






PCT:点云Transformer
Meng-Hao Guo Tsinghua University gmh20@mails.tsinghua.edu.cn Jun-Xiong Cai Tsinghua University caijunxiong000@163.com Zheng-Ning Liu Tsinghua University lzhengning@gmail.com Tai-Jiang Mu Tsinghua University taijiang@tsinghua.edu.cn Ralph R. Martin Cardiff University ralph@cs.cf.ac.uk Shi-Min Hu Tsinghua University shimin@tsinghua.edu.cn
摘要
不规则域和缺乏有序性使得设计用于点云处理的深层神经网络具有挑战性。提出了一种新的点云学习框架点云Transformer(PCT)。
PCT是基于Transformer的,它在自然语言处理方面取得了巨大的成功,在图像处理方面显示出巨大的潜力。它在处理点序列时具有固有的置换不变性,因此非常适合点云学习。为了更好地捕获点云中的局部上下文,我们通过支持最远点采样和最近邻搜索来增强输入嵌入。大量实验表明,PCT在形状分类、零件分割、语义分割和正常估计任务上达到了最先进的表现。
1、引言
在机器人、自动驾驶、增强现实等应用中,直接从点云中提取语义是一项迫切的需求。与2D图像不同,点云是无序的、非结构化的,因此设计神经网络来处理它们是一项挑战。
Qi等人[21]开创了点网在点云上的特征学习,通过使用多层感知器(MLP)、最大池和刚性变换来确保在置换和旋转下的不变性。受卷积神经网络(CNN)在图像处理领域取得的巨大进展的启发,许多最近的工作【24、17、1、31】都考虑定义卷积算子,以聚集点云的局部特征。这些方法要么对输入点序列重新排序,要么对点云进行体素化,以获得卷积的规范域。
最近,自然语言处理的主流框架Transformer(26)已被应用于图像视觉任务,其表现优于流行的卷积神经网络(7,30)。Transformer是一种解码器-编码器结构,包含三个主要模块,分别用于输入(字)嵌入、位置(顺序)编码和自我注意力。自我注意力模块是核心组件,它根据全局上下文为输入特征生成精确的注意力特征。首先,自我注意将输入嵌入和位置编码之和作为输入,通过训练的的线性层为每个单词计算三个向量:查询、关键字和值。然后,通过匹配(点乘)查询和关键向量,可以获得任意两个单词之间的注意力权重。最后,将注意力特征定义为所有值向量与注意力权重的加权和。显然,每个单词的输出注意力特征与所有输入特征相关,使其能够学习全局上下文。Transformer的所有操作都是可并行和顺序独立的。理论上,它可以代替卷积神经网络中的卷积运算,具有更好的通用性。有关自我关注的更多详细引言,请参阅第3.2节。
受Transformer在视觉和NLP任务方面的成功启发,我们基于传统Transformer的原理,提出了一种新的点云学习框架PCT。
PCT的核心思想是利用Transformer固有的顺序不变性,避免定义点云数据的顺序,并通过注意力机制进行特征学习。如图1所示,注意力权重的分布与部分语义高度相关,并且不会随空间距离而严重衰减。
点云和自然语言是非常不同的数据类型,因此我们的PCT框架必须对此进行一些调整。其中包括:•基于坐标的输入嵌入模块。在Transformer中,使用位置编码模块来表示自然语言中的词序。这可以区分不同位置的同一单词,并反映单词之间的位置关系。
但是,点云没有固定的顺序。在我们的PCT框架中,我们将原始位置编码和输入嵌入合并到一个基于坐标的输入嵌入模块中。它可以生成可区分的特征,因为每个点都有表示其空间位置的唯一坐标。
•优化的偏移注意模块。我们提出的抵消注意力模块方法是对原有自我注意力的有效升级。它的工作原理是用自我注意力模块的输入和注意力特征之间的偏移量替换注意力特征。
这有两个优点。首先,刚性变换可以使同一对象的绝对坐标完全不同。因此,相对坐标通常更稳健。其次,拉普拉斯矩阵(度矩阵和邻接矩阵之间的偏移量)在图卷积学习中被证明是非常有效的。从这个角度来看,我们将点云视为一个带有“浮动”邻接矩阵的图形,作为注意力图。此外,我们工作中的注意力图将被缩放,每行的总和为1。因此,度矩阵可以理解为单位矩阵。因此,偏移注意优化过程可以大致理解为拉普拉斯过程,将在第3.3节详细讨论。此外,我们已经做了充分的对比实验,如第4节所介绍的,关于偏移注意和自我注意,以证明其有效性。
•邻居嵌入模块。显然,句子中的每个单词都包含基本的语义信息。然而,这些点的独立输入坐标仅与语义内容弱相关。注意力机制在捕获全局特征方面是有效的,但它可能会忽略局部几何信息,而局部几何信息对于点云学习也是必不可少的。为了解决这个问题,我们使用邻居嵌入策略来改进点嵌入。它还通过考虑包含语义信息的局部点组(而不是单个点)之间的注意力来辅助注意力模块。
通过上述调整,PCT变得更适合点云特征学习,并在形状分类、部分分割和正常估计任务上实现了最先进的表现。
本文的主要贡献概括如下:1。我们提出了一种新的基于transformer的点云学习框架PCT,该框架非常适合于非结构化、无序的不规则域点云数据。
2、我们提出了使用隐式拉普拉斯算子和归一化细化的偏移注意,与Transformer中的原始自我注意模块相比,该模块具有固有的置换不变性,更适合点云学习。
3、大量实验表明,具有显式局部上下文增强的PCT在形状分类、部分分割和正常估计任务上都达到了最先进的表现。
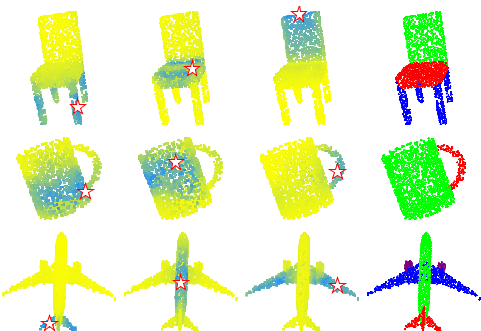
图1:。由PCT生成的注意力图和部分分割。前三列:不同查询点的点式注意力图(由I表示),黄色到蓝色表示注意力权重增加。最后一列:零件分割结果。
2、相关工作
2.1. NLP中的Transformer
Bahdanau等人[2]提出了一种具有注意力机制的神经机器翻译方法,其中通过RNN的隐藏状态计算注意力权重。Lin等人[18]提出了自我注意,以可视化和解释句子嵌入。在此基础上,Vaswani等人[26]提出将Transformer用于机器翻译;它完全基于自我注意,没有任何复发或卷积算子。Devlin等人[6]提出了双向transformers(BERT)方法,这是NLP领域最强大的模型之一。最近,语言学习网络,如XLNet[36]、Transformer XL[5]和BioBERT[15]进一步扩展了Transformer框架。
然而,在自然语言处理中,输入是有序的,单词具有基本语义,而点云是无序的,单个点一般没有语义。
2.2. Transformer for vision
许多框架将注意力引入了视觉任务中。Wang等人[27]提出了一种剩余注意力方法,该方法使用堆叠的注意力模块进行图像分类。Hu等人【10】提出了一种新的空间编码单元SE块,其思想源自注意力机制。Zhang el al.(38)设计了萨根,它利用自我关注来塑造生成的形象。将Transformer作为优化神经网络的模块也有越来越多的趋势。Wu等人[30]提出了视觉transformers,将Transformer应用于视觉任务特征图中基于token的图像。最近,Dosovitskiy[7]提出了一种基于补丁编码和Transformer的图像识别网络ViT,表明在足够的训练数据下,Transformer比传统的卷积神经网络提供更好的表现。Carion等人[4]提出了一种端到端检测transformer,它将CNN特征作为输入,并使用transformer编码器-解码器生成边界框。
受ViT中使用的局部补丁结构和语言词中的基本语义信息的启发,我们提出了一个邻居嵌入模块,该模块从点的局部邻域中聚合特征,从而捕获局部信息并获取语义信息。
2.3. 基于点的深度学习
PointNet【21】开创了点云学习。随后,Qi等人提出了点网++[22],它使用查询球分组和分层点网来捕获局部结构。随后的几项工作考虑了如何在点云上定义卷积运算。一种主要方法是将点云转换为常规体素阵列,以允许卷积操作。Tchapmi等人[24]提出了用于逐点分割的SEGCloud。它使用三线性插值将三维体素的卷积特征映射到点云,并通过完全连通的条件随机场保持全局一致性。Atzmon等人[1]提出了PCNN框架,其中包含扩展和限制操作符,用于在基于点的表示和基于体素的表示之间进行映射。对体素进行体积卷积以提取点特征。Hermosilla等人[8]的MCCNN允许非均匀采样点云;卷积被视为蒙特卡罗积分问题。类似地,在Wu等人[31]提出的PointConv中,通过蒙特卡罗估计和重要性抽样执行3D卷积。
另一种方法是重新定义卷积以对不规则点云数据进行运算。Li等人【17】介绍了一种点云卷积网络PointCNN,其中对χ-变换进行训练的,以确定卷积的1D点顺序。Tatarchenko等人[23]提出了切线卷积,它可以从投影的虚拟切线图像中学习曲面几何特征。Lan-drieu等人[13]提出的SPG将扫描的场景划分为相似的元素,并建立一个超点图结构来学习对象部分之间的上下文关系。Pan等人[35]使用并行框架将CNN从传统领域扩展到弯曲的二维流形。然而,它需要密集的三维网格数据作为输入,因此不适用于三维点云。Wang等人[29]为动态图设计了EdgeConv操作符,允许通过恢复局部拓扑进行点云学习。
其他各种方法也使用注意力和变换器。Yan等人[34]提出了PointASNL来处理点云处理中的噪声,使用自我注意机制来更新局部点组的特征。Hertz等人[9]提出了PointGMM,用于多层感知器(MLP)分割和注意力分割的形状插值。
与上述方法不同,我们的PCT基于transformer,而不是将自我注意作为辅助模型。Wang等人[28]的一个框架使用transformer优化点云注册,而我们的PCT是一个更通用的框架,可用于各种点云任务。
3、点云表示的Transformer
在本节中,我们首先展示如何将PCT学习到的点云表示应用于点云处理的各种任务,包括点云分类、部分分割和法线估计。之后,我们详细介绍了PCT的设计。我们首先介绍了一种简单的PCT版本,将原始的transformer直接应用于点云。然后,我们解释了完整的PCT及其特殊的注意力机制,以及邻居聚合以提供增强的局部信息。
3.1. 使用PCT进行点云处理
编码器。PCT的总体架构如图2所示。PCT旨在将输入点转换(编码)为一个新的高维特征空间,该空间可以表征点之间的语义相似度,作为各种点云处理任务的基础。PCT的编码器首先将输入坐标嵌入新的特征空间。嵌入的特征随后被输入到4个堆叠的注意力模块中,学习每个点的语义丰富且有区别的表示,然后是一个线性层来生成输出特征。总的来说,PCT的编码器与原Transformer的设计理念几乎相同,只是位置嵌入被丢弃了,因为点的坐标已经包含了这些信息。我们请读者参考[26]了解原始NLP Transformer的详细信息。
形式上,给定一个输入点云P∈ R N×d,N个点各有d维特征描述,首先通过输入嵌入模块学习d e维嵌入特征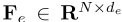 。然后,通过将每个注意力层的注意力输出通过特征维度串联,然后进行线性变换,形成PCT输出的逐点d o维特征表示
。然后,通过将每个注意力层的注意力输出通过特征维度串联,然后进行线性变换,形成PCT输出的逐点d o维特征表示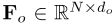 :
:
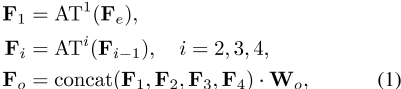
,其中AT i表示第i个注意力层,每个注意力层具有与其输入相同的输出维度,W o是线性层的权重。稍后将解释输入嵌入和注意力的各种实现。
为了提取表示点云的有效全局特征向量F g,我们选择将两个池操作符的输出串联起来:学习的逐点特征表示上的最大池(MP)和平均池(AP)[29]。
分类使用PCT的分类网络的详细信息如图2所示。为了将点云P分类为N c对象类别(例如桌子、桌子、椅子),我们将全局特征F g馈送给分类解码器,该解码器包括两个级联前馈神经网络LBR(结合线性、BatchNorm(BN)和ReLU层),每个层的dropout概率为0。5,通过线性层最终预测最终分类得分C∈ R N c。将点云的类标签确定为得分最大的类。
细分。对于将点云分割为N-s部分的任务(例如,桌面、桌腿;分离不需要连续),我们必须预测每个点的分离标签,我们首先将全局特征F g与F o中的逐点特征连接起来。为了学习各种对象的通用模型,我们还将一个热门对象类别向量编码为64维特征,并将其与全局特征连接,这与大多数其他点云分割网络类似【22】。如图2所示,分段网络解码器的体系结构几乎与分类网络的体系结构相同,只是仅在第一个LBR上执行退出。然后我们预测最终的逐点分割分数S∈ 输入点云的R N×N s:最后,点的零件标签也被确定为得分最大的标签。
正常估计。对于正态估计任务,我们使用与分割中相同的架构,设置N s=3,不使用对象类别编码,并将输出的逐点得分视为预测正态。
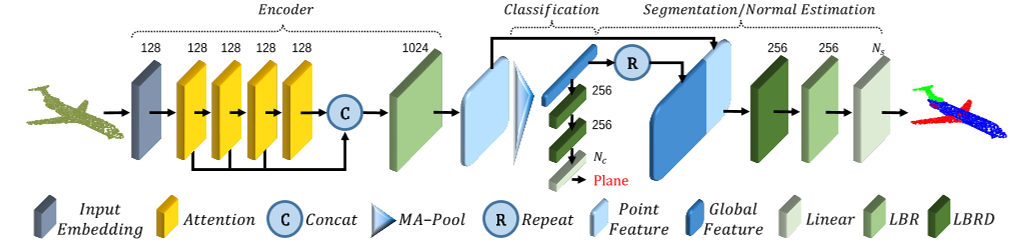
图2:。PCT架构。编码器主要包括一个输入嵌入模块和四个堆叠的注意力模块。解码器主要包括多个线性层。每个模块上方的数字表示其输出通道。MA池连接最大池和平均池。LBR将线性层、BatchNorm层和ReLU层相结合。LBRD是指LBR后跟Dropout层。
3.2. 天然PCT
修改Transformer(26)以使用点云的最简单方法是将整个点云视为一个句子,将每个点视为一个单词,我们现在介绍了这种方法。这种天真的PCT是通过实现基于坐标的点嵌入和实例化注意力层,以及【26】中介绍的自我注意力来实现的。
首先,我们考虑一个天真的点嵌入,它忽略了点之间的相互作用。与NLP中的单词嵌入一样,点嵌入的目的是在语义更相似的情况下,将点更靠近嵌入空间。具体来说,我们将点云P嵌入到d维空间F e中∈ R N×d e,使用由两个级联LBR组成的共享神经网络,每个LBR具有d e维输出。
为了提高计算效率,我们根据经验设置d e=128,这是一个相对较小的值。我们只需使用点的3D坐标作为其输入特征描述(即d p=3)(因为这样做仍优于其他方法),但也可以使用额外的点方向输入信息,如点法线。
对于PCT的朴素实现,我们采用了原始transformer中引入的自我关注(SA)[26]。自我注意,也称为内部注意,是一种计算数据序列中不同项目之间语义亲和力的机制。SA层的架构如图3所示,切换到虚线数据流。按照【26】中的术语,让Q、K、V分别为通过输入特征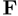
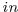
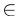
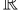
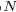
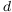
 的线性变换生成的查询、键和值矩阵,如下所示:
的线性变换生成的查询、键和值矩阵,如下所示:
其中,W Q、W K和W V是共享的可学习线性变换,d a是查询和键向量的维数。请注意,d a可能不等于d e。在这项工作中,为了提高计算效率,我们将DA设置为e/4。
首先,我们可以使用查询矩阵和键矩阵通过矩阵点积计算注意力权重:

然后对这些权重进行归一化(图3中表示为SS),以给出 :
:
自注意力输出特征F sa是使用相应注意力权重

作为查询的值向量的加权和,键矩阵和值矩阵由共享的对应线性变换矩阵和输入特征F in确定,它们都是阶独立的。More-over、softmax和加权和都是与置换无关的算子。因此,整个自我注意过程是排列不变的,这使得它非常适合点云呈现的无序、不规则区域。
最后,通过LBR网络(
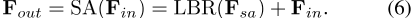
3.3),进一步使用自我注意特征F sa和输入特征F in为整个sa层提供输出特征F out。偏移注意图卷积网络[3]显示了使用拉普拉斯矩阵L=D的好处− E替换邻接矩阵E,其中dis是对角度矩阵。同样,我们发现,如果将Transformer应用于点云时,我们用偏移注意(OA)模块替换原始的自我注意(SA)模块来增强PCT,我们可以获得更好的网络表现。如图3所示,偏移注意层通过元素相减计算自我注意(SA)特征和输入特征之间的偏移(差)。该偏移量为LBR网络提供数据,以代替naıĕĕve版本中使用的SA功能。
具体而言,方程式5修改为:
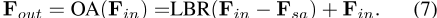
F in− F sa类似于离散拉普拉斯算子,如我们现在所示。首先,从方程式2和5可以看出:这里的
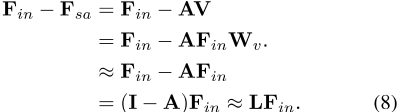
,W-vis被忽略,因为它是线性层的权重矩阵。I是与拉普拉斯矩阵的对角度矩阵D相当的单位矩阵,A是与邻接矩阵E相当的注意力矩阵。
在我们的增强版PCT中,我们还通过如下修改等式4来完善正态化:
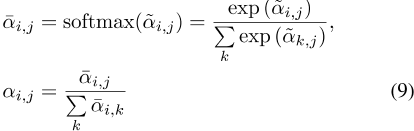
在这里,我们在第一维度上使用softmax操作符,在第二维度上使用l 1范数来规范化注意力图。传统的Transformer将第一个维度缩放1/√ d a,并使用softmax规范化第二个维度。然而,我们的偏移注意力可以提高注意力权重并减少噪音的影响,这对下游任务是有益的。图1显示了偏移注意力贴图的示例。可以看出,不同查询点的注意力映射差别很大,但通常在语义上有意义。我们在实验中将这种改进的PCT,即具有点嵌入和OA层的PCT称为简单PCT(SPCT)。
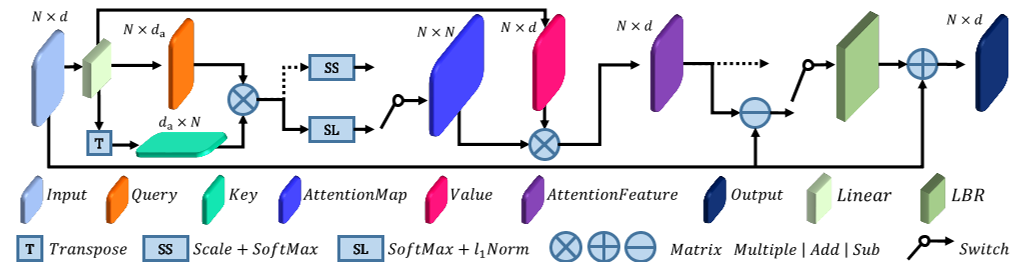
图3:。抵消注意力的架构。张量上方的数字是维度N和特征通道D/D a的数字,开关显示自我注意或偏移注意的替代方案:虚线表示自我注意分支。
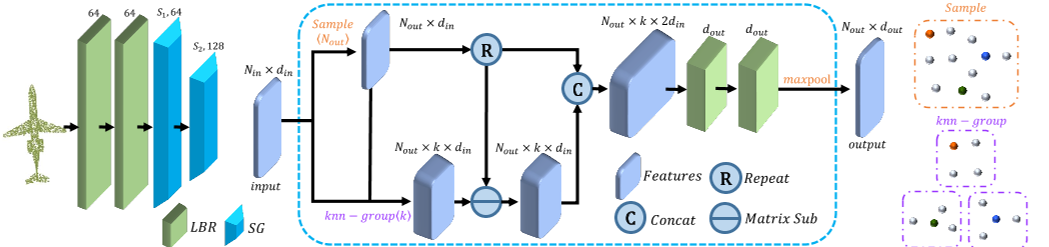
图4:。左:邻居嵌入架构;中间:SG模块,具有N个输入点、din输入通道、k个相邻点、N个输出采样点和D个输出通道;右上:采样示例(彩色球表示采样点);右下角:使用k-NN邻居分组的示例;LBR以上的数量:输出通道的数量。SG以上的数量:采样点及其输出通道的数量。
3.4. 基于邻域嵌入的增广局部特征表示
点嵌入PCT是一种有效的全局特征提取网络。然而,它忽略了在点云学习中同样重要的局部邻域信息。我们借鉴PointNet++[22]和DGCNN[29]的思想,设计了一种局部邻居聚合策略,邻居嵌入,以优化点嵌入,增强PCT的局部特征提取能力。
如图4所示,邻居嵌入模块包括两个LBR层和两个SG(采样和分组)层。LBR层作为第3.2节中嵌入的基点。在特征聚合过程中,我们使用两个级联的SG层来逐渐扩大感受野,就像在CNN中所做的那样。在点云采样过程中,SG层使用欧几里德距离为k-NN搜索分组的每个点聚合来自本地邻居的特征。
更具体地说,假设SG层将具有N个点和相应特征的点云P作为输入,并输出具有N个s点及其相应聚合特征F s的采样点云P s。首先,我们采用最远点采样(FPS)算法[22]对P top s进行下采样。然后,对于每个采样点p∈ 设knn(P,P)为P中的k近邻。然后,我们计算输出特征F s,如下所示:
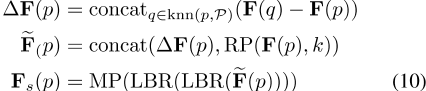
,其中F(p)是点p的输入特征,F s(p)是采样点p的输出特征,MP是最大池运算器,RP(x,k)是用于将向量x k次重复以形成矩阵的算子。将采样点及其相邻点之间的特征连接起来的想法来自EdgeConv【29】。
我们使用不同的体系结构来完成点云分类、分割和法线估计的任务。对于点云分类,我们只需要预测所有点的全局类,因此点云的大小在两个SG层内分别减少到512和256个点。
对于点云分割或法线估计,我们需要确定逐点零件标签或法线,因此上述过程仅用于局部特征提取,而不减少点云大小,这可以通过将每个阶段的输出设置为大小仍然为N来实现。
4、实验
现在,我们在两个公共数据集ModelNet40[32]和ShapeNet[37]上评估了naıúúve PCT(NPCT,具有点嵌入和自我注意)、简单PCT(SPCT,具有点嵌入和偏移注意)和完全PCT(具有邻居嵌入和偏移注意)的表现,并与其他方法进行了综合比较。
在每种情况下,采用与[29]相同的软交叉熵损失函数和动量为0.9的随机梯度下降(SGD)优化器进行训练。其他训练参数,包括学习率、批量大小和输入格式,是每个特定数据集的特定参数,稍后给出。
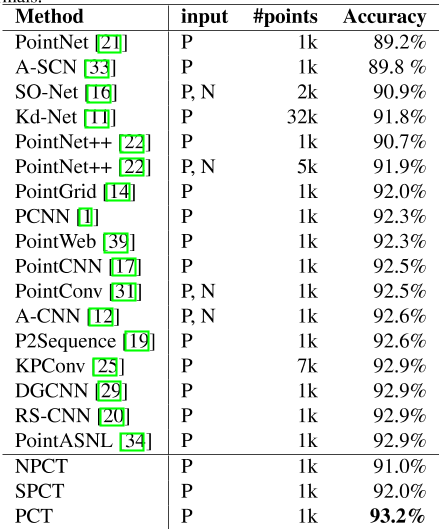
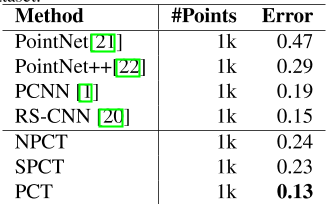
表1:。与Mod-elNet40分类数据集上的最新方法进行比较。准确度是指整体准确度。所有引用的结果均取自引用的论文。P=点,N=法线。
4.1. ModelNet40数据集分类
ModelNet40[32]包含40个对象类别中的12311个CAD模型;它广泛用于点云形状分类和曲面法线估计基准测试。为了进行公平比较,我们使用了官方划分,9843个对象用于训练,2468个对象用于评估。采用与PointNet[21]中相同的采样策略,将每个对象均匀采样到1024个点。在训练期间,在[− 0 . 2 , 0 . 2] ,使用[0.67,1.5]中的随机各向异性缩放和随机输入dropout来增加输入数据。在测试期间,未使用数据扩充或投票方法。对于所有三个模型,小批量大小为32,使用了250个训练阶段,初始学习率为0.01,并使用余弦调整计划来调整每个阶段的学习率。
实验结果如表1所示。与PointNet和NPCT相比,SPCT分别提高了2.8%和1.0%。PCT的最佳结果为93。2%的总体精度。请注意,我们的网络目前没有将法线作为输入,原则上可以进一步提高网络表现。
4.2. ModelNet40数据集的正态估计
曲面法线估计是确定每个点的法线方向。估计曲面法线在渲染等领域有着广泛的应用。这项任务具有挑战性,因为它需要了解表2的形状。Mod-elNet40数据集的正态估计平均余弦距离误差。
完全用于密集回归。我们再次使用模型-Net40作为基准,并使用平均余弦距离来测量地面真实值和预测法线之间的差异。对于这三个模型,都使用了32200个训练时期的批量。初始学习率也设置为0.01,使用余弦退火计划调整每个历元的学习率。如表2所示,与PointNet相比,我们的NPCT和SPCT都有显著的改进,PCT的平均余弦距离最低。
4.3. ShapeNet数据集上的分段任务
点云分割是一项具有挑战性的任务,其目的是将三维模型划分为多个有意义的部分。
我们对ShapeNet零件数据集[37]进行了实验评估,该数据集包含16880个3D模型,通过训练测试14006到2874的分割。它有16个对象类别和50个零件标签;每个实例包含不少于两个部分。在PointNet【21】之后,所有模型都被降采样到2048个点,保留逐点零件注释。训练期间,在[− 0 . 2 , 0 . 2] ,并应用[0.67,1.5]中的随机各向异性缩放来增加输入数据。在测试期间,我们使用了一种多尺度测试策略,其中尺度设置为[0.7,1.4],步长为0。1.对于这三个模型,批量大小、训练时间和学习率都设置为与正常估计任务的训练相同。
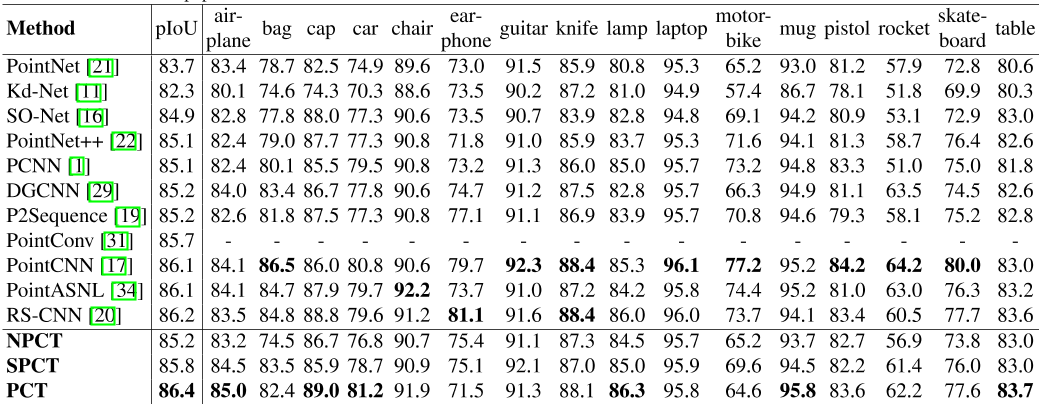
表3显示了按类划分的结果。使用的评估指标是联合上的部分平均交集,并给出了总体和每个对象类别的评估指标。结果表明,我们的SPCT改进了2。1%和0。分别比PointNet和NPCT高6%。PCT以86分获得最佳结果。4%部分-接头上的平均交点。图5显示了PointNet、NPCT、SPCT和PCT提供的进一步细分示例。
4.4. S3DIS数据集的语义分割任务
S3DIS是用于点云语义分割的室内场景数据集。它包含6个区域和271个房间。
数据集中的每个点分为13个类别。为了进行公平比较,我们使用了与[21]相同的数据处理方法。表4显示,与之前的方法相比,我们的PCT实现了优异的表现。
表3:。ShaperNet零件分割数据集的比较。pIoU表示并集上的部分平均交点。所有引用的结果均取自引用的论文。
4.5. 计算需求分析
现在,我们通过比较表5中所需的浮点运算(FLOPs)和参数数量(Params),来考虑NPCT、SPCT、PCT和其他几种方法的计算要求。SPCT的内存需求最低,只有1.36M的参数,而且处理器的负载也很低,只有1.82 GFLOPs,但可以提供高度准确的结果。这些特性使其适合部署在移动设备上。PCT的表现最好,但计算和内存需求适中。如果我们追求更高的表现,而忽略计算量和参数,我们可以在输入嵌入模型中添加一个邻居嵌入层。三层嵌入PCT的结果如表6和表7所示。
5、结论
本文提出了一种置换不变点云transformer,适用于不规则域非结构化点云的学习。建议的抵消注意和规范化机制有助于使我们的PCT有效。实验表明,PCT具有良好的语义特征学习能力,在形状分类、零件分割和正常估计等多个任务上都取得了最新的表现。
Transformer已经在提供大量训练数据的情况下展示了强大的能力。目前,与im相比,可用的点云数据集非常有限。未来,我们将在更大的数据集上对其进行训练,并研究其相对于其他流行框架的优缺点。此外,Transformer的编解码结构支持更复杂的任务,如点云的生成和完成。我们将把PCT扩展到更多应用。
参考文献
[1] Matan Atzmon, Haggai Maron, and Yaron Lipman. Point convolutional neural networks by extension operators. ACM Transactions on Graphics , 37(4):71:1–71:12, 2018.
[2] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. In International Conference on Learning representations , 2015.
[3] Joan Bruna, Wojciech Zaremba, Arthur Szlam, and Yann Le- Cun. Spectral networks and locally connected networks on graphs. In Yoshua Bengio and Yann LeCun, editors, international Conference on Learning Representations , 2014.
[4] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nico- las Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-End object detection with transformers. CoRR , abs/2005.12872, 2020.
[5] Zihang Dai, Zhilin Yang, Yiming Yang, Jaime G. Carbonell, Quoc Viet Le, and Ruslan Salakhutdinov. Transformer- xl: Attentive language models beyond a fixed-length con- text. In Anna Korhonen, David R. Traum, and Lluı́s Màrquez, editors, Association for Computational Linguis- tics , pages 2978–2988. Association for Computational Lin- guistics, 2019.
[6] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: pre-training of deep bidirectional trans- formers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio, editors, North American chapter of the Association for Computational Linguistics: Human Language Technologies , pages 4171–4186. Association for Computational Linguistics, 2019.
表4:。在Area5上测试的S3DIS语义分割数据集上进行比较。

.
图5:。来自PointNet、NPCT、SPCT、PCT dnd地面实况(GT)的分段。
表5:。计算资源需求。
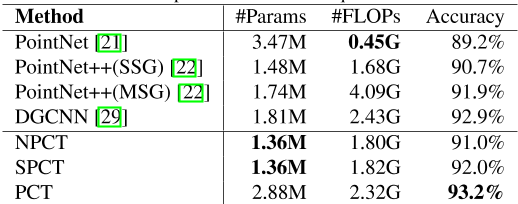
表6:。ModelNet40分类数据集上的比较。PCT-2L表示具有2个层邻居嵌入的PCT,PCT-3L表示具有3个层邻居嵌入的PCT。准确度是指整体准确度。P=点。

[7] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. CoRR , abs/2010.11929, 2020.
[8] Pedro Hermosilla, Tobias Ritschel, Pere-Pau Vázquez, Àlvar Vinacua, and Timo Ropinski. Monte carlo convolution for learning on non-uniformly sampled point clouds. ACM Transactions on Graphics , 37(6):235:1–235:12, 2018.
[9] Amir Hertz, Rana Hanocka, Raja Giryes, and Daniel Cohen- Or. PointGMM: A neural GMM network for point clouds. In IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 12051–12060. IEEE, 2020.
[10] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation net- works. In IEEE Conference on Computer Vision and pattern Recognition , pages 7132–7141. IEEE Computer Soci- ety, 2018.
表7:。ShaperNet零件分割数据集的比较。pIoU表示并集上的部分平均交点。PCT-2L表示具有2个层邻居嵌入的PCT,PCT-3L表示具有3个层邻居嵌入的PCT。

[11] Roman Klokov and Victor S. Lempitsky. Escape from cells: Deep kd-networks for the recognition of 3d point cloud mod- els. In IEEE International Conference on Computer Vision , pages 863–872. IEEE Computer Society, 2017.
[12] Artem Komarichev, Zichun Zhong, and Jing Hua. A-CNN: annularly convolutional neural networks on point clouds. In IEEE Conference on Computer Vision and Pattern recognition , pages 7421–7430. Computer Vision Foundation / IEEE, 2019.
[13] Loı̈c Landrieu and Martin Simonovsky. Large-scale point cloud semantic segmentation with superpoint graphs. In IEEE Conference on Computer Vision and Pattern recognition , pages 4558–4567. IEEE Computer Society, 2018.
[14] Truc Le and Ye Duan. Pointgrid: A deep network for 3d shape understanding. In IEEE Conference on Computer vision and Pattern Recognition , pages 9204–9214. IEEE computer Society, 2018.
[15] Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics , 36(4):1234–1240, 2020.
[16] Jiaxin Li, Ben M. Chen, and Gim Hee Lee. So-net: Self- organizing network for point cloud analysis. In IEEE conference on Computer Vision and Pattern Recognition , pages 9397–9406. IEEE Computer Society, 2018.
[17] Yangyan Li, Rui Bu, Mingchao Sun, Wei Wu, Xinhan Di, and Baoquan Chen. PointCNN: Convolution on x- transformed points. In Advances in Neural Information processing Systems , pages 828–838, 2018.
[18] Zhouhan Lin, Minwei Feng, Cı́cero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. A structured self-attentive sentence embedding. In international Conference on Learning Representations . OpenRe- view.net, 2017.
[19] Xinhai Liu, Zhizhong Han, Yu-Shen Liu, and Matthias Zwicker. Point2sequence: Learning the shape representation of 3d point clouds with an attention-based sequence to sequence network. In AAAI Conference on Artificial intelligence , pages 8778–8785. AAAI Press, 2019.
[20] Yongcheng Liu, Bin Fan, Shiming Xiang, and Chunhong Pan. Relation-shape convolutional neural network for point cloud analysis. In IEEE Conference on Computer Vision and Pattern Recognition , pages 8895–8904. Computer vision Foundation / IEEE, 2019.
[21] Charles Ruizhongtai Qi, Hao Su, Kaichun Mo, and Leonidas J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In IEEE Conference on Computer Vision and Pattern Recognition , pages 77–85. IEEE Computer Society, 2017.
[22] Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in Neural information Processing Systems , pages 5099–5108, 2017.
[23] Maxim Tatarchenko, Jaesik Park, Vladlen Koltun, and Qian- Yi Zhou. Tangent convolutions for dense prediction in 3d. In IEEE Conference on Computer Vision and Pattern recognition , pages 3887–3896. IEEE Computer Society, 2018.
[24] Lyne P. Tchapmi, Christopher B. Choy, Iro Armeni, JunY- oung Gwak, and Silvio Savarese. SEGCloud: Semantic seg- mentation of 3d point clouds. In International Conference on 3D Vision , pages 537–547. IEEE Computer Society, 2017.
[25] Hugues Thomas, Charles R. Qi, Jean-Emmanuel Deschaud, Beatriz Marcotegui, Francois Goulette, and Leonidas J. Guibas. Kpconv: Flexible and deformable convolution for point clouds. In IEEE/CVF International Conference on Computer Vision , pages 6410–6419. IEEE, 2019.
[26] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems , pages 5998–6008, 2017.
[27] Fei Wang, Mengqing Jiang, Chen Qian, Shuo Yang, Cheng Li, Honggang Zhang, Xiaogang Wang, and Xiaoou Tang. Residual attention network for image classification. In IEEE Conference on Computer Vision and Pattern Recognition , pages 6450–6458. IEEE Computer Society, 2017.
[28] Yue Wang and Justin Solomon. Deep closest point: Learning representations for point cloud registration. In IEEE/CVF International Conference on Computer Vision , pages 3522– 3531. IEEE, 2019.
[29] Yue Wang, Yongbin Sun, Ziwei Liu, Sanjay E. Sarma, Michael M. Bronstein, and Justin M. Solomon. Dynamic graph CNN for learning on point clouds. ACM Transactions on Graphics , 38(5):146:1–146:12, 2019.
[30] Bichen Wu, Chenfeng Xu, Xiaoliang Dai, Alvin Wan, Peizhao Zhang, Masayoshi Tomizuka, Kurt Keutzer, and peter Vajda. Visual transformers: Token-based image representation and processing for computer vision. CoRR , abs/2006.03677, 2020.
[31] Wenxuan Wu, Zhongang Qi, and Fuxin Li. PointConv: Deep convolutional networks on 3d point clouds. In IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 9621–9630, 2019.
[32] Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Lin- guang Zhang, Xiaoou Tang, and Jianxiong Xiao. 3d shapenets: A deep representation for volumetric shapes. In IEEE Conference on Computer Vision and Pattern Recogni- tion, CVPR 2015, Boston, MA, USA, June 7-12, 2015 , pages 1912–1920. IEEE Computer Society, 2015.
[33] Saining Xie, Sainan Liu, Zeyu Chen, and Zhuowen Tu. At- tentional shapecontextnet for point cloud recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , June 2018.
[34] Xu Yan, Chaoda Zheng, Zhen Li, Sheng Wang, and Shuguang Cui. PointASNL: Robust point clouds processing using nonlocal neural networks with adaptive sampling. In IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 5588–5597. IEEE, 2020.
[35] Yuqi Yang, Shilin Liu, Hao Pan, Yang Liu, and Xin Tong. PFCNN: convolutional neural networks on 3d surfaces using parallel frames. In IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 13575–13584. IEEE, 2020.
[36] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime G. Carbonell, Ruslan Salakhutdinov, and Quoc V. Le. Xlnet: generalized autoregressive pretraining for language understanding. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché-Buc, Emily B. Fox, and Roman Garnett, editors, Advances in Neural Information Processing Systems , pages 5754–5764, 2019.
[37] Li Yi, Vladimir G. Kim, Duygu Ceylan, I-Chao Shen, Mengyan Yan, Hao Su, Cewu Lu, Qixing Huang, Alla Shef- fer, and Leonidas J. Guibas. A scalable active framework for region annotation in 3d shape collections. ACM Trans. Graph. , 35(6):210:1–210:12, 2016.
[38] Han Zhang, Ian J. Goodfellow, Dimitris N. Metaxas, and Augustus Odena. Self-attention generative adversarial net- works. In Kamalika Chaudhuri and Ruslan Salakhutdi- nov, editors, International Conference on Machine Learning , volume 97 of Proceedings of Machine Learning Research , pages 7354–7363. PMLR, 2019.
[39] Hengshuang Zhao, Li Jiang, Chi-Wing Fu, and Jiaya Jia. Pointweb: Enhancing local neighborhood features for point cloud processing. In IEEE Conference on Computer Vision and Pattern Recognition , pages 5565–5573. Computer vision Foundation / IEEE, 2019.















 1181
1181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









