







这篇论文提出了在神威太湖之光上的SpMV框架,这篇和前两篇有一个共同的作者李肯立,查了一下现在的情况是:“2022年9月至今,湖南大学党委常委、副校长,兼信息科学与工程学院院长、国家超级计算长沙中心主任”。
神威太湖之光一共有40960个SW26010处理器,每个SW26010处理器有4个Core Group(CG),每个CG有64个Computing Processing Element(CPE)。除此之外每个CG还有一个Management Processing Element(MPE)核,所以一个处理器一共有260个核,整个神威太湖之光有10,649,600核,超过一千万。
每个CG有8GB的DDR3内存,供其中的核心访问。其中MPE有32KB的L1 data cache和256KB的L2 data/instruction cache。每个CPE有一个16KB的L1 instruction cache和64KB的Scrath Pad Memory(SPM),这个SPM也被称为Local Data Memory(LDM)。
CPE访存有两种方式,一种是直接访存,一种是使用DMA进行大量连续数据的存取。CPE没有cache,DMA一定程度上代替了cache的作用,DMA的访存是远远快于直接访存的。但访存的数据是连续的内存,大小大于512B,并且是128B的倍数,那么使用DMA访存可以达到34GB/s的峰值速度。
SW26010处理器的结构示意图如下:

通用的SpMV方法在神威太湖之光上的执行有以下瓶颈:
-
Storage limitation:LDM的空间比较小,一次能装的数据少,很多时候一个LDM甚至装不下大型稀疏矩阵一行(列)的数据
-
Load imbalance:CG间负载均衡(不同处理器中的CG也看做一样)、CPE间负载均衡
-
Huge overhead of irregular memory accesses:CPE直接访存远不如DMA快,儿四种常见结构COO、CSR、ELL、CSC都包括对输入向量x或输出向量y的不规则直接访存
本文提出的CASpMV框架使用了多种方法加速SpMV在神威太湖之光上的执行:
-
A four-way partition scheme:不仅是把行分配给CG,还把过长的行切成短行
-
An auto-tuner based on a sparse matrix statistical model:这个是用来调整上一个方法的参数的,比如多长的行向量叫做过长?这两个方法解决瓶颈1和2
-
The accelerative SpMV:调整了SpMV的计算流程,过程中存在几次不同格式矩阵间的转换,用来解决瓶颈3
-
Optimization methods:针对神威太湖之光的硬件结构进行的优化,如SIMD技术、并行流水线、DMA带宽优化、double-buffering机制
下面分别讲一下这些技术
A Four-way Partition Scheme for SpMV
分为四部分:
-
CG-level Partition:将行分配给不同的CG,使每个CG非零元个数差不多相等。这个分配并不像上一篇论文讲到的先排序再分配,而是直接遍历按非零元素个数分配。可能因为上一篇提到的方法在神威太湖之光上的应用效果并不好。
-
Customized Partition:分配给CG的某些行可能会过长,不能直接装到64KB的LDM里,所以需要进一步切成小的部分。
-
CPE-level Partition:上一步形成的小行,需要按照非零元个数分配给CPE。具体方法应该和第1部分一样。这几步最终想要的结果是,每个最小的执行单元CPE,需要得到差不多数量的非零元。
-
LDM-level Partition:每个CPE最终会得到VS个小行,当时这VS个小行也不能一起加载进LDM里,每次需要挑几行(步骤2保证了至少能装一行)进行运算。
An auto-tuner based on a sparse matrix statistical model
这是用来计算Customized Partion的阈值K,基于的是标准差。
分配给一个CG的所有行的长度,会有一个标准差。如果将过长行切小,标准差会减小。但是如果切的太小,额外的辅助空间需求会变得很大。所以要在能存得下的情况下将长行切短,文中的方法似乎是根据LDM的值算出阈值的上下限,然后遍历的话从下限遍历到上限。
具体的切的方法是,比方说阈值为K,一个超过K的行为M,将M切出尽可能多的K,最后剩下比K还短的一截或者根本什么都不剩下。
是不是阈值越小标准差一定就越小呢?并不是这样,比如三个向量长度为8 8 8,阈值上下限为3-6,阈值为3时切成3 3 3 3 3 3 2 2 2,标准差大于零,阈值为4时切成4 4 4 4 4 4,标准差等于0,所以要想得到最小的标准差,真的需要从下限尝试到上限。
The accelerative SpMV
这一步主要分为两部分,Column Multiplication(CM)和Row Addition(RA)。
CM部分,只有CSC格式是不会进行无规则的访存的,因为每一列都只乘x中的一个值。
分配给每个CG的是原矩阵的一个子矩阵,这个子矩阵和x进行乘法计算,我们可以更改计算顺序,使x中的每个值乘子矩阵的每一列。这样的思想体现在上面的four-way partition上,就是customized partition那一步, 原来是将长行切成短行,现在是要将长列切成短列。之后计算呢,就是按列分配给CPE,也是尽量保证每个CPE的非零元相等。在之后同样是CPE由于LDM大小限制,一次不能load过多列。
论文中的图示如下:
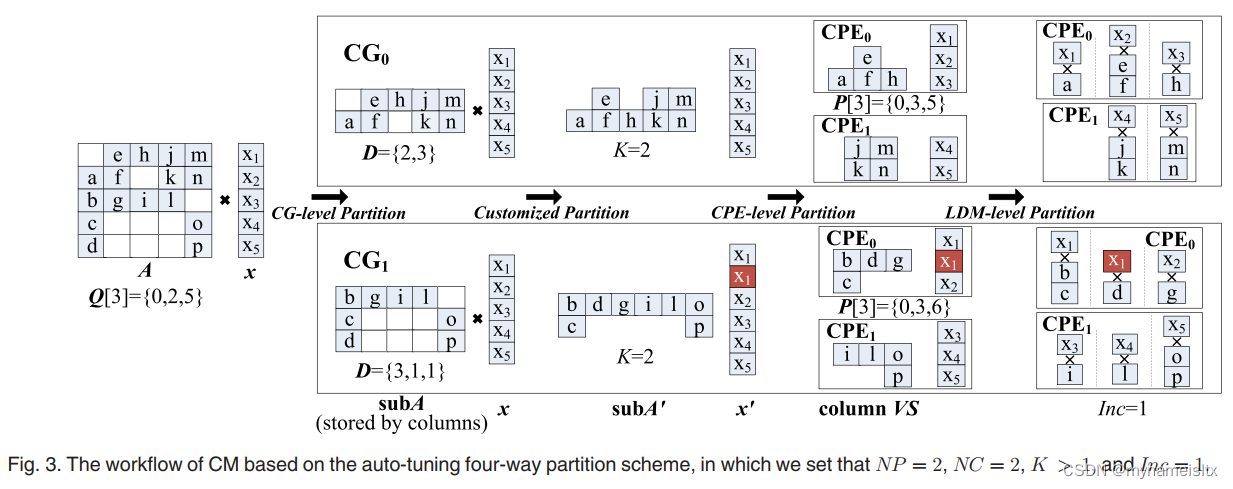
图中有几个辅助的数据也需要存储,Q存放每个CG分别分配到了哪几行;D是行长度为1、2、3…的列各有多少个;P存放每个CPE分别分配到了哪几列。
图中的红色x1说明是有的列被切成短列了,多出的一列需要在x向量对应位置补上对应元素,后面计算的就是subA’和x’的矩阵乘法。
RA部分,CSR和ELL方法是不随机访问y的,论文中应该是选择了CSR格式,它和CSC比较相近。
第一步的CM部分的结果是一个中间的稀疏矩阵,它的每一个非零元素都被x乘过了,在RA部分,我们先将这个CSC格式的矩阵转回CSR,这个转换过程是在MPE中进行的。之后要将每一行加起来。
每一行的加和也是要在CPE中执行,长的行也是要切成短的行。然后将短行按照非零元素个数分配给CPE,CPE根据LDM大小限制,每次加载几个短行加和。
图示如下:

需要注意的是,这张图和上一张图的abcd并不代表矩阵上对应位置的元素,只是表明CSC或CSR顺序。上面CG0中的ehjmafkn对应这里CG0中的中间结果abcdefgh。
其中也是有几个辅助数组,Au用来表示大行被切成了几小行,如CG1中Au[3]={2,1,1}中的2就表明前两小行ij和kl在原矩阵属于同一行,之后的y3’+y4’也是根据这个Au来的;P数组记录每个CPE分配到了subA’中的哪几行。
Optimization methods
硬件相关的优化又分成了几个小方面
-
Computation Optimization:每个CPE的浮点数计算单元是一个七阶段流水线,如果流水线之间的数据都不相关,那么每个时钟周期都可以输出。并且处理器提供SIMD技术,每个阶段流水线又可以同时处理四个不相关的数据,因此如果数据都不相关,流水线每周期都可以计算出四个浮点数结果。所以可以利用上处理器提供的SIMD技术。
-
Communication Optimization:为了尽量使DMA带宽变大,需要尽量使传输的数据大于等于512B,且时128B的倍数。
-
The Double-Buffering Mechanism:CPE使用DMA有读和写两种操作,如果buffer大小只够一次读/写,那么会是读1,计算1,写1,读2,计算2,写2这样的过程,但是通信和计算是可以同时进行的,所以可以使buffer大小变为原来两倍,就可以读1,计算1&读2,写1&计算2,写2,数量多的话大概能节省一半周期。
各方法对性能的贡献

最后总结一下,从上面的性能贡献图可以看出,贡献最大的是Accelerative SpMV和硬件相关Optimizations,其中Accelerative SpMV中最重要的是将SpMV分为CM和RA两部分,在CM计算完成得到中间矩阵之后,在CG中将CSC格式转为了CSR格式,然后再进行RA部分的计算,避免了对内存的不规则访问;Optimizations中最重要的是对硬件足够了解,比如知道处理器提供了SIMD、传输多少数据时DMA带宽最大、CPE计算和使用DMA通信可以同时进行。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









