







 本文收集并整理了互联网上能找到的开源推荐系统,并附上了个人的一些简单点评,覆盖了从单机版推荐神器SVDFeature到分布式推荐平台Mahout,再到基于Python的Lenskit等,提供详细的技术特性与使用建议。
本文收集并整理了互联网上能找到的开源推荐系统,并附上了个人的一些简单点评,覆盖了从单机版推荐神器SVDFeature到分布式推荐平台Mahout,再到基于Python的Lenskit等,提供详细的技术特性与使用建议。
以下内容是转至盛大创新研究院官方博客的一篇文章http://in.sdo.com/?p=1707,文中几乎涵盖了当今主流的推荐系统开源软件,我把全文都贴过来了,不过与原文不同的是我把有些已经停止更新/或者更新很慢的都往后面排了。另外也写写自己的一些使用总结。
原文开始:
收集和整理了目前互联网上能找到的开源推荐系统,并附上了个人的一些简单点评(未必全面准确),这个列表是目前为止比较全面的了,希望对大家了解掌握推荐系统有帮助(文/陈运文)
SVDFeature
由上海交大的同学开发,采用C++语言,代码质量很高。去年我们参加KDD竞赛时用过,很好很方便,而且出自咱们国人之手,所以置顶推荐!
SVDFeature包含一个很灵活的Matrix Factorization推荐框架,能方便的实现SVD、SVD++等方法, 是单模型推荐算法中精度最高的一种。SVDFeature代码精炼,可以用相对较少的内存实现较大规模的单机版矩阵分解运算。
另外含有Logistic regression的model,可以很方便的用来进行ensemble运算
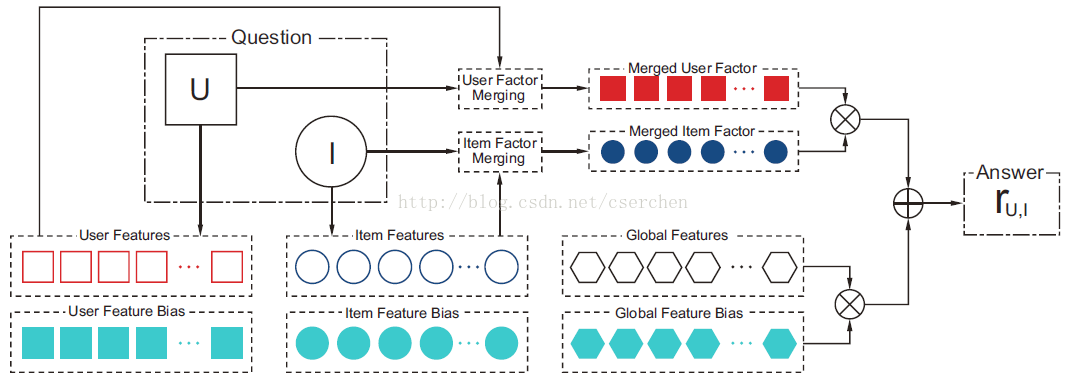
备注:这个真是单机版 推荐神器,能在4G的电脑上,跑1.5G的用户-物品评分数据,而且速度也还可以,当时给我吃了一惊。该项目文档相当齐全包含:理论和样例的demo,把评分预测当做矩阵分解、分类、Ranking来做。正如项目介绍,它提供了特征-矩阵分解的框架,你只需腾出双手,结合业务场景去提取用户的特征。如果用来参加推荐/机器学习方面的比赛,其中的GBRT跟逻辑回归的各种模型集成,更是加了一层保证。总而言之,它就是你的欧莱雅,你值得拥有!
Mahout
网址
Mahout知名度很高,它是Apache基金资助的重要项目,在国内流传很广,并已经有一些中文相关书籍了。注意Mahout是一个分布式机器学习算法的集合,协同过滤只是其中的一部分。除了被称为Taste的分布式协同过滤的实现(Hadoop-based,另有pure Java版本),Mahout里还有其他常见的机器学习算法的分布式实现方案。

另外Mahout的作者之一Sean Owen基于Mahout开发了一个试验性质的推荐系统,称为Myrrix, 可以看这里:
http://myrrix.com/quick-start/
备注:也许受到到graphlab跟PredictOI等大数据预测软件的压力,最近Mahout也加快了更新速度,截止现在已经到了V0.9了。这个库最大的优势是能处理大的数据量,里面不仅有推荐还有分类,回归,主题模型等,具体做推荐的时候还可以结合业务修改下相似度计算公式MyMediaLite
基于.NET框架的C#开发(也有Java版本),作者基本来自德国、英国等欧洲的一些高校。
除了提供了常见场景的推荐算法,MyMediaLite也有Social Matrix Factorization这样独特的功能
尽管是.Net框架,但也提供了Python、Ruby等脚本语言的调用API
MyMediaLite的作者之一Lars Schmidt在2012年KDD会议上专门介绍过他们系统的一些情况,可惜由于.Net开发框架日渐式微,MyMediaLite对Windows NT Server的系统吸引力大些,LAMP网站用得很少
备注:这个软件也是相当的赞,不仅算法完整,文档清晰,还提供指标测试、交叉验证寻参等,需要注意的一点是,当数据量较大的时候,最好要重新编译一下C#的运行库Mono --with-large-heap=yes 把内存搞大一点,不然很容易out of memory。
GraphLab
项目地址:
Graphlab是基于C++开发的一个高性能分布式graph处理挖掘系统,特点是对迭代的并行计算处理能力强(这方面是hadoop的弱项),
由于功能独到,GraphLab在业界名声很响
用GraphLab来进行大数据量的random walk或graph-based的推荐算法非常有效。
Graphlab虽然名气比较响亮(CMU开发),但是对一般数据量的应用来说可能还用不上
备注:正如软件的名字一样,该软件专注于图方面的挖掘,不过其中包含一个推荐的toolkit,里面有很多矩阵分解类的算法,另外该软件的另外一个兄弟Graphchi,又一大单机神奇。前段新闻,就说Mac mini笔记本部署的grapchi 在推特图谱的计算上超越了1613节点的hadoop。我做的另外一个应用就是在一台服务器上部署了Graphchi ,在中等数据量上毫无鸭梨。



LibFM
项目网址:
作者是德国Konstanz University的Steffen Rendle,去年KDD Cup竞赛上我们的老对手,他用LibFM同时玩转Track1和Track2两个子竞赛单元,都取得了很好的成绩,说明LibFM是非常管用的利器(虽然在Track1上被我们打败了,hiahia)
顾名思义,LibFM是专门用于矩阵分解的利器,尤其是其中实现了MCMC(Markov Chain Monte Carlo)优化算法,比常见的SGD(随即梯度下降)优化方法精度要高(当然也会慢一些)
顺便八卦下,去年KDD会议上和Steffen当面聊过,他很腼腆而且喜欢偷笑,呵呵挺可爱。
备注:在预测评分方面是神奇,不过相对来讲速度较慢,尤其用MCMC算法的时候,不过总的来说还是非常好的一款软件
LibMF
项目地址:
http://www.csie.ntu.edu.tw/~cjlin/libmf/
注意LibMF和上面的LibFM是两个不同的开源项目。这个LibMF的作者是大名鼎鼎的台湾国立大学,他们在机器学习领域享有盛名,近年连续多届KDD Cup竞赛上均获得优异成绩,并曾连续多年获得冠军。台湾大学的风格非常务实,业界常用的LibSVM, Liblinear等都是他们开发的,开源代码的效率和质量都非常高
LibMF在矩阵分解的并行化方面作出了很好的贡献,针对SDG优化方法在并行计算中存在的locking problem和memory discontinuity问题,提出了一种矩阵分解的高效算法,根据计算节点的个数来划分评分矩阵block,并分配计算节点。系统介绍可以见这篇论文(Recsys 2013的 Best paper Award)
Y. Zhuang, W.-S. Chin, Y.-C. Juan, and C.-J. Lin. A Fast Parallel SGD for Matrix Factorization in Shared Memory Systems. Proceedings of ACM Recommender Systems 2013.
备注:我相信Libsvm,很多人用过,没错,这个LibMF就是林志仁教授那个团队写的,速度、质量值得信赖
Lenskit
这个Java开发的开源推荐系统,来自美国的明尼苏达大学,也是推荐领域知名的测试数据集Movielens的作者,
他们的推荐系统团队,在学术圈内的影响力很大,很多新的学术思想会放到这里
备注:明尼苏达大学推荐团队的杰作,另外该团队还在Coursera上开了一门推荐系统 的公开课,课程的作业就可以用这个软件来做。
Crab
项目地址:

系统的Tutorial可以看这里:
Crab是基于Python开发的开源推荐软件,其中实现有item和user的协同过滤。据说更多算法还在开发中,
Crab的python代码看上去很清晰明了,适合一读
备注:Python写的,其中的作者就是下面的Python-recsys作者,看github上一个印度的哥们(猜的,挺黑的,呵呵)。
CofiRank
C++开发的 Collaborative Filtering算法的开源推荐系统,但似乎2009年后作者就没有更新了,
CofiRank依赖boost库,联编会比较麻烦。不是特别推荐
项目地址:
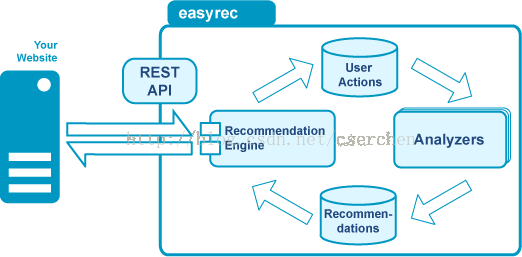
EasyRec
Java开发的推荐系统,感觉更像一个完整的推荐产品,包括了数据录入模块、管理模块、推荐挖掘、离线分析等,整个系统比较完备。
项目地址:
PREA
全名是 Personalized Recommendation Algorithms Toolkit, 开发语言为Java。也是一个轻量级的开源项目
项目网址:
放在Mloss这个大project下。我个人感觉PREA还是比较简陋的,参加开发的三位工程师Joonseok Lee, Mingxuan Sun, Guy Lebanon更新频率很低,提供的资料也少。
不过Mloss下倒是能找到其他一些推荐开源项目
Python-recsys
一个非常轻量级的开源推荐系统,python开发,作者似乎只有一位,
Python-recsys主要实现了SVD、Neighborhood SVD推荐算法,
这个项目麻雀虽小五脏俱全,评估数据(Movielens,Last.fm)、评估框架也都有
API也很简单清晰,代码简洁,属于推荐入门的良好教材。
不过真正要用到实际系统中,还是得补充很多内容
github的地址位于
项目的介绍见:
备注:用过,不过使用的时候发现两次运行的结果不一致,让我很是蛋疼,另外运行速度一般(尽管可以用稀疏的矩阵库,但速度还是不敢恭维)。
RapidMiner
项目网址为:
Java语言开发,RapidMiner(前身是Yale)已经是一个比较成熟的数据挖掘解决方案了,包括常见的机器学习、NLP、推荐、预测等方法(推荐只占其中很小一部分),而且带有GUI的数据分析环境,数据ETL、预处理、可视化、评估、部署等整套系统都有。

另外RapidMiner提供commercial license,提供R语言接口,感觉在向着一个商用的数据挖掘公司的方向在前进。
Recommendable
基于Ruby语言开发,实现了一些评分预测的推荐算法,但是整体感觉比较单薄,
github上地址如下:
备注:没用过。
Recommenderlab
基于R语言开发的开源推荐程序,对经常使用R语言的工程师或者BI数据分析师来说,recommenderlab的出现绝对算得上是福音了
项目地址:

基于Recommenderlab来开发推荐系统,代码会非常精简,因为推荐系统所依赖的user-item rating matrix对擅长处理向量运算的R语言来说再方便不过了,
但是在实际推荐系统中,需要考虑的问题和逻辑都比较复杂,用Recommenderlab不是很灵活。另外受限于R语言对内存的限制,Recommenderlab不太适用于过大规模的推荐应用
备注:速度跟内存,还是需要考虑的问题。
Waffles
SF地址:
Waffles英文原意是蜂蜜甜饼(见logo),在这里却指代一个非常强大的机器学习的开源工具包,基于C++语言开发。
Waffles里包含的算法特别多,涉及机器学习的方方面面,推荐系统位于其中的Waffles_recommend tool,大概只占整个Waffles的1/10的内容(其它还有分类、聚类、采样、降维、数据可视化、音频处理等许许多多工具包,估计能与之媲美的也就数Weka了)

除了上面的开源软件之外,还有一些其他开源
http://prediction.io/ PredictionIO
http://graphlab.com/products/create/index.html Graphlab的 网页版,目前还在beta
最近火热的Spark















 923
923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









