







这篇论文讲了一种新的格式Compressed Sparse eXtended(CSX),这种格式把矩阵在行、列、主副对角线、分块上的结构都识别了出来,然后分别用不同的方式存储。
CSX基于CSR-DU格式,这种格式记录的是列坐标之间的差,因此数值更小。如果都不超过256,那么可以用一个Byte存储。256而不是255是因为列坐标的差不为零,所以0可以代表256。一般处理器都有分支预测,所以这个判断并不影响速度。下面是图示:
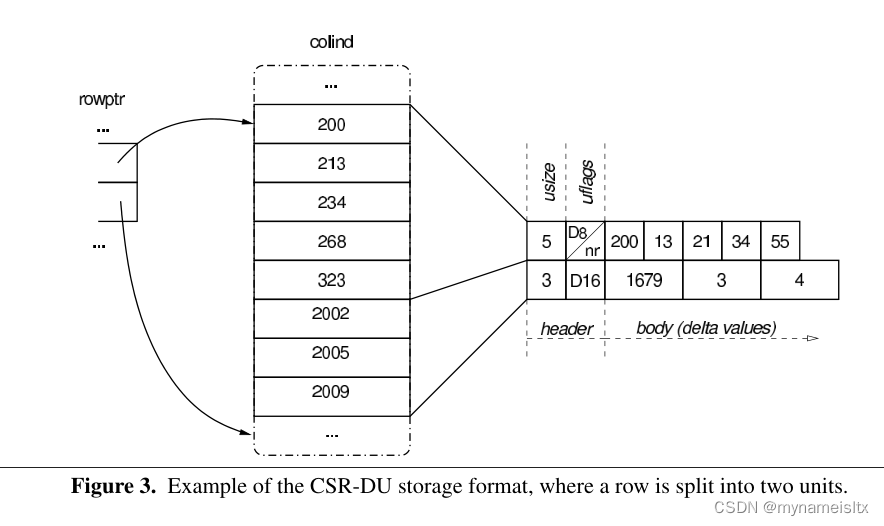
CSX在CSR-DU的理念上进行了扩展,不仅探测行上的结构单元,还探测列、主副对角线、分块上的稠密单元。这些不同的探测方向被CSX用一套滑动窗口的框架统一了。
CSX的另一个理念是在进行多步迭代之前,使用LLVM在线生成CSR格式的稀疏矩阵的矩阵乘法计算代码。虽然这个编译优化是要占用不少时间的,但是由于很多迭代算法会一直使用同一个矩阵,所以有可能整体上降低计算时间。LLVM能优化什么呢?我觉得应该是稀疏矩阵上面常量的一些优化,比如乘2/4/8改成位移,以及一些连续元素的向量操作优化。既然可以现场编译,我觉得也可以JIT,这可能也是一个研究方向。
CSX统一探测的基础在于水平方向上的探测,如下图所示:

Figure 5中,41 61 81不能被探测到,因为长度不够。1 21 41 61 81也不能被探测出来,因为为了算法运行的效率,不支持这样的overlapped run。探测出来间隔一样的,应该是为了压缩,这样只用记录间隔为多少,有几个就行了。
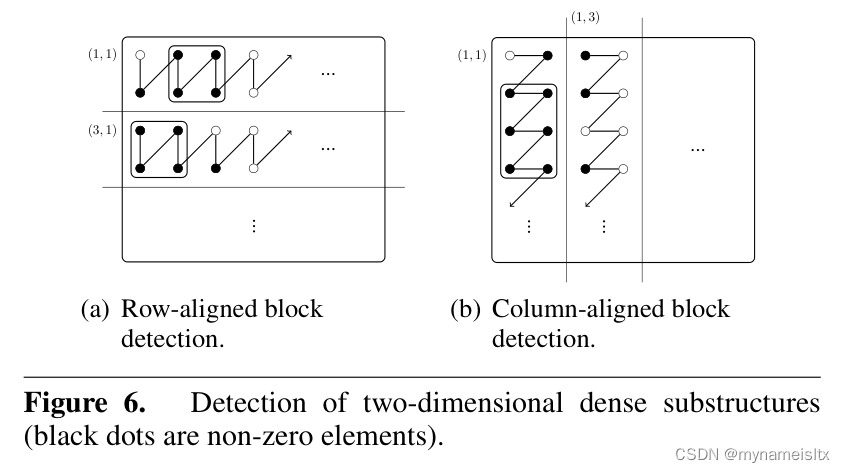
对于列、对角线的方法都一样,对角线的话是分成不同对角线,对每个对角线分别探测。探测分块有两点不一样,一是步长只能为1,另外只能探测到一整个矩形,因为不对齐的矩形会增加额外的复杂度。2D探测图示:
将特征提取出来之后,就是用LLVM编译并优化不同的部分,然后进行计算,论文中没有细讲。
论文还提供的一个重要的信息,我们知道SpMV的瓶颈在于内存带宽,论文中提到核数越多,内存带宽的影响就越大。其实也很好理解,核数多了算得就快,但还是一个内存,带宽的问题就凸显了。
总结一下,论文的主要思想在于将矩阵在不同方面的特征都提取出来,如行、列、主副对角线、分块等。另一个思想在于在多次使用同一稀疏矩阵的时候,提前进行优化。缺点是提取的特征越详尽就越花费时间,提前优化也是同样。















 4240
4240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









