







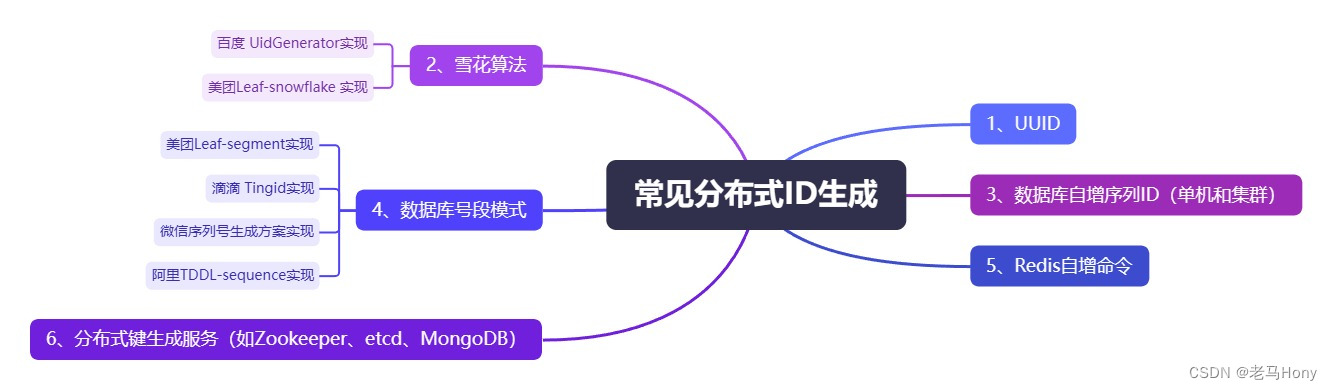
近两年的技术面试,分布式系列问题是面试官经常会问到的一个高频方向。比如:分布式事务、分布式锁、分布式调度、分布式存储、分布式 ID、分布式集群等。
今天我们就来聊聊,这里面相对简单的分布式 ID,首先来说下,我们为什么需要分布式 ID?
当系统数据量过大,数据查询已经达到瓶颈,进行分库分表后,我们需要对分散在各个库表中的数据记录进行唯一标识,从而保证数据完整性以及避免数据冲突。而分布式 ID 恰好用来解决这个问题。
接下来,我们简单看看常见分布式 ID 的生成方案,包括它们的工作原理、优缺点,以及对网络依赖性的考量。最后我们用一个生产中的例子,来教大家怎么使用美团开源框架实现分布式 ID 生成。
1、UUID(通用唯一标识符)
实现原理
UUID(Universally Unique Identifier)的标准型式由 32 个十六进制数组成的字符串和 4 个“-”构成,整体长度为 36。通常基于时间戳、计算机硬件标识符、随机数等元素生成,在分布式系统中可以确保能生成全局唯一的 ID。
UUID 的生成实现方式非常简单,可以通过 java.util 包提供的类即可实现。
import java.util.UUID;
public class Test {
public static void main(String[] args) {
System.out.println("生成长度为36位UUID为:" + UUID.randomUUID());
}
}
//打印结果
//生成长度为36位UUID为:6ddb5acf-565b-4e6e-8da4-32cfcd02e186优缺点
优点:ID 生成性能非常高:本地生成,没有网络消耗。
缺点:无序并且无单调递增,不适合做索引;ID 较长,占用更多存储空间,可能导致存储和索引效率低下。
网络依赖性:无网络依赖。
框架实现
暂无。业界没有使用该方案实现应用场景。
2、数据库单点自增序列
实现原理
选择一个数据库作为中央数据库,利用该库中一个表的自增主键机制生成递增序列值分布式 ID。
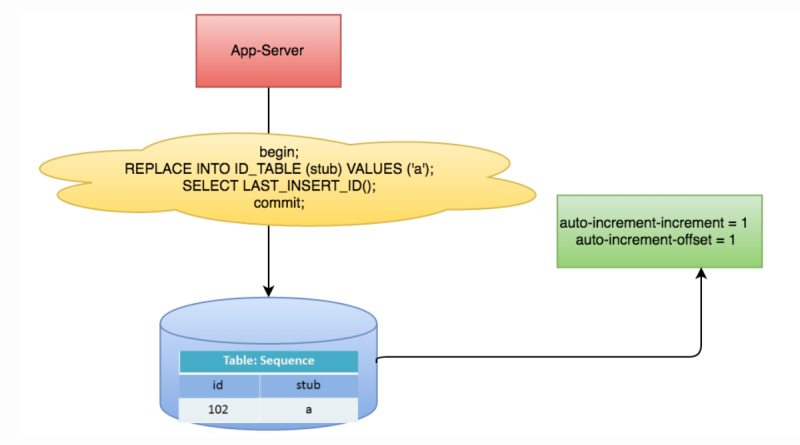
上图事务中的语句可以使用 id_table 表中在保持一条数据记录的情况下,主键 ID 持续递增。
优缺点
优点:简单可靠,单调递增,保证顺序性。
缺点:DB 单点存在宕机风险,可能成为系统的单点故障;无法扛住高并发场景,有性能瓶颈。
网络依赖性:高度依赖网络,所有 ID 生成请求每次都需要访问中央数据库。
框架实现
暂无。由于缺点引起的问题比较严重,业界没有使用该方案实现应用场景。
3、数据库集群下递增序列
实现原理
前边说了单点数据库方式不可取,害怕一个主节点挂掉没法用,换成集群模式。也就是两个 Mysql 实例都能单独的生产自增 ID,并且需要分别设置每台数据库的起始值和步长。
假设有 db1 、db2 和 db3 三个数据库,分别设置这三个库中表的自增起始值为 1、2、3,然后自增步长为数据库实例数都是 3,这样就可以实现集群模式的自增了。
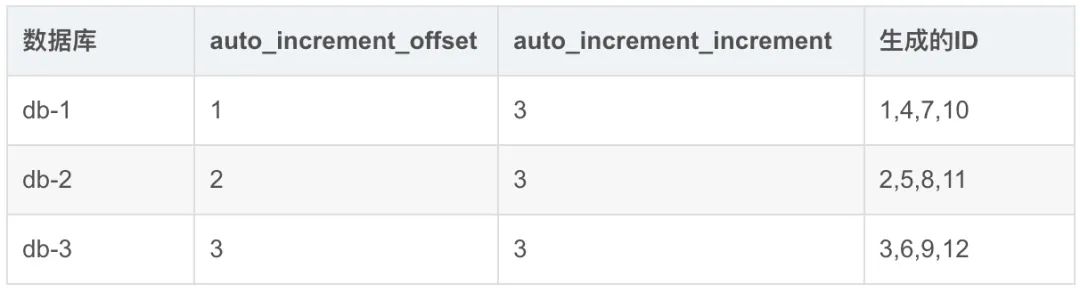
这里的步长Step=auto_increment_increment,架构图如下:
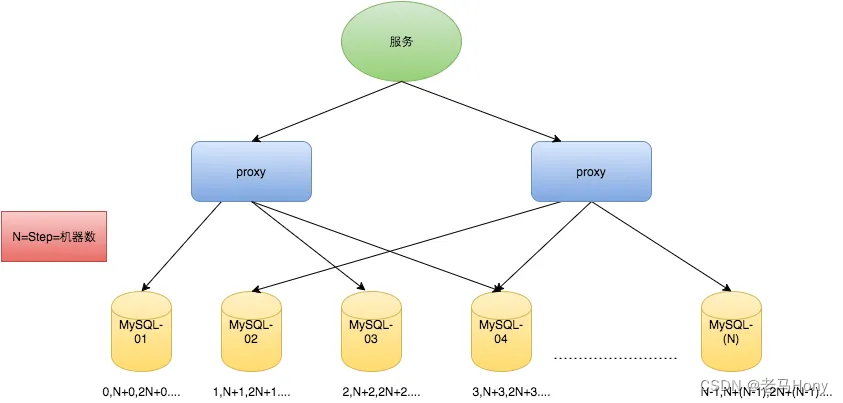
从上图可以看出,由于使用的是数据库的集群架构,客户端一般都是通过代理来访问 DB,这时候代理就需要有负载均衡
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1287
1287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









