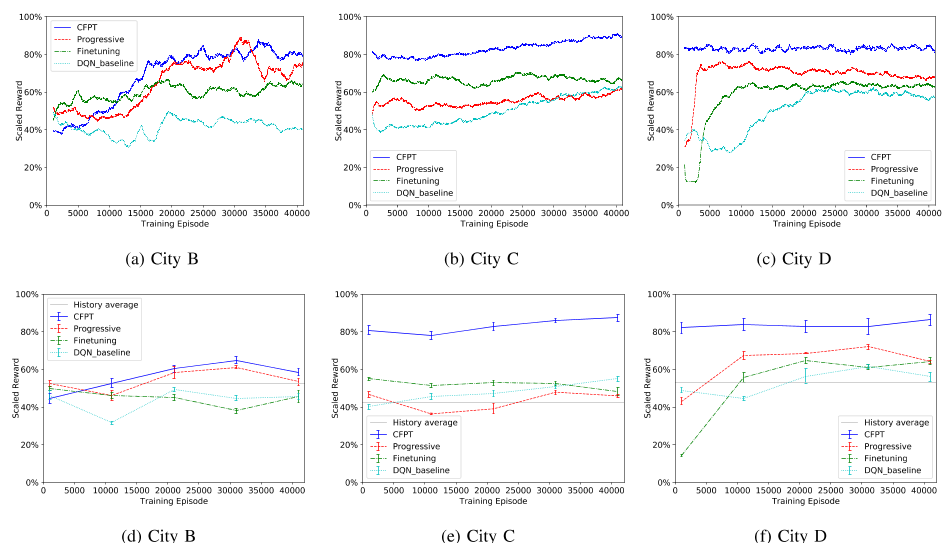
图10:空间转换的训练和测试曲线。(顶部:训练曲线;底部:在训练期间在不同的检查点测试奖励。)
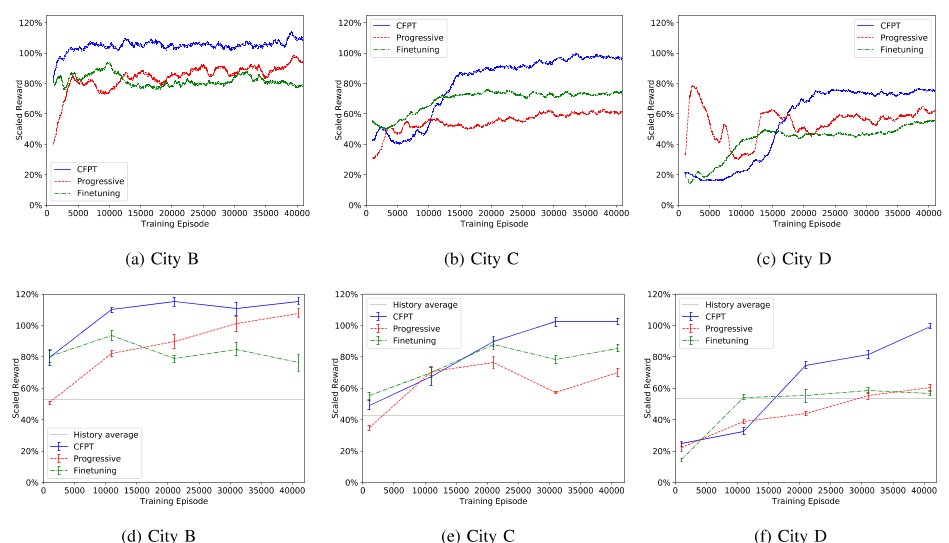
图11:时间转移的训练和测试曲线。(顶部:训练曲线;底部:在训练期间在不同的检查点测试奖励。)
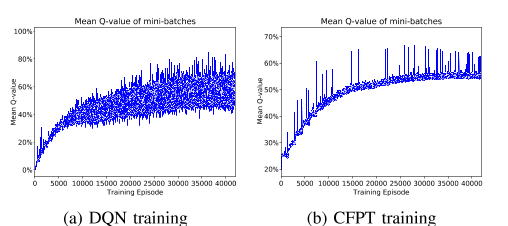
图12:城市D的平均小批量Q值比较。
致谢
我们要感谢萨丁德·辛格(Satinder Singh)和徐哲(Zhe Xu)的深入讨论,以及匿名评论者的建设性评论。
参考文献
[1] L. Moreira-Matias, J. Gama, M.-M. J. Ferreira, Michel, and L. Damas, “On predicting the taxi-passenger demand: A real-time approach,” in Portuguese Conference on Artificial Intelligence . Springer, 2013, pp. 54–65.
[2] L. Moreira-Matias, J. Gama, M. Ferreira, J. Mendes-Moreira, and L. Damas, “Predicting taxi–passenger demand using streaming data,” IEEE Transactions on Intelligent Transportation Systems , vol. 14, no. 3, pp. 1393–1402, 2013.
[3] Q. Li, Z. Zeng, B. Yang, and T. Zhang, “Hierarchical route planning based on taxi gps-trajectories,” in Geoinformatics, 2009 17th International Conference on . IEEE, 2009, pp. 1–5.
[4] T. Xin-min, W. Yu-ting, and H. Song-chen, “Aircraft taxi route planning for a-smgcs based on discrete event dynamic system modeling,” in computer Modeling and Simulation, 2010. ICCMS’10. Second International Conference on , vol. 1. IEEE, 2010, pp. 224–228.
[5] J. Lee, G.-L. Park, H. Kim, Y.-K. Yang, P. Kim, and S.-W. Kim, “A telematics service system based on the linux cluster,” in International Conference on Computational Science . Springer, 2007, pp. 660–667.
[6] A. Glaschenko, A. Ivaschenko, G. Rzevski, and P. Skobelev, “Multi-agent real time scheduling system for taxi companies,” in 8th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2009), Budapest, Hungary , 2009, pp. 29–36.
[7] D.-H. Lee, H. Wang, R. Cheu, and S. Teo, “Taxi dispatch system based on current demands and real-time traffic conditions,” Transportation Research Record: Journal of the Transportation Research Board , no. 1882, pp. 193–200, 2004.
[8] L. Zhang, T. Hu, Y. Min, G. Wu, J. Zhang, P. Feng, P. Gong, and J. Ye, “A taxi order dispatch model based on combinatorial optimization,” in Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . ACM, 2017, pp. 2151–2159.
[9] C. H. Papadimitriou and K. Steiglitz, Combinatorial optimization: algorithms and complexity . Courier Corporation, 1998.
[10] T. Verma, P. Varakantham, S. Kraus, and H. C. Lau, “Augmenting decisions of taxi drivers through reinforcement learning for improving revenues,” in International Conference on Automated Planning and Scheduling , 2017, pp. 409–417.
[11] M. E. Taylor and P. Stone, “Transfer learning for reinforcement learning domains: A survey,” Journal of Machine Learning Research , vol. 10, no. Jul, pp. 1633–1685, 2009.
[12] S. J. Pan and Q. Yang, “A survey on transfer learning,” IEEE Transactions on knowledge and data engineering , vol. 22, no. 10, pp. 1345–1359, 2010.
[13] J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska et al. , “Overcoming catastrophic forgetting in neural networks,” Proceedings of the National Academy of Sciences , vol. 114, no. 13, pp. 3521–3526, 2017.
[14] Y. Teh, V. Bapst, W. M. Czarnecki, J. Quan, J. Kirkpatrick, R. Hadsell, N. Heess, and R. Pascanu, “Distral: Robust multitask reinforcement learning,” in Advances in Neural Information Processing Systems , 2017, pp. 4499–4509.
[15] A. A. Rusu, N. C. Rabinowitz, G. Desjardins, H. Soyer, J. Kirkpatrick, K. Kavukcuoglu, R. Pascanu, and R. Hadsell, “Progressive neural networks,” arXiv preprint arXiv:1606.04671 , 2016.
[16] E. Parisotto, J. L. Ba, and R. Salakhutdinov, “Actor-mimic: Deep multitask and transfer reinforcement learning,” arXiv preprint arXiv:1511.06342 , 2015.
[17] I. Higgins, A. Pal, A. A. Rusu, L. Matthey, C. P. Burgess, A. Pritzel, M. Botvinick, C. Blundell, and A. Lerchner, “Darla: Improving zero-shot transfer in reinforcement learning,” arXiv preprint arXiv:1707.08475 , 2017.
[18] A. Maurer, M. Pontil, and B. Romera-Paredes, “The benefit of multitask representation learning,” The Journal of Machine Learning Research , vol. 17, no. 1, pp. 2853–2884, 2016.
[19] Z. Luo, Y. Zou, J. Hoffman, and L. F. Fei-Fei, “Label efficient learning of transferable representations acrosss domains and tasks,” in Advances in Neural Information Processing Systems , 2017, pp. 164–176.
[20] Z. Xu, Z. Li, Q. Guan, D. Zhang, W. Ke, Q. Li, J. Nan, C. Liu, W. Bian, and J. Ye, “Large-scale order dispatch in on-demand ridesharing platforms: a learning and planning approach,” in Proceedings of the 24rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . ACM, 2018.
[21] C. J. C. H. Watkins and P. Dayan, “Q-learning,” Machine Learning , vol. 8, no. 3-4, pp. 279–292, May 1992.
[22] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al. , “Human-level control through deep reinforcement learning,” Nature , vol. 518, no. 7540, pp. 529–533, 2015.
[23] Z. Wang and M. E. Taylor, “Improving Reinforcement Learning with Confidence-Based Demonstrations,” in Proceedings of the 26th International Conference on Artificial Intelligence (IJCAI) , August 2017.
[24] H. Van Hasselt, A. Guez, and D. Silver, “Deep reinforcement learning with double q-learning.” in AAAI , 2016, pp. 2094–2100.
[25] R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction . MIT press Cambridge, 1998, vol. 1, no. 1.
[26] G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” science , vol. 313, no. 5786, pp. 504–507, 2006.















 853
853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









