








目录

自从我在英特尔开始我的旅程以来已经有几个月了,我很高兴与大家分享我一直在做的事情。今天,我将带您了解我的第一个关于人类行为识别的notebook。我希望您喜欢它,并可以在您正在进行的开发中应用它。
在本博客中,您将学习如何在同步的时间表中使用OpenVINO™ AI工具包进行实时人体动作识别。
人类动作识别是一种人工智能功能,可以在录制或实时视频中查找和分类一组广泛的活动。例如,如果你有一个大型家庭视频收藏,并且你想找到一个特定的记忆,那么人类动作识别是最简单、最快的方法。传统方法需要您花费大量的手动精力和时间来查看您拥有的每个视频,直到找到合适的视频。使用人类动作识别,您可以训练AI模型根据为您录制的活动自动分类和组织您的视频,从而在几秒钟内更轻松地找到和访问您最珍贵的回忆。
此操作也可以应用于制造业等业务。例如,为人类工人提供解决方案,这些解决方案可以识别他们执行的任务,做出反馈手势,并通过识别和提醒管理人员任何危险来确保他们的安全。
但这些只是人类行为识别可以做什么的几个例子。在接下来的几年里,我希望在这个领域看到更多新的和令人兴奋的用例。让我知道在运行此notebook后,您认为还可以从此AI功能中受益的其他领域。但现在,让我们开始吧。
关于此notebook
对于此notebook,我使用的是 DeepMind Kinetics-400人类动作视频数据集,该数据集总共包含400个动作,包括人物动作(例如,写作、喝酒、大笑)、人与人之间的动作(例如,拥抱、握手、玩扑克)和人-对象动作(骑滑板车、洗衣服、吹气球)。您还可以区分一组亲子互动,例如编辫子或梳头、萨尔萨舞或机器人舞,以及拉小提琴或吉他(图1)。有关标签和数据集的更多信息,请参阅“动力学人类行动视频数据集”研究论文。
图1.使用OpenVINO™工具包进行人体行为识别
您可以使用通用计算机运行此notebook,不需要硬件加速器。使用AI工具包OpenVINO的好处在于,它旨在在边缘工作,因此可以针对GPU、CPU和VPU进行优化,以有效地运行您的AI推理模型。但同样,这些都不是必需的。可以使用各种视频源,例如来自URL、本地存储的文件或网络摄像头源的剪辑。
我还将使用Open Model Zoo的动作识别模型,该模型提供了各种预先训练的深度学习模型和演示应用程序。我使用的模型基于视频转换器,具有ResNet34架构(图2)。它包含两个模型:
- 编码器,基于PyTorch框架,输入形状为[1x3x224x224] — 1个批量大小、3个颜色通道和224 x 224像素的图像尺寸;和输出形状[1x512x1x1],表示已处理帧的嵌入。
- Decoder,也基于PyTorch框架,输入形状为[1x16x512] — 1个批量大小,16帧用于一秒内剪辑的持续时间,以及512个嵌入维度。
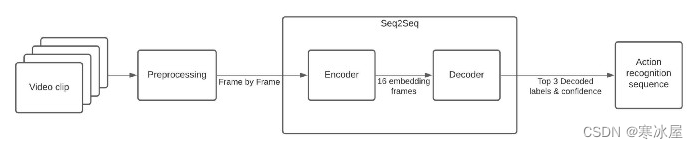
图2.人类动作识别notebook的管道。
我选择每秒16帧进行分析——这是 Kinetics-400作者为找到班级分数而平均的帧数。这些帧经过预处理,仅分析居中裁剪的图像,如图1中的GIF所示。
这两个模型都创建了一个序列到序列(Seq2Seq)系统,用于识别Kinetics-400数据集的人类活动。由于注释不详尽,模型性能是最好的,但它可以帮助我们理解管道。
您可以通过以下方式开始识别自己的视频:
- 使用 OpenVINO notebook准备安装。
- 准备视频源、网络摄像头或视频文件,其中包含要检测的常见活动。通过检查数据集标签来考虑要检测的操作名称。
- 在计算机上打开Jupyter notebook。该notebook可以在Windows,MacOS和Ubuntu下运行,在不同的互联网浏览器上。
使用OpenVINO™进行真人识别
现在,我将向您展示notebook的一些亮点:
1. 下载模型
我们正在使用开放模型Zoo工具,例如omz_downloader。它是一个命令行工具,可自动创建目录结构并下载所选模型。在这种情况下,它是来自Open Model Zoo的“动作识别-0001”模型。
if not os.path.exists(model_path_decoder) or not os.path.exists(model_path_encoder):
download_command = f"omz_downloader " \
f"--name {model_name} " \
f"--precision {precision} " \
f"--output_dir {base_model_dir}"
! $download_command2. 模型初始化
要开始推理,请初始化推理引擎,从文件中读取网络和权重,在所选设备(在本例中为CPU)上加载模型,然后获取输入和输出节点。
# Initialize inference engine
ie_core = Core()
def model_init(model_path: str) -> Tuple:
"""
Read the network and weights from file, load the
model on the CPU and get input and output names of nodes
:param: model: model architecture path *.xml
:returns:
compiled_model: Compiled model
input_key: Input node for model
output_key: Output node for model
"""
# Read the network and corresponding weights from file
model = ie_core.read_model(model=model_path)
# compile the model for the CPU (you can use GPU or MYRIAD as well)
compiled_model = ie_core.compile_model(model=model, device_name="CPU")
#Get input and output names of nodes
input_keys = compiled_model.input(0)
output_keys = compiled_model.output(0)
return input_keys, output_keys, compiled_model3. 辅助函数
您需要大量代码来准备和可视化结果。创建以裁剪为中心的ROI,调整图像大小,并将文本信息放在每个帧中。
4.AI函数
这就是奇迹发生的地方。
A、在运行编码器之前预处理帧(预处理)
- 在将帧通过编码器之前,请准备图像—通过裁剪、居中和平方使其宽度和高度相等,将其缩放到最短尺寸,缩放到所选大小。帧必须从高度——宽度——通道(HWC)转置为通道高度——宽度(CHW)。
def preprocessing(frame: np.ndarray, size: int) -> np.ndarray:
"""
Preparing frame before Encoder.
The image should be scaled to its shortest dimension at "size"
and cropped, centered, and squared so that both width and
height have lengths "size". Frame must be transposed from
Height-Width-Channels (HWCs) to Channels-Height-Width (CHW).
:param frame: input frame
:param size: input size to encoder model
:returns: resized and cropped frame
"""
# Adapative resize
preprocessed = adaptive_resize(frame, size)
# Center_crop
(preprocessed, roi) = center_crop(preprocessed)
# Transpose frame HWC -> CHW
preprocessed = preprocessed.transpose((2, 0, 1))[None,] # HWC -> CHW
return preprocessed, roiB、每帧编码器推理(编码器)
- 此函数调用先前为编码器模型(compiled_model)配置的网络,从输出节点中提取数据,并将其追加到要由解码器使用的数组中。
def encoder(
preprocessed: np.ndarray,
compiled_model: CompiledModel
) -> List:
"""
Encoder Inference per frame. This function calls the network previously
configured for the encoder model (compiled_model), extracts the data
from the output node, and appends it in an array to be used by the decoder.
:param: preprocessed: preprocessing frame
:param: compiled_model: Encoder model network
:returns: encoder_output: embedding layer that is appended with each arriving frame
"""
output_key_en = compiled_model.output(0)
# Get results on action-recognition-0001-encoder model
infer_result_encoder = compiled_model([preprocessed])[output_key_en]
return infer_result_encoderC、每组帧的解码器推理(解码器)
- 此函数从编码器输出连接嵌入层,并转置数组以匹配解码器输入大小。它调用先前为解码器模型配置的网络(compiled_model_de),提取logits(是的,logits是真实的东西;你可以在这里找到更多信息)并规范化它们以获得沿指定轴的置信度值。它将最高概率解码为相应的标签名称。
def decoder(encoder_output: List, compiled_model_de: CompiledModel) -> List:
"""
Decoder inference per set of frames. This function concatenates the embedding layer
forms the encorder output, transpose the array to match with the decoder input size.
Calls the network previously configured for the decoder model (compiled_model_de), extracts
the logits and normalize those to get confidence values along specified axis.
Decodes top probabilities into corresponding label names
:param: encoder_output: embedding layer for 16 frames
:param: compiled_model_de: Decoder model network
:returns: decoded_labels: The k most probable actions from the labels list
decoded_top_probs: confidence for the k most probable actions
"""
# Concatenate sample_duration frames in just one array
decoder_input = np.concatenate(encoder_output, axis=0)
# Organize input shape vector to the Decoder (shape: [1x16x512]]
decoder_input = decoder_input.transpose((2, 0, 1, 3))
decoder_input = np.squeeze(decoder_input, axis=3)
output_key_de = compiled_model_de.output(0)
# Get results on action-recognition-0001-decoder model
result_de = compiled_model_de([decoder_input])[output_key_de]
# Normalize logits to get confidence values along specified axis
probs = softmax(results_de - np.max(result_de))
# Decodes top probabilities into corresponding label names
decoded_labels, decoded_top_probs = decode_output(probs, labels, top_k=3)
return decoded_labels, decoded_top_probs运行完整的notebook管道
现在,让我们看看notebook的实际应用。
1、选择要为其运行完整工作流程的视频。
video_file = "https://archive.org/serve/ISSVideoResourceLifeOnStation720p/ISS%20Video%20Resource_LifeOnStation_720p.mp4"
run_action_recognition(source=video_file, flip=False, use_popup=False, skip_first_frames=600)2、选择网络摄像头并再次运行完整的工作流程。
run_action_recognition(source=0, flip=False, use_popup=False, skip_first_frames=0)恭喜!你已经做到了。我希望您发现这个主题对您的应用程序开发有趣且有用。😉
要了解有关OpenVINO工具包及其功能的更多信息,请访问 Intel® Distribution of OpenVINO™ Toolkit。有关更多AI实践培训,请查看我们的 AI开发团队冒险。
资源
本文最初发表于 https://medium.com/openvino-toolkit/human-action-recognition-with-openvino-toolkit-f1b530af33e5















 583
583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}