









目录
1、使用 Betalgo.OpenAI.Tokenizer.GPT3 计算
2、使用 Microsoft.ML.Tokenizers 计算
前面我们实现了与ChatGPT聊天对话,但不知你发现没有,每次对话时,它都无法记住之前的内容,没有任何连贯性。怎么办呢?别着急,今天我们就来实现让ChatGPT拥有对话记忆功能,让聊天变得流畅丝滑,还请大家点个小关。👇
我们想让ChatGPT具备对话记忆功能,那么我们就需要先了解chat/completions API。在这个API中,有一个很关键的参数messages:
//chat/completions文档地址
https://platform.openai.com/docs/api-reference/chat/create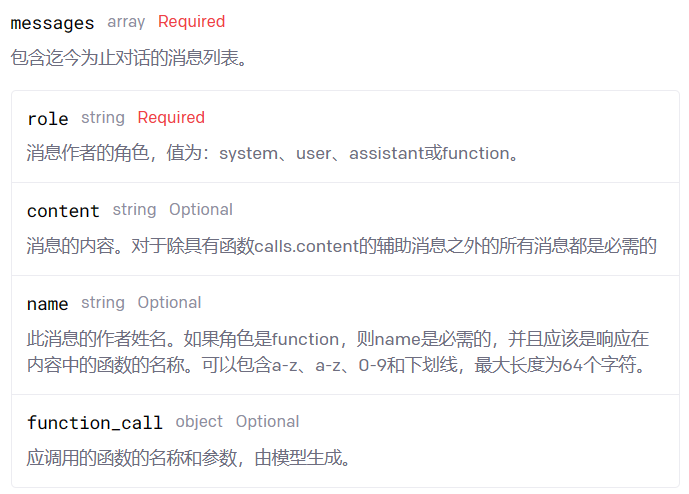
messages是一个数组对象,它存储了与ChatGPT进行对话的所有消息。每一次发送新的消息给ChatGPT时,我们只需附上之前的对话内容,ChatGPT就能根据聊天的上下文生成合适的回复。
messages中有一个重要的属性role,它表示消息的发送者或接收者的角色。role属性是必需的,因为它影响了模型如何理解和生成消息。通过设置不同的role值,我们才可以创建多轮的对话场景,或者单轮的任务场景。目前role属性有三个可选的值:
-
system:表示系统消息,用于设置助手的行为或个性;
-
user:表示用户消息,用于提供请求或评论给助手;
-
assistant:表示助手消息,用于存储或展示助手的回复。
接下来,我们用代码来实现这个功能。我们新建一个名为ChatGPT.Demo3的项目,沿用上一章ChatGPT.Demo2的配置和依赖。
ChatGPT上下文对话
1、 服务端接口调整
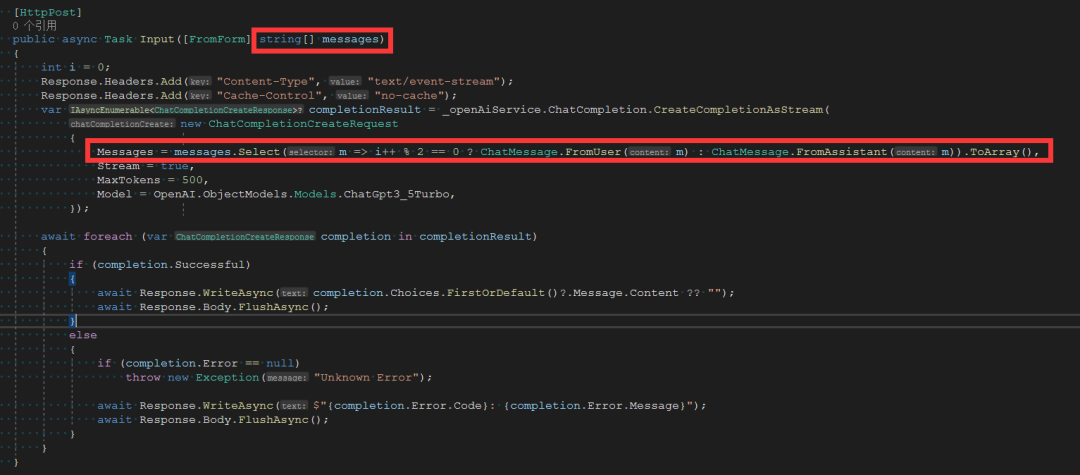
打开Controllers/ChatController.cs文件,将原来的Input方法替换为以下内容:
[HttpPost]
public async Task Input([FromForm] string[] messages)
{
int i = 0;
Response.Headers.Add("Content-Type", "text/event-stream");
Response.Headers.Add("Cache-Control", "no-cache");
var completionResult = _openAiService.ChatCompletion.CreateCompletionAsStream(
new ChatCompletionCreateRequest
{
Messages = messages.Select(m => i++ % 2 == 0 ? ChatMessage.FromUser(m) : ChatMessage.FromAssistant(m)).ToArray(),
Stream = true,
MaxTokens = 500,
Model = OpenAI.ObjectModels.Models.ChatGpt3_5Turbo,
});
await foreach (var completion in completionResult)
{
if (completion.Successful)
{
await Response.WriteAsync(completion.Choices.FirstOrDefault()?.Message.Content ?? "");
await Response.Body.FlushAsync();
}
else
{
if (completion.Error == null)
throw new Exception("Unknown Error");
await Response.WriteAsync($"{completion.Error.Code}: {completion.Error.Message}");
await Response.Body.FlushAsync();
}
}
}为了接收客户端提交的上下文消息列表,我们将input方法的输入参数类型从string message修改为string[] messages,并对其进行处理,将string[] messages转换为IList<ChatMessage> Messages。在这里,我们用索引来区分消息发送者的角色:偶数索引表示user角色,奇数索引表示assistant角色,如下图所示:
2、Web端调整
打开Views/Home/Index.cshtml文件,在消息输入框下方增加开启上下文对话选择框标签:
<div class="form-check mt-3">
<input class="form-check-input" type="checkbox" id="enableContext">
<label class="form-check-label" for="enableContext">
开启上下文对话
</label>
</div>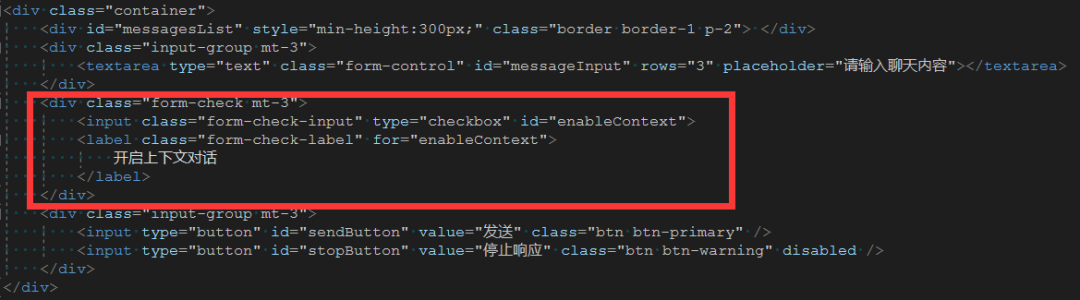
在js脚本中增加上下文对话按钮代码:
//是否开启上下文
var enableContext = document.getElementById("enableContext");
//存放上下文聊天信息
var messageContext = []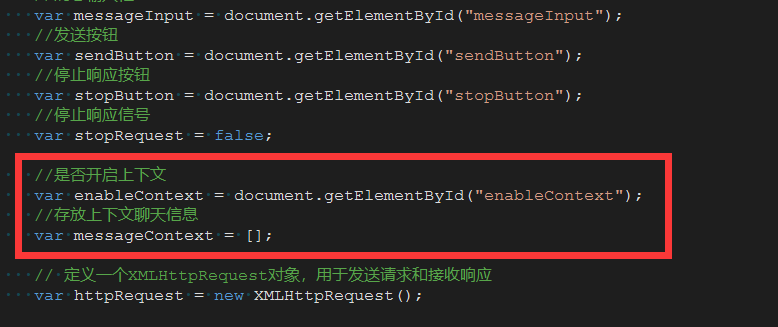
我们把所有的对话内容缓存在messageContext中,便于提取。然后把send方法里的FormData的赋值方式稍作修改:
//创建FormData格式消息
var formData = new FormData();
//是否携带上下文内容
if (enableContext.checked) {
for (let i = 0; i < messageContext.length; i++) {
formData.append('messages', messageContext[i]);
}
}
formData.append('messages', message);在 httpRequest.onloadend方法中将新产生的对话内容加入messageContext:
//保存最新消息到上下文
messageContext.push(message);
messageContext.push(progressEvent.target.responseText);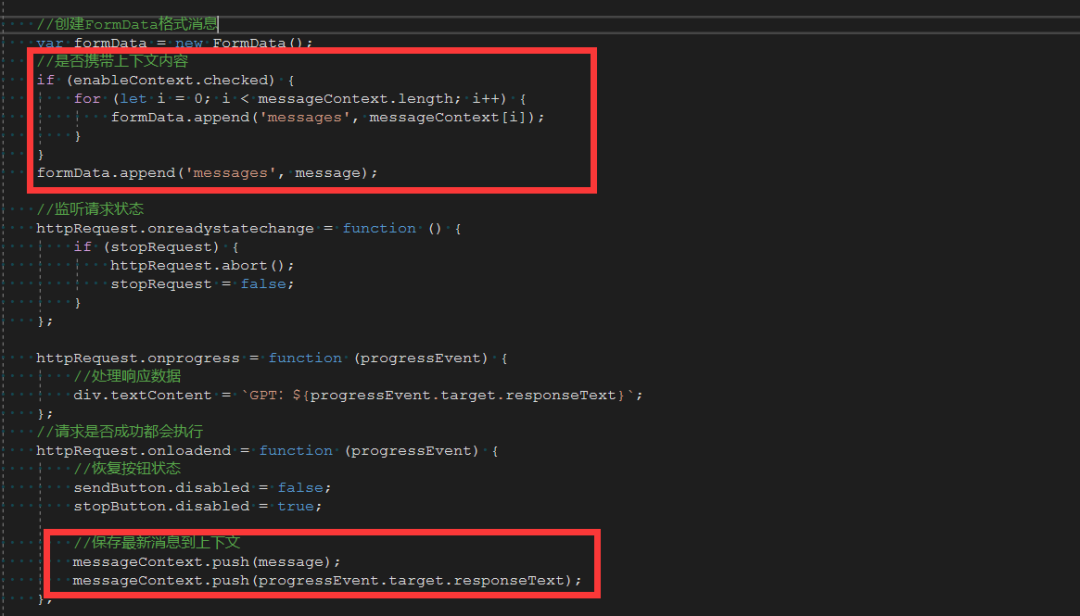
这样一来,当我们启动上下文对话功能时,所有的对话内容将会提交给ChatGPT,它就能够把对话关联起来。按F5启动看一下效果:
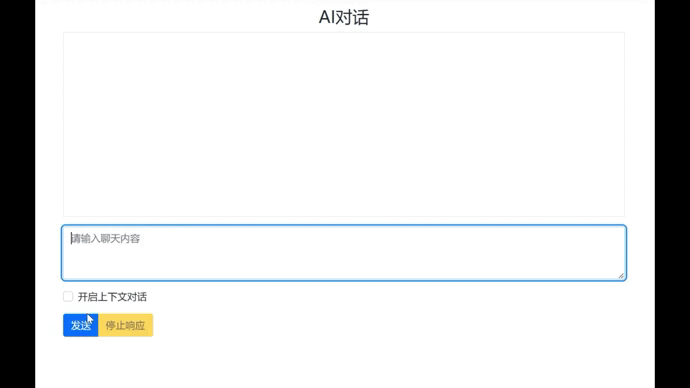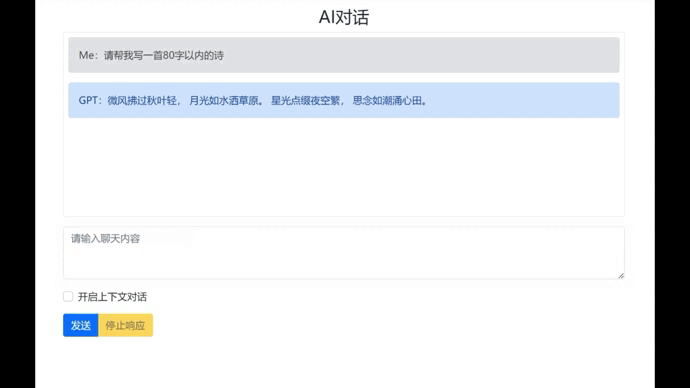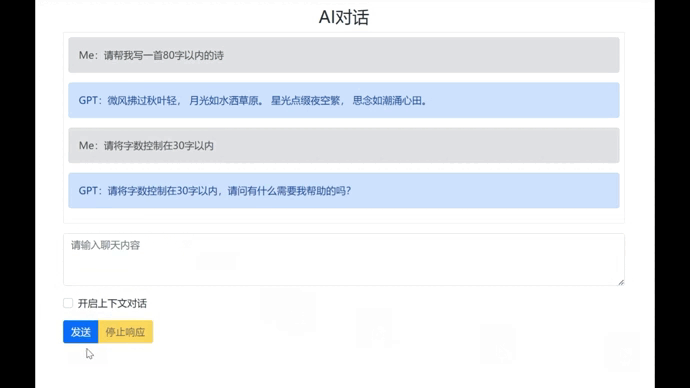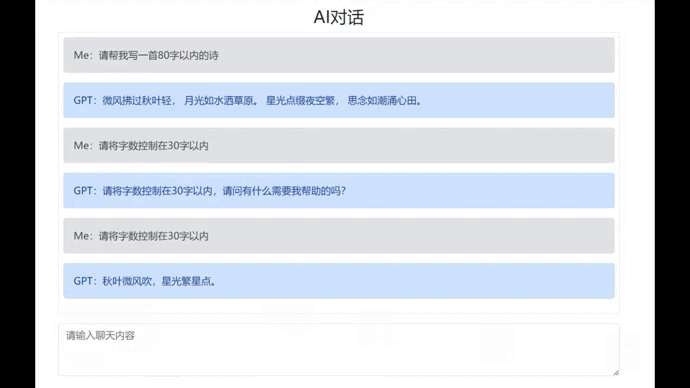
ChatGPT的Token计算
ChatGPT 是一种基于Token数量来计费的语言模型,它会把我们输入的文本分割成不同的Token,每1000个Token大约需要 0.002 美元,约750个词。通常,常用的多音节词会被视为一个Token,而不常用的词则会按音节拆分。
每个模型都有一个最大的Token数量限制,当我们向ChatGPT发送一段文本时,需要消耗的token数量等于我们输入的文本Token数量加上ChatGPT输出的文本Token数量。
例如,如果你发送了一个100 Token的文本,ChatGPT根据你的文本生成了一个200 Token的回复,那么你一共消耗了300 Token。
问题来了,如果我们想要知道一段长文本发送给它时会消耗多少 Token,该怎么计算呢?
在ChatGPT的回复信息中,非流式访问会显示消耗的Token数量,也就是ChatGPT.Demo1中使用的方式,而流式访问则不会。所以,我们需要自己计算流式访问的Token数量。为了做到这一点,我们今天使用两种方式来计算。
1、使用 Betalgo.OpenAI.Tokenizer.GPT3 计算
using OpenAI.Tokenizer.GPT3;
// 定义输入字符串
var input = "the brown fox jumped over the lazy dog!";
//从字符串中获取估计的令牌使用情况
var tokenCount = TokenizerGpt3.TokenCount(input, true);引入命名空间,使用TokenizerGpt3的TokenCount方法就可以计算出Token的数量,TokenCount方法中提供了一个布尔类型的参数cleanUpCREOL,为true表示清理行尾字符,使Token计算结果更加准确。
//OpenAI.Tokenizer.GPT3文档
https://github.com/betalgo/openai/wiki/Tokenizer2、使用 Microsoft.ML.Tokenizers 计算
安装Microsoft.ML.Tokenizers包
Install-Package Microsoft.ML.Tokenizers下载词汇表文件和合并规则文件,然后添加到项目的根目录
//词汇表文件和合并规则文件下载地址
https://huggingface.co/gpt2/tree/mainToken计算代码如下:
using Microsoft.ML.Tokenizers;
// 定义词汇表文件和合并规则文件的路径
var vocabFilePath = @"vocab.json";
var mergeFilePath = @"merges.txt";
// 创建分词器对象,传入BPE算法的参数
var tokenizer = new Tokenizer(new Bpe(vocabFilePath, mergeFilePath));
// 定义输入字符串
var input = "the brown fox jumped over the lazy dog!";
// 对输入字符串进行编码,得到编码结果对象
var tokenizerEncodedResult = tokenizer.Encode(input);
// 获取单词数量,并返回该值
var tokenCount = tokenizerEncodedResult.Tokens.Count;将输入的字符串使用BPE算法,并指定词汇表和合并规则进行编码,拿到分割后的token数据,从而计算出Token数量。我们还可以计算出拆分后的Token值,两个类库都提供了计算的方法,可以直接使用。
//Microsoft.ML.Tokenizers示例
https://github.com/Azure-Samples/openai-dotnet-samples/blob/main/tokenization.ipynb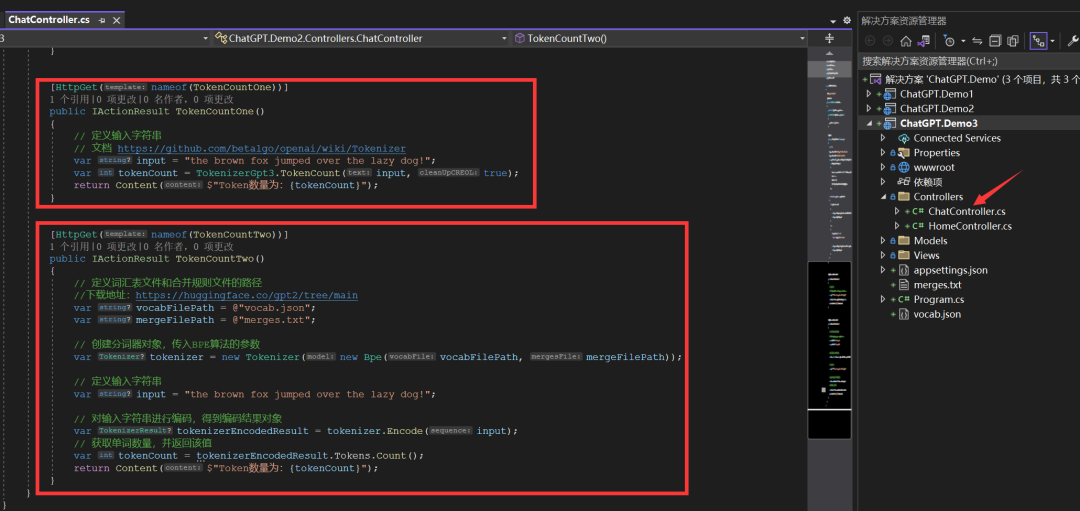
同时,ChatGPT官网也提供了Token查询仪表盘和测试工具给大家使用。
//token仪表盘
https://beta.openai.com/account/usage
//token示例工具
https://platform.openai.com/tokenizerChatGPT新账号有一个初始的消费配额,用完后就要付费才能继续使用。那么,有没有别的方法可以突破这个限制呢?下节我们来探讨如何利用多个ChatGPT的API_KEY进行动态轮询,并能自动删除无效的API_KEY,从而节省成本。
//源码地址
https://github.com/ynanech/ChatGPT.Demo













 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









