







一、概述
Spark Streaming是Spark对流式的计算框架,严格意义上说其实并不是真正实时性很高的流式计算,而是以时间片作为批次进行计算。Spark Streaming底层是以Spark Core为基础。
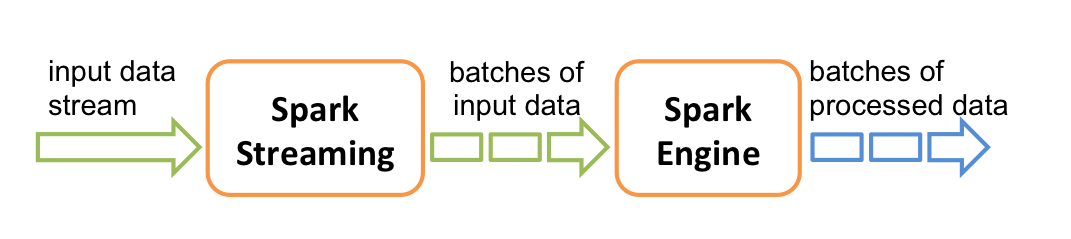
如上图所示,Spark Sreaming 是将流切分成一个一个的批次(batches),然后以批次为单位处理并输出。
Spark Core是以RDD为编程基础,Spark SQL是以DF/DS为编程基础,在Spark Streaming中的编程是以DStream为基础。一个Dreaming= (sequence)(n * RDD)
Spark Core 入口点是sparkContext,Spark SQL的入口点是sparkSession,Spark Streaming的入口点是streamingContext。
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new sparkConf().setMaster("local[2]").setAppName("xx")
val ssc = new StreamingContext(conf,Seconds(1))
Seconds(1)这指的是批次的间隔。这还没有结束,因为只是创建了ssc,还没有配置他的流入口。最简单的就是配置监听Socket。
val dStream = ssc.socketTextStream("localhost",9999)
val dStreamWord = dStream.flatmap(_split(","))
dStreamWord .print()
....
ssc.start()
ssc.awaitTermination()
上面代码片段可以看出,DSream 的算子也是有lazy算子和action算子,只有遇到action算子才能真正开始执行。ssc.start()这句代码说明Spark Streaming需要start之后才能真正的使用,而且start后面的业务逻辑是不会被Spark处理的。
有一个注意点,如果Spark 设置成本地local[N]方式,这个N必须要设置成大于1,因为有一个核是专门来监听的流入口的(就是带有Receiver),如果设置成1将不再就不再有入口点,剩余处理业务也是多余的(除非你的业务不需要接受数据)。比如之前的socketTextStream是一个带接收的,如果使用textFileStream,他的返回值就是一个DStream(不带Receiver),所以要local[1]就可以了。
二、中间状态
有一个业务场景:需要你求当前的热点排名。分析:如果你一个一个批次单独的去计算也只能获取当前的批次内的排名,所以如何进行批次之间的关联就需要用到中间态。
val sc = new SparkConf().setAppName("").setMaster("local[2]")
val ssc = new StreamingContext(sc,Seconds(1))
val dStream = ssc.socketTextStream("localhost",999)
val words = dStream.flatMap(_.split("\t"))
val tuple = words.map(x => (x,1))
//这种方式是每个批次内的wordcount
val wc = tuple.reduceByKey(_+_)
wc.print()
//批次间wordcount
val wcState = tuple.updateStateByKey(updateFunction)
wcState.print()
ssc.start()
ssc.awaitTermination()
按照上述代码的意思,是一个wordcount的代码,相当于求热点。求批次间的热点问题,就是将每个批次的状态保留,然后算结果。知道这个过程,很好,上面的代码是跑不通的,因为没有checkpoint存储路径。所以需要改一下。
//增加checkpoint的路径
ssc.checkpoint("hdfs:///temp/")
所以,每次批次的状态都会存储在这个路径下,以备后面的批次处理所使用,这样有一个问题,HDFS上的小文件数量会非常多,每个批次都要生成新的小文件到checkpoint的路劲下。
下面来看看updateFunction这个函数的作用:
def updateFunction(newValues:Seq[Int], runningCount:Option[Int]):Option[Int] = {
val current = newValues.sum
val old = runningCount.getOrElse(0)
Some(current + old)
}
这个函数的作用,就是将本批次和之前的状态做处理,生成新的状态。上述这个函数的作用就是将当前的批次的结果。newValues这个就是当前的批次结果,这里的key已经被隐藏。Seq[Int] 是value的集合,完整的是(key,seq(value)) 等价于(word,(1,2,1,1))。Option表示可能有也可能没有。所以要用getOrElse,返回Some表示一定有这个元素,并返回值。具体自己详解Scala中Option、Some、None用法。
这样就能运行了嘛?有一个坑在里面,如果你是spark-shell 运行的,就会报错,因为代码需要序列化,才能分布式运行,所以会报错。可以打成jar包用spark-submit方式提交。
还有一个算子也能实现这个updateStateByKey功能,就是mapWithState,在2.x版本中推荐使用mapWithState,这个性能更高。
三、DStream与RDD的操作
在DStream的很多的算子中,大多数都是DStream与Dstream进行操作,比如Join,如果需要DStream与RDD进行操作就需要用到transForm算子:
val sconf = new SparkConf().setAppName("").setMaster("local[2]")
val sc = new SparkContext(sconf)
val ssc = new StreamingContext(sc,Seconds(1))
//一份RDD的黑名单 第一个字段是key,第二个字段是key的属性
val lines = sc.textFile("file:///a.txt")
val blackList = lines.map(_.split("\t")).map(x => (x(0), false))
//一个实时的DStream的流
val dStream = ssc.socketTextStream("localhost",999)
val words = dStream.flatMap(_.split("\t"))
//RDD与DStream操作
//将不在黑名单中的数据程序呈现出来
words.transform(rdd => {
rdd.leftOuterJoin(blackList).filter(x => x._2._2.getOrElse(true) != false).map(_._2._1)
}).print()
transform不是一个action算子,所以需要print作为触发。DStream是一个RDD的集合,所以transform的element是RDD。
四、foreachRDD
在RDD中如果需要将RDD的元素写入到MySQL的数据库中,可定不会使用foreach这个算子,因为MySQL的连接是很宝贵的,不可能给每一个元素开通一个连接,一定是使用foreachPartition,只为每个Partition开通一个连接。在DStream中也是一样的道理。
dstream.foreachRDD { rdd =>
val connection = createNewConnection() // executed at the driver
rdd.foreach { record =>
connection.send(record) // executed at the worker
}
}
上面是官网的源码片段,是错误的,foreachRDD会在Driver端执行,而后的DStream中的RDD会被分发到Executor端执行。所以没办法使用连接。所以建议改成如下方式。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}
五、窗口Window
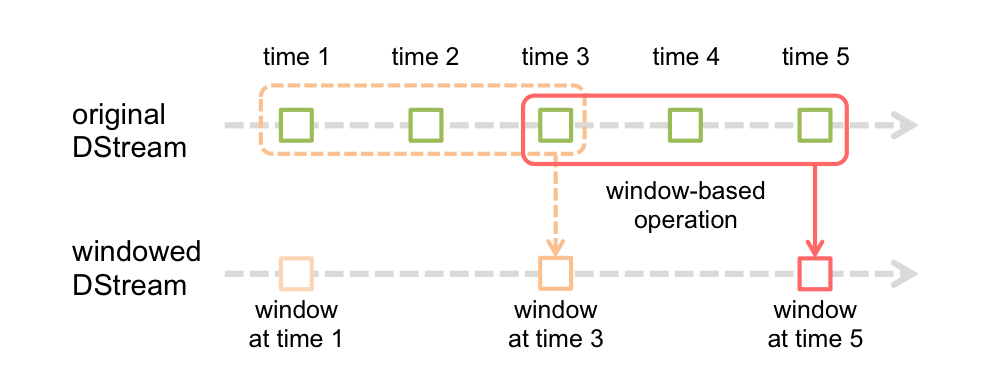
窗口也可以叫做滑动窗口,他的作用获取一段DStream,所以有两个参数考量这个window,一个就是窗口大小,一个就是间隔时常。比如说需求要每隔10秒获取前30秒的数据。
val dStream = ssc.socketTextStream("localhost",999)
val tuple = dStream.flatMap(_.splite("\t")).map(x => (x,1))
.reduceByKeyAndWindow(_+_,Seconds(30),Seconds(10))
凡是算子中带有window的算子其一定带有这两个参数。这样子是不是联想到之前的跨Dstream都要有checkpoint,所以要使用window也是要配置checkpoint。
六、Advenced Source
数据源就是Spark Streaming的入口,有别于之前的数据源(socket、file),高级数据源的入口来着一些其他的组件比如Kafka、Flume等。这些对接还有版本的要求,kafka要求0.8.2.1及以上(),Flume要求1.6.0及以上。
6.1 整合 Flume
因为组件不是在spark中,所以项目工程需要导入相应的依赖,导入spark-streaming-flume_2.11 Jar包。这个包整合了Spark Streaming的一些东西,所以用起来也是很方便的。
import org.apache.spark.streaming.flume._
val dStream = FlumeUtils.createStream(ssc, "localhost",4444)
dStream.map(x => new String(x.event.getBody.array()).trim)
.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_)
.print()
这样就开始监听localhost:4444端口,用于Flume将avro的数据推送到这个端口。这种方式有个弊端因为spark中不包含spark-streaming-flume_2.11.jar包,所以每次spark-submit的时候都要带上(使用–packages,用Maven去下载相关依赖)。当然也可以把包打进你的项目工程,打成胖包(还有设置spark-core,spark-stream的maven为provided),但这样包会变得很大。
还有一种方式不同于之前的push的方式,之前的那种是通过avro的协议push到saprk业务中,这次是将数据拉取。
不同的是原先发送到spark的flume端的sink需要改造:
agent.sinks.spark.type = spark
org.apache.spark.streaming.flume.sink.SparkSink
agent.sinks.spark.hostname = <hostname of the local machine>
agent.sinks.spark.port = <port to listen on for connection from Spark>
业务代码改成:
import org.apache.spark.streaming.flume._
val dStream= FlumeUtils.createPollingStream(ssc, "localhost",4444)
dStream.map(x => new String(x.event.getBody.array()).trim)
.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_)
.print()
还有一点需要注意的就是启动顺序,push的方式,先要启动spark,然后再启动flume,这样flume才能push数据到spark。pull方式先要启动flume,再启动spark,这样spark才能去拉数据。
pull也是需要上传的jar包。
6.2 整合 Kafka
Kafka需要0.8.2.1及以上版本。在kafak 0.8中有两种编程模型一个是旧版(使用spark带Receiver),使用的是kafka高级API。还有新版的
有Receiver的会通过Receiver去从Brocker中获取数据暂存在Spark executor里,然后再启动作业。这种方式会有数据的丢失,如:当spark driver 挂掉了,executor联系不到Driver,所以也跟着挂掉了,这个时候Receiver接收到的数据还存在executor中,所以也一起没了。如何补救?可以使用WAL预写日志的功能,每次接受处理什么的之前会写日志(可以写到HDFS中,定期会被清理),然后即使挂了也会恢复,但是这种方式降低了吞吐量。
添加spark-streaming-kafka-0-8_2.11.jar包
import org.apache.spark.streaming.kafka._
//有Resiver
val topics = "topic_kafka".splite(",").map((_,1)).toMap
val dStream = KafkaUtils.createStream(ssc,"zookeeper:2181","group",topics)
这种的Topic是一个Map,后面的Int表示几个线程来处理(每一个Topic的分区消费个数)。所以这种有Resiver的方式他的RDDs的partition和kafka的partition是没有关系的。
无Resiver。这种方式:
import org.apache.spark.streaming.kafka._
val topics = "topic_kafka".splite(",").toSet
val kafkaParams = Map[String,String](
"serializer.class"->"kafka.serializer.StringEncoder",
"metadata.broker.list"->"xxxxx",
"request.required.acks"->"1"
)
val dStream = KafkaUtils.createDirectStream[String,String,StringDecode,StringDecode](ssc,kafkaParams,topics)
这种方式的Topic是一个Set容器,意味着这种方式的RDD的partition数量和kafka的partition的量是一一对应。
这种方式简化了并行度,每一个RDD的partition对应一个一个kafka的partition用一个线程(spark中的task)去消费。这就涉及到offset的管理。
七、Kafka Offset管理
Spark Streaming对接Kafka的时候,需要理解和掌握kafka的三种语义,最多一次,最少一次,精确一次。最多一次会导致数据丢失,最少一次会导致数据重复,精确一次比较好。但精确一次比较困难,需要管理这种Offset,来保证业务处理完或者入库后才能将Offset更新。同时业务代码中还要求做到幂等,就是每次的操作结果都是一样的,每一次数据处理完或者入库,不能和前一次上的数据不对或者数据增加。
7.1 CheckPoint (不推荐)
这种方式将使用中间态保存数据。
// Function to create and setup a new StreamingContext
def functionToCreateContext(): StreamingContext = {
val ssc = new StreamingContext(sparkConf, Second(10)) // new context
...//kafka papram / topic
val lines = KafkaUtils.createDirectStream[String,String,StringDecode,StringDecode](ssc,kafkaParams,topics)// create DStreams
//可以设置到HDFS上
ssc.checkpoint(".") // set checkpoint directory
lines.checkpoint(Duration(10)) //10s一个周期保存checkpoint
lines.foreachRDD(rdd =>{
println("hello")
})
ssc
}
// Get StreamingContext from checkpoint data or create a new one
// 会从checkpoint的路径下去拿StreamingContext,没有才会调用函数生成StreamingContext
// checkpoint里面保存的不仅是数据,还有StreamingContext,还有操作等等
val ssc = StreamingContext.getOrCreate(".", functionToCreateContext _)
// Do additional setup on context that needs to be done,
// irrespective of whether it is being started or restarted
// Start the context
ssc.start()
ssc.awaitTermination()
checkpoint可以保存未完成操作的状态(如果是kafka有Resiver的还会保存接收到的Data数据),这个是个周期性的保存checkpoint,所以,比如SparkStreaming挂了,再启动的时候知道从哪个Offset开始重新获取(),这种语义是最少一次,需要业务保证幂等性。
checkpoint还有一个比较严重的问题,将代码重新编译,启动Spark Streaming代码,使用checkpoint去读取,发现识别不了之前的数据,这个时候checkpoint中的Offset是无法识别的,会重新按照Spark Stream kafka customer中配置的参数获取最新或者最旧的数据。
同时还有上述的checkpoint的小文件的问题。
7.2 外部存储管理Offset
上述的Spark Streaming 代码都是先从checkpoint获取之前保留的Offset,如果没能取到或者没有,就会从kafka customer的配置参数中按照最新或者最旧的数据开始取。
如果可以在取kafka的时候带上Offset的参数,就可以从你想要的任何一个位置开始取数据,而我们只要自己管理这个Offset做到精确一次的语义就可以。现在spark-streaming-kafka-0-8_2.11.jar中已经能做到。
//伪代码
val offset = GetOffset();
if(offset == null){
//不能获取到Offset,从最新开始获取
val lines = KafkaUtils.createDirectStream[String,String,StringDecode,StringDecode](ssc,kafkaParams,topics)
} else {
//从获取的Offset的地方开始获取
//指定从哪个topic,partition的Offset获取数据。
val formOffsets = Map[TopicAndPartition, Long](...)
val messageHandler = (mm:MessageAndMetadata[String,String]) => (mm.key, mm.value)
val lines = KafkaUtils.createDirectStream[String,String,StringDecode,StringDecode,(String,String)]
(ssc,kafkaParams,formOffsets,messageHandler)
}
......//业务逻辑
//使用upset,插入或更新
//如果要求每次都要把Offset的记录下来,可以在数据库增加一个时间戳的列
//相应的启动时候取最新值
saveOffset()
理解下一个知识点,Offset是管理于每个partition下,kafka Direct Stream中每个RDD的partition和topic的partition是一一关联的,所以在外部存储Offset中,比如存储在mysql里,必须要的列一定有,group,topic,partition,Offset。
值得注意的是Direct Stream去kafka里拿的是一个OffsetRange,是一个范围的Offset,我们需要保存的当然是处理完的一个UntilOffset,所以涉及到Offset的保存的一个问题。RDD的partition和kafka里的topic的partition是对应的,所以可以从RDD中获得Offset的数据。
dStream.foreachRDD(rdd =>{
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
offsetRanges.foreach( offsetRange => {
val topic = offsetRange.topic
val partition = offsetRange.partition
val formOffset = offsetRange.formOffset
val untilOffset = offsetRange.untilOffset
})
})
7.3 高级版本的管理Offset
在spark-streaming-kafka-0-10_2.11.jar版本中。与之前的0.8版本的Api比较,这种新增了kafka自己管理Offset的方式,你可以在你的业务中处理完你的数据,然后使用API异步去更新Offset,这个是由kafka自己管理,一般是kafka存在zookeeper中。
stream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// some time later, after outputs have completed
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}














 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









