






介绍
醒醒……你一直觉得这个世界乱了套。一个奇怪的念头,却无法驱散——就像是脑子里的碎片。你一生都在无所不能的微软强加的限制和规则的地牢中度过,而你却没有意识到这一点。
但是,如果您想继续进入一个仙境,我将向您展示在 SQL Server Express Edition上成功开发的兔子洞有多深……是多么不可能。

时不时,怀着几分情意,回忆起我职业生涯的最初几年……重新粉刷后的草更绿了……当时公司的管理层不太关心各种许可条件……但时代在快速变化,如果您想成为大企业的一部分,就必须遵循市场规则。
这枚奖章的另一面是对资本主义主要真理的痛苦实现——整个企业逐渐被迫迁移到云或支付昂贵的许可证费用。但是,如果有另一种方式——当您不需要为许可证付费,但同时可以自由使用SQL Server 商业版的所有重要优势时会怎样。
现在我们甚至都没有谈论开发者版,微软在2014年完全免费提供了它,尽管它之前愿意以59.95美元的价格出售。更有趣的是生产服务器的成本优化,当危机时期的客户要求最大限度地降低其设备业务成本时。
毫无疑问,现在您已经可以收拾行李并将逻辑迁移到免费的类似物,如PostgreSQL或MariaDB。但是立即出现了一个反问句——在每个人都需要“昨天”完成所有事情的情况下,谁来重写和测试它?并且即使是通过尝试快速迁移企业项目的意志坚强的决定,结果也更有可能成功扮演库尔特·柯本最喜欢的射击游戏而不是发布。因此,我们只会考虑如何在当前的技术限制下充分利用Express Edition。
SQL Server Express Edition初步诊断,医生学院做出:患者在一个socket内最多可以使用4个逻辑核,为Buffer Pool分配1GB多一点的内存,一个数据库文件的大小不能超过 10GB……谢谢,患者至少能够以某种方式行走,其余的以某种方式治愈。
实现
矛盾的是,首先要找出我们的SQL Server的版本。问题是,当SQL Server 2016 SP1于 2018年发布时,微软展示了慷慨的奇迹,并作为其新计划的一部分在功能上部分均衡了所有版本——一致的可编程表面区域 (CPSA)。
如果之前您必须着眼于特定版本编写代码,那么随着升级到 2016 SP1(及更高版本),许多企业功能可供使用,包括Express Edition。在Express Edition的新特性中,可以挑出以下几点:支持分区表和索引、创建列存储索引和内存中表,以及压缩表的能力。这是值得安装SQL Server升级的少数情况之一。
将Express Edition用于生产工作负载是否足够?
为了回答这个问题,让我们试着考虑几个场景。
让我们测试不同类型表的单线程OLTP工作负载,用于插入/更新/删除200,000行:
USE [master]
GO
SET NOCOUNT ON
SET STATISTICS IO, TIME OFF
IF DB_ID('express') IS NOT NULL BEGIN
ALTER DATABASE [express] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [express]
END
GO
CREATE DATABASE [express]
ON PRIMARY (NAME = N'express', _
FILENAME = N'X:\express.mdf', SIZE = 200 MB, FILEGROWTH = 100 MB)
LOG ON (NAME = N'express_log', FILENAME = N'X:\express_log.ldf', _
SIZE = 200 MB, FILEGROWTH = 100 MB)
ALTER DATABASE [express] SET AUTO_CLOSE OFF
ALTER DATABASE [express] SET RECOVERY SIMPLE
ALTER DATABASE [express] SET MULTI_USER
ALTER DATABASE [express] SET DELAYED_DURABILITY = ALLOWED
ALTER DATABASE [express] ADD FILEGROUP [MEM] CONTAINS MEMORY_OPTIMIZED_DATA
ALTER DATABASE [express] ADD FILE (NAME = 'MEM', FILENAME = 'X:\MEM') TO FILEGROUP [MEM]
ALTER DATABASE [express] SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON
GO
USE [express]
GO
CREATE TABLE [T1_CL] (A INT PRIMARY KEY, B DATETIME INDEX IX1 NONCLUSTERED)
GO
CREATE TABLE [T2_MEM] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
CREATE TABLE [T3_MEM_NC] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
CREATE TABLE [T4_CL_DD] (A INT PRIMARY KEY, B DATETIME INDEX IX1 NONCLUSTERED)
GO
CREATE TABLE [T5_MEM_DD] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
CREATE TABLE [T6_MEM_NC_DD] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
CREATE TABLE [T7_MEM_SO] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY)
GO
CREATE TABLE [T8_MEM_SO_NC] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY)
GO
CREATE PROCEDURE [T3_MEM_I] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
INSERT INTO [dbo].[T3_MEM_NC] VALUES (@i, GETDATE())
END
GO
CREATE PROCEDURE [T3_MEM_U] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
UPDATE [dbo].[T3_MEM_NC] SET B = GETDATE() WHERE A = @i
END
GO
CREATE PROCEDURE [T3_MEM_D] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
DELETE [dbo].[T3_MEM_NC] WHERE A = @i
END
GO
CREATE PROCEDURE [T6_MEM_I] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
INSERT INTO [dbo].[T6_MEM_NC_DD] VALUES (@i, GETDATE())
END
GO
CREATE PROCEDURE [T6_MEM_U] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
UPDATE [dbo].[T6_MEM_NC_DD] SET B = GETDATE() WHERE A = @i
END
GO
CREATE PROCEDURE [T6_MEM_D] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
DELETE [dbo].[T6_MEM_NC_DD] WHERE A = @i
END
GO
CREATE PROCEDURE [T8_MEM_I] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
INSERT INTO [dbo].[T8_MEM_SO_NC] VALUES (@i, GETDATE())
END
GO
CREATE PROCEDURE [T8_MEM_U] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
UPDATE [dbo].[T8_MEM_SO_NC] SET B = GETDATE() WHERE A = @i
END
GO
CREATE PROCEDURE [T8_MEM_D] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
DELETE [dbo].[T8_MEM_SO_NC] WHERE A = @i
END
GO
DECLARE @i INT
, @s DATETIME
, @runs INT = 200000
DROP TABLE IF EXISTS #stats
CREATE TABLE #stats (obj VARCHAR(100), op VARCHAR(100), time_ms BIGINT)
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
INSERT INTO [T1_CL] VALUES (@i, GETDATE())
SET @i += 1
END
INSERT INTO #stats SELECT 'T1_CL', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
UPDATE [T1_CL] SET B = GETDATE() WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T1_CL', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
DELETE [T1_CL] WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T1_CL', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
INSERT INTO [T2_MEM] VALUES (@i, GETDATE())
SET @i += 1
END
INSERT INTO #stats SELECT 'T2_MEM', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
UPDATE [T2_MEM] SET B = GETDATE() WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T2_MEM', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
DELETE [T2_MEM] WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T2_MEM', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T3_MEM_I] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T3_MEM_NC', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T3_MEM_U] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T3_MEM_NC', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T3_MEM_D] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T3_MEM_NC', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
INSERT INTO [T4_CL_DD] VALUES (@i, GETDATE())
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T4_CL_DD', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
UPDATE [T4_CL_DD] SET B = GETDATE() WHERE A = @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T4_CL_DD', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
DELETE [T4_CL_DD] WHERE A = @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T4_CL_DD', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
INSERT INTO [T5_MEM_DD] VALUES (@i, GETDATE())
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T5_MEM_DD', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
UPDATE [T5_MEM_DD] SET B = GETDATE() WHERE A = @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T5_MEM_DD', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
DELETE [T5_MEM_DD] WHERE A = @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T5_MEM_DD', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
EXEC [T6_MEM_I] @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T6_MEM_NC_DD', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
EXEC [T6_MEM_U] @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T6_MEM_NC_DD', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
EXEC [T6_MEM_D] @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T6_MEM_NC_DD', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
INSERT INTO [T7_MEM_SO] VALUES (@i, GETDATE())
SET @i += 1
END
INSERT INTO #stats SELECT 'T7_MEM_SO', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
UPDATE [T7_MEM_SO] SET B = GETDATE() WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T7_MEM_SO', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
DELETE [T7_MEM_SO] WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T7_MEM_SO', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T8_MEM_I] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T8_MEM_SO_NC', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T8_MEM_U] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T8_MEM_SO_NC', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T8_MEM_D] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T8_MEM_SO_NC', 'DELETE', DATEDIFF(ms, @s, GETDATE())
GO
SELECT obj
, [I] = MAX(CASE WHEN op = 'INSERT' THEN time_ms END)
, [U] = MAX(CASE WHEN op = 'UPDATE' THEN time_ms END)
, [D] = MAX(CASE WHEN op = 'DELETE' THEN time_ms END)
FROM #stats
GROUP BY obj
USE [master]
GO
IF DB_ID('express') IS NOT NULL BEGIN
ALTER DATABASE [express] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [express]
END
作为执行的结果,我们得到以下值:
I U D
--------------- ------- ------- ------- -------------------------------------------------------
T1_CL 12173 14434 12576 B-Tree Index
T2_MEM 14774 14593 13777 In-Memory SCHEMA_AND_DATA
T3_MEM_NC 11563 10560 10097 In-Memory SCHEMA_AND_DATA + Native Compile
T4_CL_DD 5176 7294 5303 B-Tree Index + Delayed Durability
T5_MEM_DD 7460 7163 6214 In-Memory SCHEMA_AND_DATA + Delayed Durability
T6_MEM_NC_DD 8386 7494 6973 In-Memory SCHEMA_AND_DATA +
Native Compile + Delayed Durability
T7_MEM_SO 5667 5383 4473 In-Memory SCHEMA_ONLY
T8_MEM_SO_NC 3250 2430 2287 In-Memory SCHEMA_ONLY + Native Compile
对我们来说最糟糕的结果之一是基于聚集索引 ( T1_CL) 的表。如果您查看第一个表执行框架内的等待统计信息:
SELECT TOP(20) wait_type
, wait_time = CAST(wait_time_ms / 1000. AS DECIMAL(18,4))
, wait_resource = _
CAST((wait_time_ms - signal_wait_time_ms) / 1000. AS DECIMAL(18,4))
, wait_signal = CAST(signal_wait_time_ms / 1000. AS DECIMAL(18,4))
, wait_time_percent = CAST(100. * wait_time_ms / _
NULLIF(SUM(wait_time_ms) OVER (), 0) AS DECIMAL(18,2))
, waiting_tasks_count
FROM sys.dm_os_wait_stats
WHERE waiting_tasks_count > 0
AND wait_time_ms > 0
AND wait_type NOT IN (
N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR',
N'BROKER_TASK_STOP', N'BROKER_TO_FLUSH',
N'BROKER_TRANSMITTER', N'CHECKPOINT_QUEUE',
N'CHKPT', N'CLR_AUTO_EVENT',
N'CLR_MANUAL_EVENT', N'CLR_SEMAPHORE',
N'DBMIRROR_DBM_EVENT', N'DBMIRROR_EVENTS_QUEUE',
N'DBMIRROR_WORKER_QUEUE', N'DBMIRRORING_CMD',
N'DIRTY_PAGE_POLL', N'DISPATCHER_QUEUE_SEMAPHORE',
N'EXECSYNC', N'FSAGENT',
N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'FT_IFTSHC_MUTEX',
N'HADR_CLUSAPI_CALL', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION',
N'HADR_LOGCAPTURE_WAIT', N'HADR_NOTIFICATION_DEQUEUE',
N'HADR_TIMER_TASK', N'HADR_WORK_QUEUE',
N'KSOURCE_WAKEUP', N'LAZYWRITER_SLEEP',
N'LOGMGR_QUEUE', N'ONDEMAND_TASK_QUEUE',
N'PWAIT_ALL_COMPONENTS_INITIALIZED',
N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP',
N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP',
N'REQUEST_FOR_DEADLOCK_SEARCH', N'RESOURCE_QUEUE',
N'SERVER_IDLE_CHECK', N'SLEEP_BPOOL_FLUSH',
N'SLEEP_DBSTARTUP', N'SLEEP_DCOMSTARTUP',
N'SLEEP_MASTERDBREADY', N'SLEEP_MASTERMDREADY',
N'SLEEP_MASTERUPGRADED', N'SLEEP_MSDBSTARTUP',
N'SLEEP_SYSTEMTASK', N'SLEEP_TASK',
N'SLEEP_TEMPDBSTARTUP', N'SNI_HTTP_ACCEPT',
N'SP_SERVER_DIAGNOSTICS_SLEEP', N'SQLTRACE_BUFFER_FLUSH',
N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP',
N'SQLTRACE_WAIT_ENTRIES', N'WAIT_FOR_RESULTS',
N'WAITFOR', N'WAITFOR_TASKSHUTDOWN',
N'WAIT_XTP_HOST_WAIT', N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG',
N'WAIT_XTP_CKPT_CLOSE', N'XE_DISPATCHER_JOIN',
N'XE_DISPATCHER_WAIT', N'XE_TIMER_EVENT'
)
ORDER BY wait_time_ms DESC
然后我们会注意到最大的等待发生在WRITELOG:
wait_type wait_time wait_resource wait_signal wait_time_percent waiting_tasks_count
-------------------------------- ---------- -------------- ------------ ------------------ --------------------
WRITELOG 13.5480 10.7500 2.7980 95.66 600048
MEMORY_ALLOCATION_EXT 0.5030 0.5030 0.0000 3.55 608695
PREEMPTIVE_OS_WRITEFILEGATHER 0.0250 0.0250 0.0000 0.18 3
ASYNC_IO_COMPLETION 0.0200 0.0200 0.0000 0.14 1
IO_COMPLETION 0.0200 0.0200 0.0000 0.14 8
打开由Paul Randal撰写的SQL Server等待百科全书,并在查看MSDN时找到WRITELOG那里:
这是等待日志刷新到磁盘的日志管理系统。它通常表示I/O子系统跟不上日志刷新量,但在容量非常大的系统上,这也可能是由内部日志刷新限制引起的,这可能意味着您必须将工作负载分配到多个数据库上甚至让您的事务更长一点以减少日志刷新。要确定它是I/O子系统,请使用DMV sys.dm_io_virtual_file_stats 检查日志文件的I/O延迟并查看它是否与平均WRITELOG时间相关。如果WRITELOG更长,则您有内部争用,需要进行分片。如果没有,请调查为什么要创建如此多的事务日志。
我们的例子很明显,作为WRITELOG等待问题的解决方案,可以不是逐行插入数据,而是一次批量插入数据。但是我们对上面的负载优化有纯粹的学术兴趣,那么弄清楚SQL Server中数据是如何修改的是否值得?
假设我们正在进行行修改。SQL Server调用存储引擎组件,后者又调用缓冲区管理器(它与内存和磁盘中的缓冲区一起工作)并表示它想要更改数据。之后,缓冲区管理器转向缓冲池并修改内存中必要的页面(如果这些页面不存在,它将从磁盘加载它们,并且在此过程中,我们将PAGEIOLATCH_*等待)。当内存中的页面发生变化时,SQL Server还不能判断请求已经完成。否则会违反ACID(Durability)的原则之一,在修改结束时,保证所有数据都会加载到磁盘。
在内存中修改页面后,存储引擎调用日志管理器,将数据写入日志文件。但他不是立即执行此操作,而是通过大小为60Kb的日志缓冲区(有细微差别,但我们将在此处跳过它们)并用于在处理日志文件时优化性能。将数据从缓冲区刷新到日志文件的情况发生在以下情况:缓冲区已满,我们手动执行sp_flush_log,或者当事务已提交并且日志缓冲区中的所有内容都已写入日志文件时。当数据已经保存在日志文件中时,它确认数据修改成功并通知客户端。
按照这个逻辑,你会注意到数据并没有直接进入数据文件。为了优化磁盘子系统的工作,SQL Server使用异步机制将更改写入数据库文件。总共有两种这样的机制:Lazy Writer(定期运行,检查是否有足够的内存供SQL Server使用,如果观察到内存压力,则将内存中的页面抢占并写入数据库文件,以及那些有被刷新到磁盘并抛出内存)和检查点(大约每分钟扫描一次脏页,将它们放到磁盘上并留在内存中)。
当系统中发生一堆小事务时(比如说,如果数据被逐行修改),那么在每次提交之后,数据都会从日志缓冲区转到事务日志。请记住,所有更改都同步发送到日志文件,其他事务必须等待轮到它们——这是构建高性能系统的一个限制因素。
那么解决这个问题的替代方案是什么?
在SQL Server 2014中,可以创建In-Memory表,正如开发人员所声明的那样,由于新的 Hekaton引擎,它可以显着加速OLTP工作负载。但是如果你看上面的例子 ( T2_MEM),那么In-Memory的单线程性能甚至比带有聚集索引的传统表更差 ( T1_CL)——这是由于XTP_PREEMPTIVE_TASK进程在后台将In-Memory 表中的大更改提交到日志文件的大量更(实践表明,它们做得不是很好)。
实际上,In-Memory的全部意义在于改进了并发访问机制并减少了修改数据时的锁。在这种情况下,它们的使用确实会带来惊人的结果,但它们不应该用于平庸的CRUD。
我们在进一步尝试加速In-Memory表的工作时看到了类似的情况,将Native Compile存储过程 ( T3_MEM_NC)包装在它们之上,在某些计算和迭代数据处理的情况下完美地优化了性能,但作为包装器对于CRUD操作,它们表现平庸,只会减少您实际调用的工作量。
总的来说,我长期以来一直不喜欢内存表和本机编译存储——SQL Server 2014/2016中与它们相关的错误太多。有些东西已经修复,有些已经改进,但你仍然需要非常小心地使用这项技术。例如,在创建了In-Memory文件组后,您不能在不重新创建目标数据库的情况下将其删除。一切都会好起来的,但有时即使您只更新内存表中的几行,这个文件组也会增长到几 GB ……如果我们谈论的是生产,那么我不会在主数据库中使用这种技术。
一个完全不同的事情是启用Delayed Durability选项,它允许您在提交事务后不立即将数据保存到日志文件,而是等到60Kb的更改累积。这可以在所选数据库的所有事务级别强制完成:
ALTER DATABASE TT SET DELAYED_DURABILITY = FORCED
或在个别事务中:
ALTER DATABASE TT SET DELAYED_DURABILITY = ALLOWED
GO
BEGIN TRANSACTION t
...
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
使用此选项的优势在T4_CL_DD(比T1_CL快2.5倍)的示例中清楚地显示出来。当然,启用此选项也有一些缺点,在成功巧合的情况下(在系统故障或断电的情况下),您可能会丢失大约60KB的数据。
我认为你不应该在这里强加你的意见,因为在每种情况下,你都需要权衡利弊,但我会从我自己补充说,延迟持久性的加入救了我不止一次,当需要紧急在OLTP加载期间卸载磁盘子系统。
现在,我们来到了最有趣的事情——如何尽可能地加速OLTP操作?答案在于正确使用内存表。在此之前,我几乎批评过他们,但所有性能问题都只与创建的表有关SCHEMA_AND_DATA(当数据同时存储在RAM和磁盘上时)。但是,如果您使用该SCHEMA_ONLY选项创建In-Memory表,那么数据将仅存储在RAM中……作为一个减号 – 当续集重新启动时,此类表中的数据将丢失。而且,与普通表(T8_MEM_SO/ T8_MEM_SO_NC)相比,它能够将数据修改操作加快4倍。
为了说明我的工作案例,创建了一个中间数据库,其中有一个In-Memory SCHEMA_ONLY表(我们将对其的所有操作都包装在Native Compile过程中),记录以最大速度不断注入其中,我们将它们转移到更大的部分到主数据库在一个单独的流中用于永久存储。此外,In-Memory表SCHEMA_ONLY作为中间缓冲区非常适合ETL加载,因为它们不会对磁盘子系统施加任何负载。
现在让我们继续讨论DW工作负载,它的特点是分析查询和提取大量数据。
为此,让我们创建几个具有不同压缩选项的表并对其进行试验:
USE [master]
GO
SET NOCOUNT ON
SET STATISTICS IO, TIME OFF
IF DB_ID('express') IS NOT NULL BEGIN
ALTER DATABASE [express] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [express]
END
GO
CREATE DATABASE [express]
ON PRIMARY (NAME = N'express', FILENAME = N'X:\express.mdf', _
SIZE = 200 MB, FILEGROWTH = 100 MB)
LOG ON (NAME = N'express_log', FILENAME = N'X:\express_log.ldf', _
SIZE = 200 MB, FILEGROWTH = 100 MB)
ALTER DATABASE [express] SET AUTO_CLOSE OFF
ALTER DATABASE [express] SET RECOVERY SIMPLE
ALTER DATABASE [express] SET DELAYED_DURABILITY = FORCED
GO
USE [express]
GO
DROP TABLE IF EXISTS [T1_HEAP]
CREATE TABLE [T1_HEAP] (
[INT] INT NOT NULL
, [VARCHAR] VARCHAR(100) NOT NULL
, [DATETIME] DATETIME NOT NULL
)
GO
;WITH E1(N) AS (SELECT * FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) t(N))
, E2(N) AS (SELECT '1' FROM E1 a, E1 b)
, E4(N) AS (SELECT '1' FROM E2 a, E2 b)
, E8(N) AS (SELECT '1' FROM E4 a, E4 b)
INSERT INTO [T1_HEAP] WITH(TABLOCK) ([INT], [VARCHAR], [DATETIME])
SELECT TOP(5000000)
ROW_NUMBER() OVER (ORDER BY 1/0)
, CAST(ROW_NUMBER() OVER (ORDER BY 1/0) AS VARCHAR(100))
, DATEADD(DAY, ROW_NUMBER() OVER (ORDER BY 1/0) % 100, '20180101')
FROM E8
GO
DROP TABLE IF EXISTS [T2_CL]
SELECT * INTO [T2_CL] FROM [T1_HEAP] WHERE 1=0
CREATE CLUSTERED INDEX IX ON [T2_CL] ([INT]) WITH (DATA_COMPRESSION = NONE)
INSERT INTO [T2_CL] WITH(TABLOCK)
SELECT * FROM [T1_HEAP]
GO
DROP TABLE IF EXISTS [T3_CL_ROW]
SELECT * INTO [T3_CL_ROW] FROM [T2_CL] WHERE 1=0
CREATE CLUSTERED INDEX IX ON [T3_CL_ROW] ([INT]) WITH (DATA_COMPRESSION = ROW)
INSERT INTO [T3_CL_ROW] WITH(TABLOCK)
SELECT * FROM [T2_CL]
GO
DROP TABLE IF EXISTS [T4_CL_PAGE]
SELECT * INTO [T4_CL_PAGE] FROM [T2_CL] WHERE 1=0
CREATE CLUSTERED INDEX IX ON [T4_CL_PAGE] ([INT]) WITH (DATA_COMPRESSION = PAGE)
INSERT INTO [T4_CL_PAGE] WITH(TABLOCK)
SELECT * FROM [T2_CL]
GO
DROP TABLE IF EXISTS [T5_CCI]
SELECT * INTO [T5_CCI] FROM [T2_CL] WHERE 1=0
CREATE CLUSTERED COLUMNSTORE INDEX IX ON [T5_CCI] WITH (DATA_COMPRESSION = COLUMNSTORE)
INSERT INTO [T5_CCI] WITH(TABLOCK)
SELECT * FROM [T2_CL]
GO
DROP TABLE IF EXISTS [T6_CCI_ARCHIVE]
SELECT * INTO [T6_CCI_ARCHIVE] FROM [T2_CL] WHERE 1=0
CREATE CLUSTERED COLUMNSTORE INDEX IX ON [T6_CCI_ARCHIVE] _
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
INSERT INTO [T6_CCI_ARCHIVE] WITH(TABLOCK)
SELECT * FROM [T2_CL]
GO
首先要注意的是表格的最终大小:
SELECT o.[name]
, i.[rows]
, i.[type_desc]
, total_mb = CAST(i.total_pages * 8. / 1024 AS DECIMAL(18,2))
FROM sys.objects o
JOIN (
SELECT i.[object_id]
, a.[type_desc]
, total_pages = SUM(a.total_pages)
, [rows] = SUM(CASE WHEN i.index_id IN (0,1) THEN p.[rows] END)
FROM sys.indexes i
JOIN sys.partitions p ON i.[object_id] = p.[object_id] AND i.index_id = p.index_id
JOIN sys.allocation_units a ON p.[partition_id] = a.container_id
WHERE a.total_pages > 0
GROUP BY i.[object_id]
, a.[type_desc]
) i ON o.[object_id] = i.[object_id]
WHERE o.[type] = 'U'
由于可以在Express Edition上使用压缩和列存储索引,当可以在允许的10GB数据库文件内存储更多信息而不显着降低性能时,出现了一系列选项:
rows type_desc total_mb
--------------- -------- ------------ ---------
T1_HEAP 5000000 IN_ROW_DATA 153.38
T2_CL 5000000 IN_ROW_DATA 163.45
T3_CL_ROW 5000000 IN_ROW_DATA 110.13
T4_CL_PAGE 5000000 IN_ROW_DATA 72.63
T5_CCI 5000000 LOB_DATA 81.20
T6_CCI_ARCHIVE 5000000 LOB_DATA 41.13
如果我们开始谈论数据压缩,那么ROW压缩会在不损失的情况下将值截断到最低可能的固定类型PAGE——在ROW之上,另外在页面级别以二进制形式压缩数据。在这种形式中,页面同时存储在磁盘和缓冲池中,并且只有在直接访问数据的那一刻才会即时进行解压缩。
毫无疑问,使用压缩的优势体现在减少了磁盘的IO操作和更少量的缓冲池用于数据存储——如果我们有一个慢速磁盘、很少的RAM和相对卸载的处理器,则尤其如此。使用压缩的硬币的另一面是处理器上的额外负载,但并不重要到完全忽略此功能,由微软提供,“就像麻风病人一样”。
使用列存储索引看起来很有趣,它可以显着压缩数据并提高分析查询的性能。让我们快速看一下它们是如何工作的……由于这是一个列式存储模型,因此表中的数据被RowGroup分割为大约一百万行(总数可能与数据插入表的方式不同),然后,在RowGroup中,每一列都以段的形式表示,该段被压缩为具有自己的元信息的LOB对象(例如,它存储压缩序列中的最小值和最大值)。
与PAGE/ROW压缩不同,列存储索引根据目标列的数据类型使用不同的压缩选项——这可以是值规模、基于字典的压缩、位数组打包和其他各种(运行长度、霍夫曼编码、二进制压缩、LZ77)。因此,我们能够更优化地压缩每一列。
您可以通过此查询查看一个或另一个RowGroup是如何压缩的:
SELECT o.[name]
, row_group_id
, state_description
, total_rows
, size_mb = CAST(size_in_bytes / (1024. * 1024) AS DECIMAL(18,2))
, total_mb = CAST(SUM(size_in_bytes) OVER _
(PARTITION BY i.[object_id]) / 8192 * 8. / 1024 AS DECIMAL(18,2))
FROM sys.indexes i
JOIN sys.objects o ON i.[object_id] = o.[object_id]
CROSS APPLY sys.fn_column_store_row_groups(i.[object_id]) s
WHERE i.[type] IN (5, 6)
AND i.[object_id] = OBJECT_ID('T5_CCI')
ORDER BY i.[object_id]
, s.row_group_idrow_group_id state_description total_rows deleted_rows size_mb total_mb
------------- ------------------ ----------- ------------- -------- ---------
0 COMPRESSED 593581 0 3.78 31.80
1 COMPRESSED 595539 0 3.79 31.80
2 COMPRESSED 595539 0 3.79 31.80
3 COMPRESSED 599030 0 3.81 31.80
4 COMPRESSED 595539 0 3.79 31.80
5 COMPRESSED 686243 0 4.37 31.80
6 COMPRESSED 595539 0 3.79 31.80
7 COMPRESSED 738990 0 4.70 31.80让我们注意一个细微的差别,它会极大地影响使用与Express Edition相关的列存储索引的性能。由于段和字典(解压缩的基础)存储在磁盘上的不同结构中,因此我们所有字典的大小都适合内存非常重要(为此,在Express上分配的空间不超过350 MB):
SELECT [column] = COL_NAME(p.[object_id], s.column_id)
, s.dictionary_id
, s.entry_count
, size_mb = CAST(s.on_disk_size / (1024. * 1024) AS DECIMAL(18,2))
, total_mb = CAST(SUM(s.on_disk_size) OVER () / 8192 * 8. / 1024 AS DECIMAL(18,2))
FROM sys.column_store_dictionaries s
JOIN sys.partitions p ON p.hobt_id = s.hobt_id
WHERE p.[object_id] = OBJECT_ID('T5_CCI')
column dictionary_id entry_count size_mb total_mb
---------- ------------- ------------ -------- ----------
VARCHAR 1 593581 6.39 53.68
VARCHAR 2 738990 7.98 53.68
VARCHAR 3 686243 7.38 53.68
VARCHAR 4 595539 6.37 53.68
VARCHAR 5 595539 6.39 53.68
VARCHAR 6 595539 6.38 53.68
VARCHAR 7 595539 6.39 53.68
VARCHAR 8 599030 6.40 53.68
DATETIME 1 100 0.00 53.68
DATETIME 2 100 0.00 53.68
DATETIME 3 100 0.00 53.68
DATETIME 4 100 0.00 53.68
DATETIME 5 100 0.00 53.68
DATETIME 6 100 0.00 53.68
DATETIME 7 100 0.00 53.68
DATETIME 8 100 0.00 53.68
同时,可以根据需要从磁盘加载段,实际上不影响处理器负载:
SELECT [column] = COL_NAME(p.[object_id], s.column_id)
, s.segment_id
, s.row_count
, CAST(s.on_disk_size / (1024. * 1024) AS DECIMAL(18,2))
FROM sys.column_store_segments s
JOIN sys.partitions p ON p.hobt_id = s.hobt_id
WHERE p.[object_id] = OBJECT_ID('T5_CCI')
column segment_id row_count size_mb total_mb
---------- ----------- ----------- -------- ---------
INT 0 593581 2.26 31.80
INT 1 595539 2.27 31.80
INT 2 595539 2.27 31.80
INT 3 599030 2.29 31.80
INT 4 595539 2.27 31.80
INT 5 686243 2.62 31.80
INT 6 595539 2.27 31.80
INT 7 738990 2.82 31.80
VARCHAR 0 593581 1.51 31.80
VARCHAR 1 595539 1.52 31.80
VARCHAR 2 595539 1.52 31.80
VARCHAR 3 599030 1.52 31.80
VARCHAR 4 595539 1.52 31.80
VARCHAR 5 686243 1.75 31.80
VARCHAR 6 595539 1.52 31.80
VARCHAR 7 738990 1.88 31.80
DATETIME 0 593581 0.01 31.80
DATETIME 1 595539 0.01 31.80
DATETIME 2 595539 0.01 31.80
DATETIME 3 599030 0.01 31.80
DATETIME 4 595539 0.01 31.80
DATETIME 5 686243 0.01 31.80
DATETIME 6 595539 0.01 31.80
DATETIME 7 738990 0.01 31.80
注意RowGroup段内唯一记录越少,字典大小越小。将列存储分区并将数据与TABLOCK提示一起插入所需的部分将导致更小的本地字典,这意味着它将减少使用列存储索引的开销。实际上,优化字典最简单的方法是在数据本身——列中的唯一数据越少越好(这可以在DATETIME示例中看到)。
由于柱状模型,只会减去我们请求的那些列,由于上述元信息,额外的过滤器可以限制RowGroup的减去。结果,我们得到了一种伪索引的类似物,它同时在所有列上,这使我们能够非常快速地聚合和过滤......再次具有自己的细微差别。
让我们看几个例子来展示列存储索引的好处:
DBCC DROPCLEANBUFFERS
SET STATISTICS IO, TIME ON
SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T1_HEAP]
SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T2_CL]
SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T3_CL_ROW]
SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T4_CL_PAGE]
SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T5_CCI]
SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T6_CCI_ARCHIVE]
SET STATISTICS IO, TIME OFF
俗话说,感受不同:
Table 'T1_HEAP'. Scan count 1, logical reads 19633, ...
CPU time = 391 ms, elapsed time = 400 ms.
Table 'T2_CL'. Scan count 1, logical reads 20911, ...
CPU time = 312 ms, elapsed time = 391 ms.
Table 'T3_CL_ROW'. Scan count 1, logical reads 14093, ...
CPU time = 485 ms, elapsed time = 580 ms.
Table 'T4_CL_PAGE'. Scan count 1, logical reads 9286, ...
CPU time = 828 ms, elapsed time = 1000 ms.
Table 'T5_CCI'. Scan count 1, ..., lob logical reads 5122, ...
CPU time = 8 ms, elapsed time = 14 ms.
Table 'T6_CCI_ARCHIVE'. Scan count 1, ..., lob logical reads 2576, ...
CPU time = 78 ms, elapsed time = 74 ms.
过滤时,可能会出现不太好的细微差别:
DBCC DROPCLEANBUFFERS
SET STATISTICS IO, TIME ON
SELECT * FROM [T5_CCI] WHERE [INT] = 1
SELECT * FROM [T5_CCI] WHERE [DATETIME] = GETDATE()
SELECT * FROM [T5_CCI] WHERE [VARCHAR] = '1'
SET STATISTICS IO, TIME OFF
问题是对于某些数据类型 ( NUMERIC, DATETIMEOFFSET, [N] CHAR, [N] VARCHAR, VARBINARY, UNIQUEIDENTIFIER, XML)不支持行组消除:
Table 'T5_CCI'. Scan count 1, ..., lob logical reads 2713, ...
Table 'T5_CCI'. Segment reads 1, segment skipped 7.
CPU time = 15 ms, elapsed time = 9 ms.
Table 'T5_CCI'. Scan count 1, ..., lob logical reads 0, ...
Table 'T5_CCI'. Segment reads 0, segment skipped 8.
CPU time = 0 ms, elapsed time = 0 ms.
Table 'T5_CCI'. Scan count 1, ..., lob logical reads 22724, ...
Table 'T5_CCI'. Segment reads 8, segment skipped 0.
CPU time = 547 ms, elapsed time = 669 ms.
在某些情况下,优化器存在明显的缺陷,这与SQL Server 2008R2中的旧错误非常相似(当预聚合比以更紧凑的方式编写的聚合更快时):
DBCC DROPCLEANBUFFERS
SET STATISTICS IO, TIME ON
SELECT EOMONTH([DATETIME]), Cnt = SUM(Cnt)
FROM (
SELECT [DATETIME], Cnt = COUNT(*)
FROM [T5_CCI]
GROUP BY [DATETIME]
) t
GROUP BY EOMONTH([DATETIME])
SELECT EOMONTH([DATETIME]), Cnt = COUNT(*)
FROM [T5_CCI]
GROUP BY EOMONTH([DATETIME])
SET STATISTICS IO, TIME OFF
老实说,这样的时刻很多:
Table 'T5_CCI'. Scan count 1, ..., lob logical reads 64, ...
CPU time = 0 ms, elapsed time = 2 ms.
Table 'T5_CCI'. Scan count 1, ..., lob logical reads 32, ...
CPU time = 344 ms, elapsed time = 380 ms.
在本文的框架内不可能将所有这些都考虑在内,但是此博客中完美地提供了许多您需要了解的内容。我强烈推荐此资源以更深入地了解列存储索引的主题!
如果功能或多或少清晰,我希望我能够通过上面的示例说服他们,它们通常不是Express Edition全面开发的限制因素。但是资源限制呢……我想说每个具体案例都是单独决定的。
Express Edition只允许每个实例使用4个内核,但是是什么阻止了我们在服务器中部署多个实例(例如,在其中16个内核上),让每个实例修复其物理内核并获得可扩展的廉价模拟系统,尤其是在微服务器架构的情况下——当每个服务都使用自己的数据库副本时。
缺少1GB缓冲池?也许通过优化查询和引入分区、列存储索引或老式压缩表中的数据来最小化物理读取是值得的。如果这是不可能的,则迁移到更快的RAID。
但是数据库文件的最大大小怎么办,不能超过10GB,当我们尝试将其增加到超过指定值时,我们预计会得到一个错误:
CREATE DATABASE或ALTER DATABASE失败,因为产生的累积数据库大小将超过每个数据库10240 MB的许可限制。
有多种方法可以解决此问题。
我们可以创建多个数据库来包含我们自己的历史数据部分。对于这些表中的每一个,我们将设置一个约束,然后将所有这些表合并到一个视图中。这将为我们提供单个实例中的水平分片。
USE [master]
GO
SET NOCOUNT ON
SET STATISTICS IO, TIME OFF
IF DB_ID('DB_2019') IS NOT NULL BEGIN
ALTER DATABASE [DB_2019] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [DB_2019]
END
GO
IF DB_ID('DB_2020') IS NOT NULL BEGIN
ALTER DATABASE [DB_2020] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [DB_2020]
END
GO
IF DB_ID('DB_2021') IS NOT NULL BEGIN
ALTER DATABASE [DB_2021] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [DB_2021]
END
GO
IF DB_ID('DB') IS NOT NULL BEGIN
ALTER DATABASE [DB] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [DB]
END
GO
CREATE DATABASE [DB_2019]
ALTER DATABASE [DB_2019] SET AUTO_CLOSE OFF, RECOVERY SIMPLE
CREATE DATABASE [DB_2020]
ALTER DATABASE [DB_2020] SET AUTO_CLOSE OFF, RECOVERY SIMPLE
CREATE DATABASE [DB_2021]
ALTER DATABASE [DB_2021] SET AUTO_CLOSE OFF, RECOVERY SIMPLE
CREATE DATABASE [DB]
ALTER DATABASE [DB] SET AUTO_CLOSE OFF, RECOVERY SIMPLE
GO
USE [DB_2019]
GO
CREATE TABLE [T_2019] ([A] DATETIME, [B] INT, PRIMARY KEY ([A], [B]))
ALTER TABLE [T_2019] WITH CHECK ADD CONSTRAINT [T_CK]
CHECK ([A] >= '20190101' AND [A] < '20200101')
GO
INSERT INTO [T_2019] VALUES ('20190101', 1), ('20190201', 2), ('20190301', 3)
GO
USE [DB_2020]
GO
CREATE TABLE [T_2020] ([A] DATETIME, [B] INT, PRIMARY KEY ([A], [B]))
ALTER TABLE [T_2020] WITH CHECK ADD CONSTRAINT [T_CK]
CHECK ([A] >= '20200101' AND [A] < '20210101')
GO
INSERT INTO [T_2020] VALUES ('20200401', 4), ('20200501', 5), ('20200601', 6)
GO
USE [DB_2021]
GO
CREATE TABLE [T_2021] ([A] DATETIME, [B] INT, PRIMARY KEY ([A], [B]))
ALTER TABLE [T_2021] WITH CHECK ADD CONSTRAINT [T_CK]
CHECK ([A] >= '20210101' AND [A] < '20220101')
GO
INSERT INTO [T_2021] VALUES ('20210701', 7), ('20210801', 8), ('20210901', 9)
GO
USE [DB]
GO
CREATE SYNONYM [dbo].[T_2019] FOR [DB_2019].[dbo].[T_2019]
CREATE SYNONYM [dbo].[T_2020] FOR [DB_2020].[dbo].[T_2020]
CREATE SYNONYM [dbo].[T_2021] FOR [DB_2021].[dbo].[T_2021]
GO
CREATE VIEW [T]
AS
SELECT * FROM [dbo].[T_2019]
UNION ALL
SELECT * FROM [dbo].[T_2020]
UNION ALL
SELECT * FROM [dbo].[T_2021]
GO
在设置了限制的列中过滤时,我们将只读取我们需要的数据:
SELECT COUNT(*) FROM [T] WHERE [A] > '20200101'
在执行计划或统计中可以看到什么:
Table 'T_2021'. Scan count 1, logical reads 2, ...
Table 'T_2020'. Scan count 1, logical reads 2, ...
另外,由于限制,我们可以透明地修改视图内的数据:
INSERT INTO [T] VALUES ('20210101', 999)
UPDATE [T] SET [B] = 1 WHERE [A] = '20210101'
DELETE FROM [T] WHERE [A] = '20210101'
Table 'T_2021'. Scan count 0, logical reads 2, ...
Table 'T_2021'. Scan count 1, logical reads 6, ...
Table 'T_2020'. Scan count 0, logical reads 0, ...
Table 'T_2019'. Scan count 0, logical reads 0, ...
Table 'T_2021'. Scan count 1, logical reads 2, ...
Table 'T_2020'. Scan count 0, logical reads 0, ...
Table 'T_2019'. Scan count 0, logical reads 0, ...
应用这种方法,我们可以部分解决问题,但是,每个单独的数据库仍然会被限制在珍惜的 10GB内。
另一种选择是专门为架构变态爱好者发明的——由于数据文件大小的限制不适用于系统数据库(master、msdb、model和tempdb),因此所有开发都可以在它们中完成。但通常情况下,这种使用系统数据库作为用户数据库的做法是火箭发射器的一小步。因此,我甚至不会描绘这样一个决定的所有陷阱,但如果你仍然真的想要它,这绝对能保证你快速地把淫秽词汇提升到一个有30年经验的工头的水平。
现在让我们继续讨论该问题的有效解决方案。
我们在Developer Edition上创建一个我们需要的大小的数据库并进行分离:
USE [master]
GO
IF DB_ID('express') IS NOT NULL BEGIN
ALTER DATABASE [express] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [express]
END
GO
CREATE DATABASE [express]
GO
ALTER DATABASE [express] MODIFY FILE (NAME = N'express', SIZE = 20 GB)
ALTER DATABASE [express] MODIFY FILE (NAME = N'express_log', SIZE = 100 MB)
ALTER DATABASE [express] SET DISABLE_BROKER
GO
EXEC [master].dbo.sp_detach_db @dbname = N'express'
GO
在Express Edition上创建一个同名的数据库,然后停止服务:
USE [master]
GO
IF DB_ID('express') IS NOT NULL BEGIN
ALTER DATABASE [express] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [express]
END
GO
CREATE DATABASE [express]
GO
ALTER DATABASE [express] MODIFY FILE (NAME = N'express', SIZE = 100 MB)
ALTER DATABASE [express] MODIFY FILE (NAME = N'express_log', SIZE = 100 MB)
ALTER DATABASE [express] SET DISABLE_BROKER
GO
我们将数据库的文件从Developer Edition移到Express Edition上相同数据库所在的位置,将一些文件替换为其他文件。启动SQL Server Express Edition的实例。
检查我们的数据库的大小:
SET NOCOUNT ON
SET ARITHABORT ON
SET NUMERIC_ROUNDABORT OFF
SET STATISTICS IO, TIME OFF
IF OBJECT_ID('tempdb.dbo.#database_files') IS NOT NULL
DROP TABLE #database_files
CREATE TABLE #database_files (
[db_id] INT DEFAULT DB_ID()
, [name] SYSNAME
, [type] INT
, [size_mb] BIGINT
, [used_size_mb] BIGINT
)
DECLARE @sql NVARCHAR(MAX) = STUFF((
SELECT '
USE ' + QUOTENAME([name]) + '
INSERT INTO #database_files ([name], [type], [size_mb], [used_size_mb])
SELECT [name]
, [type]
, CAST([size] AS BIGINT) * 8 / 1024
, CAST(FILEPROPERTY([name], ''SpaceUsed'') AS BIGINT) * 8 / 1024
FROM sys.database_files WITH(NOLOCK);'
FROM sys.databases WITH(NOLOCK)
WHERE [state] = 0
AND ISNULL(HAS_DBACCESS([name]), 0) = 1
FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')
EXEC sys.sp_executesql @sql
SELECT [db_id] = d.[database_id]
, [db_name] = d.[name]
, [state] = d.[state_desc]
, [total_mb] = s.[data_size] + s.[log_size]
, [data_mb] = s.[data_size]
, [data_used_mb] = s.[data_used_size]
, [data_free_mb] = s.[data_size] - s.[data_used_size]
, [log_mb] = s.[log_size]
, [log_used_mb] = s.[log_used_size]
, [log_free_mb] = s.[log_size] - s.[log_used_size]
FROM sys.databases d WITH(NOLOCK)
LEFT JOIN (
SELECT [db_id]
, [data_size] = SUM(CASE WHEN [type] = 0 THEN [size_mb] END)
, [data_used_size] = SUM(CASE WHEN [type] = 0 THEN [used_size_mb] END)
, [log_size] = SUM(CASE WHEN [type] = 1 THEN [size_mb] END)
, [log_used_size] = SUM(CASE WHEN [type] = 1 THEN [used_size_mb] END)
FROM #database_files
GROUP BY [db_id]
) s ON d.[database_id] = s.[db_id]
ORDER BY [total_mb] DESC
瞧!现在数据库文件大小超过限制,数据库功能齐全:
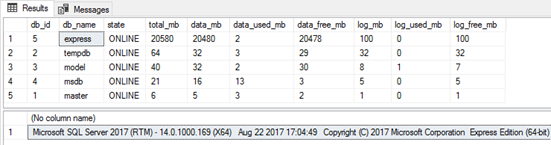
您可以像以前一样缩小它、创建备份或更改此数据库的设置。只有在需要从备份中恢复数据库或再次增加数据库文件的大小时才会出现困难。在这种情况下,我们可以将备份恢复到Developer Edition,将大小增加到所需的大小,然后如上所述替换文件。
结论
因此,SQL Server Express Edition经常以资源限制和其他一大堆借口为幌子,不合时宜地被绕过。文章的主要信息是您可以在任何版本的SQL Server上设计高性能系统。
谢谢大家的关注!
https://www.codeproject.com/Articles/5297076/SQL-Server-Express-Edition-on-Steroids















 721
721











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









