






并发编程
ps:每个对象都有一个monitor与之关联,在Java虚拟机(HotSpot)中,monitor是由ObjectMonitor实现的
ObjectMonitor() {
_header = NULL;
_count = 0; //记录个数
_waiters = 0,
_recursions = 0;
_object = NULL;
_owner = NULL;
_WaitSet = NULL; //处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; //处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
ObjectWaiter首先会进入 Entry Set等着,当线程获取到对象的monitor后进入 The Owner 区域并把monitor中的owner变量设置为当前线程,同时monitor中的计数器count加1,若线程调用wait()方法,将释放当前持有的monitor,owner变量恢复为null,count自减1,同时该线程进入 WaitSet集合中等待被唤醒。若当前线程执行完毕也将释放monitor并复位变量的值,以便其他线程进入获取对象的monitor。
重量级锁
synchronized一直被称为重量级锁,monitor依赖于底层操作系统的Lock实现,Java的线程是映射到操作系统的原生线程上,切换成本较高。而在JDK6之后,锁的实现得到了改进。
由于每一个代码块占用的时间大部分情况下其实并不大,所以我们如果强制暂停反而用了更多的时间,所以我们引入自旋锁,通过while不断判断别的线程是否释放了锁资源,在这个基础上引发出了资源占用过多问题,所以我们对自旋锁的次数有了自适应,例如这个线程获取过锁,然后等待别的线程释放锁的时候,系统判断这个线程1是可能获得锁的,但是如果你多次未获得过锁,那么线程很可能判断你不应该采用自旋锁,而是改用重量级锁
轻量级锁
轻量级锁就是赌你当前并没有占用资源,经过CAS(Compare And Swap)算法检验,如果修改的值不是默认应该的数值,那么检测失败,锁会膨胀到自适应自旋锁,也就是检测一下Mark Word是否是当前锁,如果是当前线程,那么就说明没有问题直接执行代码块,如果不是那么这次cas也失败了,直接膨胀到重量级锁,也就是直接退让或者休眠当前线程(注意cas只是检测,没执行代码)
流程: 轻量级锁 -> 失败 -> 自适应自旋锁 -> 失败 -> 重量级锁
第一次cas失败不一定全是进入自旋锁,是进入不同类型锁自身的策略,只是大部分都是自旋锁
解锁过程同样采用CAS算法,如果对象的MarkWord仍然指向线程的锁记录,那么就用CAS操作把对象的MarkWord和复制到栈帧中的Displaced Mark Word进行交换。如果替换失败,说明其他线程尝试过获取该锁,在释放锁的同时,需要唤醒被挂起的线程。
在CPU中,CAS操作使用的是cmpxchg指令,能够从最底层硬件层面得到效率的提升。
由此我们也可以看出轻量级锁如果遇到线程阻塞就是重量级锁了,只是为了方便线程畅通的时候
偏向锁
偏向锁是为了解决局部性连续多次的使用同一线程的情况,所以我们记录了当前线程id,并且只有当有新的线程需要锁的时候才会采取行动,如果是当前线程结束后也不会做别的修改。
如果有别的线程来拿锁了,那么偏向锁会根据当前状态,决定是否要恢复到未锁定或是膨胀为轻量级锁。
值得注意的是,如果对象通过调用hashCode()方法计算过对象的一致性哈希值,那么它是不支持偏向锁的,会直接进入到轻量级锁状态,因为Hash是需要被保存的,而偏向锁的Mark Word数据结构,无法保存Hash值;如果对象已经是偏向锁状态,再去调用hashCode()方法,因为位置不够了,会直接将锁升级为重量级锁,并将哈希值存放在monitor(有预留位置保存)中。
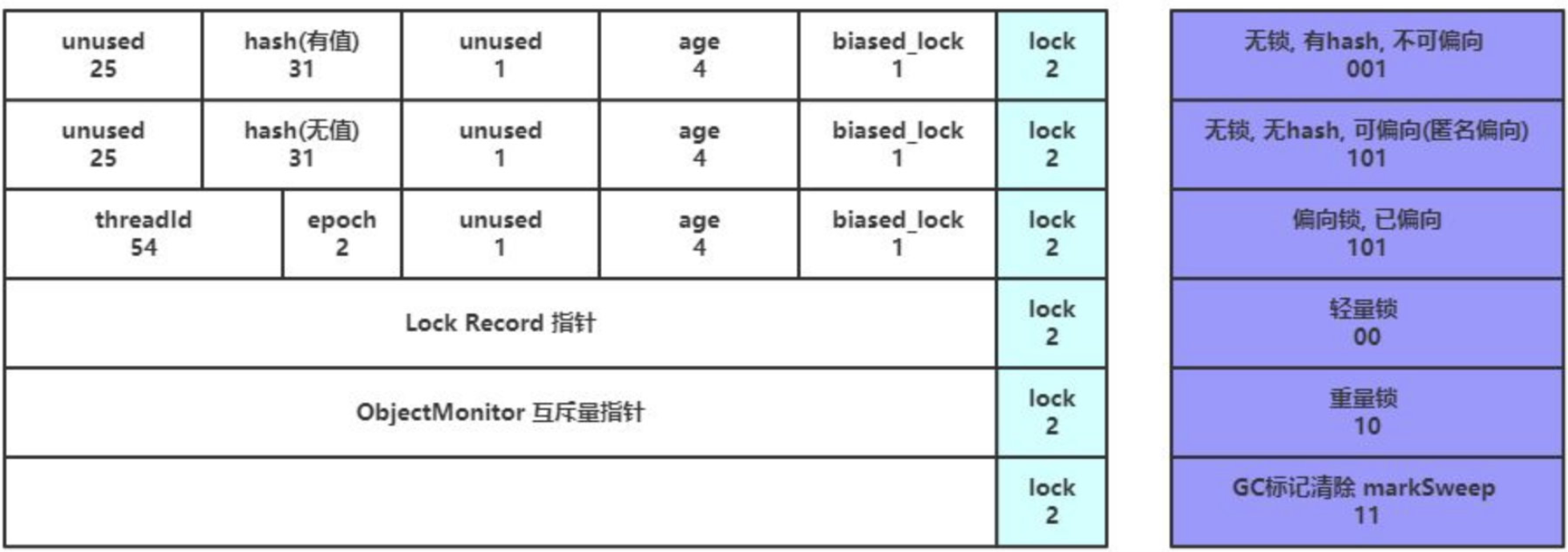
锁消除和锁粗化
锁消除和锁粗化都是在运行时的一些优化方案
比如我们某段代码虽然加了锁,但是在运行时根本不可能出现各个线程之间资源争夺的情况,这种情况下,完全不需要任何加锁机制,所以锁会被消除。
锁粗化则是我们代码中频繁地出现互斥同步操作,比如在一个循环内部加锁,这样明显是非常消耗性能的,所以虚拟机一旦检测到这种操作,会将整个同步范围进行扩展。
JMM内存模型
JMM内存模型并不是整个JVM中的内存模型,而是从中抽象出来的更高一层的内存模型
而在java中,对多线程的内存管理也是有着缓存区,叫做工作内存,工作内存连接java线程以及主内存,并且只通过save和load两种指令与主内存交互
-
所有的变量全部存储在主内存(注意这里包括下面提到的变量,指的都是会出现竞争的变量,包括成员变量、静态变量等,而局部变量这种属于线程私有,不包括在内)
-
每条线程有着自己的工作内存(可以类比CPU的高速缓存)线程对变量的所有操作,必须在工作内存中进行,不能直接操作主内存中的数据。
-
不同线程之间的工作内存相互隔离,如果需要在线程之间传递内容,只能通过主内存完成,无法直接访问对方的工作内存。
通过这几个方法我们就实现了内存的一致性,
重排序
-
编译器重排序:Java编译器通过对Java代码语义的理解,根据优化规则对代码指令进行重排序。
-
机器指令级别的重排序:现代处理器很高级,能够自主判断和变更机器指令的执行顺序。
在重排序的过程中,单线程没有别的影响,但是多线程可能会出现脏读数据,因为单线程比如先分配一个内存大还是小的变量可能有讲究,但是不影响结果,多线程就可能会对公共变量得到脏读
public class Main {
private static int a = 0;
private static int b = 0;
public static void main(String[] args) {
new Thread(() -> {
if(b == 1) {
if(a == 0) {
System.out.println("A");
}else {
System.out.println("B");
}
}
}).start();
new Thread(() -> {
a = 1;
b = 1;
}).start();
}
}
volatile关键字
在并发情况下,我们要保证原子性,可见性,有序性,而volatile关键字能使得给定的变量能够在修改的时候就通知其他线程,也就是变量对所有线程都是透明的,修改了值别的线程都能知道,但是他只是可见,并不能保证原子性,因为即使我能通知别的线程,但如果我两个线程同时执行例如i++,还是有可能两个线程同时取得一个i得值,而我们无法保证原子性,那么这一次i的值就少加了一次1
那么怎么解决原子性呢?目前来看好像只能加锁了
那么我们再来看volatile有什么作用呢?那就是阻止重排序,重排序是个非常危险的举动,很可能打乱写好的逻辑,而volatile就设置了内存屏障来隔绝
内存屏障(Memory Barrier)又称内存栅栏,是一个CPU指令,它的作用有两个:
-
保证特定操作的顺序
-
保证某些变量的内存可见性(volatile的内存可见性,其实就是依靠这个实现的)
由于编译器和处理器都能执行指令重排的优化,如果在指令间插入一条Memory Barrier则会告诉编译器和CPU,不管什么指令都不能和这条Memory Barrier指令重排序。

| 屏障类型 | 指令示例 | 说明 |
|---|---|---|
| LoadLoad | Load1;LoadLoad;Load2 | 保证Load1的读取操作在Load2及后续读取操作之前执行 |
| StoreStore | Store1;StoreStore;Store2 | 在Store2及其后的写操作执行前,保证Store1的写操作已刷新到主内存 |
| LoadStore | Load1;LoadStore;Store2 | 在Store2及其后的写操作执行前,保证Load1的读操作已读取结束 |
| StoreLoad | Store1;StoreLoad;Load2 | 保证load1的写操作已刷新到主内存之后,load2及其后的读操作才能执行 |
经过这一系列操作,可以得出volatile关键字能保证指令一定是按照顺序执行
happens-before原则
经过我们前面的讲解,相信各位已经了解了JMM内存模型以及重排序等机制带来的优点和缺点,综上,JMM提出了happens-before(先行发生)原则,定义一些禁止编译优化的场景,来向各位程序员做一些保证,只要我们是按照原则进行编程,那么就能够保持并发编程的正确性。具体如下:
-
程序次序规则:
同一个线程中,按照程序的顺序,前面的操作happens-before后续的任何操作。
-
同一个线程内,代码的执行结果是有序的。其实就是,可能会发生指令重排,但是保证代码的执行结果一定是和按照顺序执行得到的一致,程序前面对某一个变量的修改一定对后续操作可见的,不可能会出现前面才把a修改为1,接着读a居然是修改前的结果,这也是程序运行最基本的要求。
-
-
监视器锁规则:
对一个锁的解锁操作,happens-before后续对这个锁的加锁操作。
-
就是无论是在单线程环境还是多线程环境,对于同一个锁来说,一个线程对这个锁解锁之后,另一个线程获取了这个锁都能看到前一个线程的操作结果。比如前一个线程将变量
x的值修改为了12并解锁,之后另一个线程拿到了这把锁,对之前线程的操作是可见的,可以得到x是前一个线程修改后的结果12(所以synchronized是有happens-before规则的)
-
-
volatile变量规则:
对一个volatile变量的写操作happens-before后续对这个变量的读操作。
-
就是如果一个线程先去写一个
volatile变量,紧接着另一个线程去读这个变量,那么这个写操作的结果一定对读的这个变量的线程可见。
-
-
线程启动规则:
主线程A启动线程B,线程B中可以看到主线程启动B之前的操作。
-
在主线程A执行过程中,启动子线程B,那么线程A在启动子线程B之前对共享变量的修改结果对线程B可见。
-
-
线程加入规则: 如果线程A执行操作
join()线程B并成功返回,那么线程B中的任意操作happens-before线程Ajoin()操作成功返回。 -
传递性规则: 如果A happens-before B,B happens-before C,那么A happens-before C
锁框架
Lock和Condition接口
public static void main(String[] args) throws InterruptedException {
Lock testLock = new ReentrantLock();
Condition condition = testLock.newCondition();
new Thread(() -> {
testLock.lock(); //和synchronized一样,必须持有锁的情况下才能使用await
System.out.println("线程1进入等待状态!");
try {
condition.await(); //进入等待状态
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程1等待结束!");
testLock.unlock();
}).start();
Thread.sleep(100); //防止线程2先跑
new Thread(() -> {
testLock.lock();
System.out.println("线程2开始唤醒其他等待线程");
condition.signal(); //唤醒线程1,但是此时线程1还必须要拿到锁才能继续运行
System.out.println("线程2结束");
testLock.unlock(); //这里释放锁之后,线程1就可以拿到锁继续运行了
}).start();
}
我们在这其中可以看到wait等操作交给了condition来操作,那么我们需要知道newCondition每次返回的都是一个新的condition对象,所以我们要使用必须先得到这个变量再用变量操作,如果每次都是使用newCondition来调用,就会出现调用的对象不是同一个的情况,也就是condition1暂停了,用signal唤醒condition2的情况
可重入锁
意思是每一个lock对象都可以加多个锁,并且要等所有锁都释放了才能释放线程锁给别的线程,同理condition也可以有多个,都可以通过方法来取得
public static void main(String[] args) throws InterruptedException {
ReentrantLock lock = new ReentrantLock();
Condition condition = lock.newCondition();
lock.lock();
Thread t1 = new Thread(lock::lock), t2 = new Thread(lock::lock);;
new Thread(() -> {
lock.lock();
try {
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
lock.unlock();
}).start();
t1.start();
t2.start();
TimeUnit.SECONDS.sleep(1);
System.out.println("当前等待锁释放的线程数:"+lock.getQueueLength());
System.out.println("线程1是否在等待队列中:"+lock.hasQueuedThread(t1));
System.out.println("线程2是否在等待队列中:"+lock.hasQueuedThread(t2));
System.out.println("当前线程是否在等待队列中:"+lock.hasQueuedThread(Thread.currentThread()));
TimeUnit.SECONDS.sleep(1);
lock.lock();
System.out.println("当前Condition的等待线程数:"+lock.getWaitQueueLength(condition));
condition.signal();
System.out.println("当前Condition的等待线程数:"+lock.getWaitQueueLength(condition));
lock.unlock();
}
公平锁和不公平锁
-
公平锁:多个线程按照申请锁的顺序去获得锁,线程会直接进入队列去排队,永远都是队列的第一位才能得到锁。
-
非公平锁:多个线程去获取锁的时候,会直接去尝试获取,获取不到,再去进入等待队列,如果能获取到,就直接获取到锁。
我们理解起来很容易,但是接着下一个问题,公平锁在任何情况下都一定是公平的吗?有关这个问题,我们会留到队列同步器中再进行讨论。
读写锁
我们知道可重入锁其实是一个排他锁,只有当前线程的所有锁都取消了别的线程才能得到锁,但是在实际场景中,我们其实线程有些只读有些只写,那么我们是否可以将排他锁解锁成读锁和写锁,这样多线程可以同时读和写,能提升读写场景的性能
-
读锁:在没有任何线程占用写锁的情况下,同一时间可以有多个线程加读锁。
-
写锁:在没有任何线程占用读锁的情况下,同一时间只能有一个线程加写锁。
public interface ReadWriteLock {
//获取读锁
Lock readLock();
//获取写锁
Lock writeLock();
}
此接口有一个实现类ReentrantReadWriteLock(实现的是ReadWriteLock接口,不是Lock接口,它本身并不是锁),注意我们操作ReentrantReadWriteLock时,不能直接上锁,而是需要获取读锁或是写锁,再进行锁操作:
ReentrantReadWriteLock不仅具有读写锁的功能,还保留了可重入锁和公平/非公平机制,比如同一个线程可以重复为写锁加锁,并且必须全部解锁才真正释放锁
我们知道读写锁是相互互斥的,但是如果是同一个线程加读写锁是可以的,并且是要先给读锁加锁,这是由于锁降级
锁升级和降级
锁降级必须是携带了写锁再去申请读锁
我们如果先给写锁再给读锁,是锁升级,是可以的,这属于锁降级
但是如果我们在同时加了写锁和读锁的情况下,释放写锁,是否其他的线程就可以一起加读锁了呢?
我们读写共存的前期是同一个线程,这个情况下我们想要新的读锁按照定义是不能有写锁的,所以这次我们要先释放写锁,但是要注意携带写锁,因为读锁可以被多个线程共享,所以这时第二个线程也添加了读锁。而这种操作,就被称之为"锁降级"(注意不是先释放写锁再加读锁,而是持有写锁的情况下申请读锁再释放写锁)
如果是用读锁去申请写锁是不支持的,属于锁升级
队列同步器AQS
这一段我们将讲解lock的逻辑,不贴具体的方法代码,只讲思想
首先搞清楚AQS为父类,子类为Sync,然后公平锁和非公平锁各自继承Sync来实现各自的逻辑
对于管理队列,我们肯定是需要双向链表的,而在此基础上我们有时需要进行循环判断,因为有时候拿锁需要好几次申请,所以我们选用的是循环队列
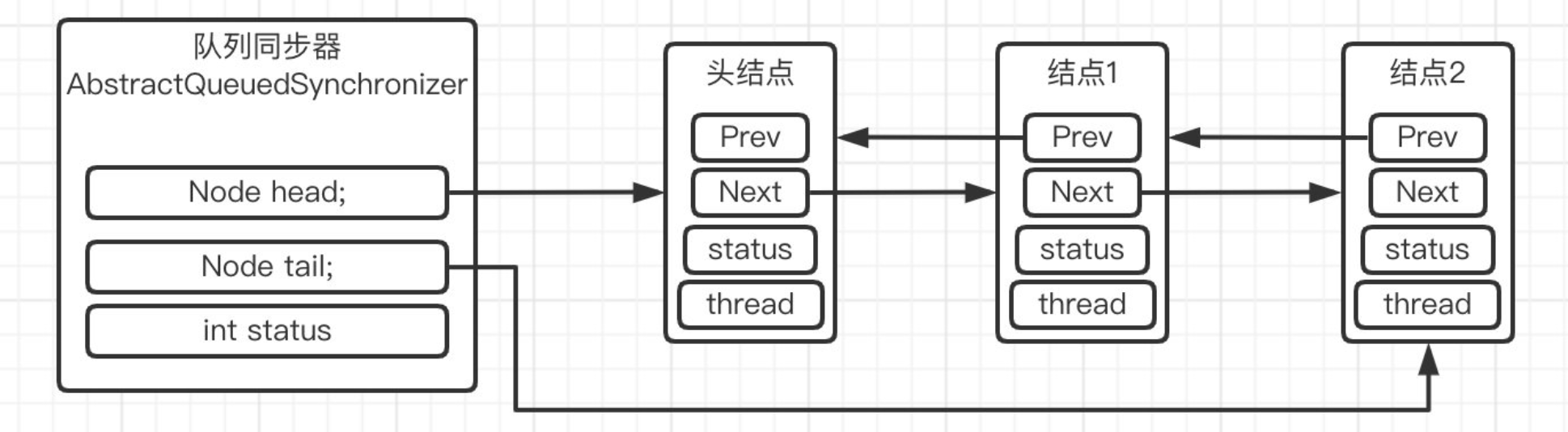
我们可以看到在AQS里面是以Node存储信息,并且每个node都有着前驱和后继节点,并且记录了状态以及线程,那么我们来看看有什么状态
//唯一一个大于0的状态,表示已失效,可能是由于超时或中断,此节点被取消。 static final int CANCELLED = 1; //此节点后面的节点被挂起(进入等待状态),这意味着当前节点正在使用锁 static final int SIGNAL = -1; //在条件队列中的节点才是这个状态 static final int CONDITION = -2; //传播,一般用于共享锁 static final int PROPAGATE = -3;
看完了node定义,我们就应该看看AQS了,初始值都是null和0,那么是什么时候初始化的呢?我们来看代码例子
static { //静态代码块,在类加载的时候就会自动获取偏移地址
try {
//获得每个属性相对于类的偏移量并赋值,那么就能得到这些初始值,用于下面的CAS操作
stateOffset = unsafe.objectFieldOffset
(AbstractQueuedSynchronizer.class.getDeclaredField("state"));
headOffset = unsafe.objectFieldOffset
(AbstractQueuedSynchronizer.class.getDeclaredField("head"));
tailOffset = unsafe.objectFieldOffset
(AbstractQueuedSynchronizer.class.getDeclaredField("tail"));
waitStatusOffset = unsafe.objectFieldOffset
(Node.class.getDeclaredField("waitStatus"));
nextOffset = unsafe.objectFieldOffset
(Node.class.getDeclaredField("next"));
} catch (Exception ex) { throw new Error(ex); }
}
//通过CAS操作来修改头结点(这里只举例头节点,至于尾节点,下一个节点,和等待状态都是同理)
private final boolean compareAndSetHead(Node update) {
//调用的是Unsafe类的compareAndSwapObject方法,通过CAS算法比较对象并替换
//注意这个unsafe的方法是直接修改变量的堆内存的,效率高
//四个参数分别是对象,相对对象的偏移量,cas的预期值,以及新的更新值
return unsafe.compareAndSwapObject(this, headOffset, null, update);
}
加锁
以公平锁为例,我们看一下是如何执行加锁的 首先是lock操作,我们首先肯定是获取锁,那么我们会执行两个操作 首先是尝试获取锁(tryAcquire),我们通过是否是当前线程,是否已经有线程占用这两个条件来实现是否独占和重入锁, 第二步首先调用addWaiter(Node.EXCLUSIVE)方法,注意这里是入队,所以我们首先会直接看看能否直接CAS入队,也就是如果当前尾节点不为空,意味着队列里还有等待队列,我们就需要尝试调用CAS操作加入尾节点,如果成功了那么就直接返回node了,没成功会调用enq方法,通过不断循环判断是否可以成功CAS,也就是进入了自旋,最后也是返回之前的尾node 第二步的返回值会传给acquireQueued方法,这个方法返回的是是否中断,并且使用了无限循环,我们会先获得当前addWaiter返回节点的前驱节点,首先判断是否是头节点,如果是那么按照顺序就应该轮到当前节点了,所以会调用tryAcquire尝试获取锁,如果成功了直接删除之前的头节点并更新,但是如果失败了我们也会执行两个方法 第一个是parkAndCheckInterrupt(),这个比较简单,只是挂起当前线程,并且返回当前线程是否中断 第二个是shouldParkAfterFailedAcquire(p, node),在这个方法里我们做两件事,第一件事判断前驱节点p是否已经是Signal状态,如果是直接返回True,如果status>0也就是被取消的节点,那么就一路接着往前找到没被取消的节点并且抛弃这些节点,直接转变当前node的prev,等到下一轮调用此方法时就会尝试设置Signal状态了,最后返回false(这里要注意,只有当前线程中断了并且前驱节点是signal状态时这个方法才会返回True,也就是返回中断为True,否则不管shouldParkAfterFailedAcquire方法返回的是什么,都是要进行下一轮循环,只有中断了并且挂起了才能结束抛弃这个节点)
通过无线for循环来添加节点到队列中并形成双向链表。
@ReservedStackAccess
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) { //可以看到当此节点位于队首(node.prev == head)时,会再次调用tryAcquire方法获取锁,如果获取成功,会返回此过程中是否被中断的值
setHead(node); //新的头结点设置为当前结点
p.next = null; // 原有的头结点没有存在的意义了
failed = false; //没有失败
return interrupted; //直接返回等待过程中是否被中断
}
//依然没获取成功,
if (shouldParkAfterFailedAcquire(p, node) && //将当前节点的前驱节点等待状态设置为SIGNAL,如果失败将直接开启下一轮循环,直到成功为止,如果成功接着往下
parkAndCheckInterrupt()) //挂起线程进入等待状态,等待被唤醒,如果在等待状态下被中断,那么会返回true,直接将中断标志设为true,否则就是正常唤醒,继续自旋
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this); //通过unsafe类操作底层挂起线程(会直接进入阻塞状态)
return Thread.interrupted();
}
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
return true; //已经是SIGNAL,直接true
if (ws > 0) { //不能是已经取消的节点,必须找到一个没被取消的
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node; //直接抛弃被取消的节点
} else {
//不是SIGNAL,先CAS设置为SIGNAL(这里没有返回true因为CAS不一定成功,需要下一轮再判断一次)
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false; //返回false,马上开启下一轮循环
}
解锁
直接调用release方法
我们直接尝试解锁如果解锁成功,那么我们直接判断头节点是否为空并且是否为signal状态,如果是那么我们直接唤醒下一个节点线程,就完成解锁了
@ReservedStackAccess
public final boolean release(int arg) {
if (tryRelease(arg)) { //和tryAcquire一样,也得子类去重写,释放锁操作
Node h = head; //释放锁成功后,获取新的头结点
if (h != null && h.waitStatus != 0) //如果新的头结点不为空并且不是刚刚建立的结点(初始状态下status为默认值0,而上面在进行了shouldParkAfterFailedAcquire之后,会被设定为SIGNAL状态,值为-1)
unparkSuccessor(h); //唤醒头节点下一个节点中的线程
return true;
}
return false;
}
private void unparkSuccessor(Node node) {
// 将等待状态waitStatus设置为初始值0
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
//获取下一个结点
Node s = node.next;
if (s == null || s.waitStatus > 0) { //如果下一个结点为空或是等待状态是已取消,那肯定是不能通知unpark的,这时就要遍历所有节点再另外找一个符合unpark要求的节点了
s = null;
for (Node t = tail; t != null && t != node; t = t.prev) //这里是从队尾向前,因为enq()方法中的t.next = node是在CAS之后进行的,而 node.prev = t 是CAS之前进行的,所以从后往前一定能够保证遍历所有节点
if (t.waitStatus <= 0)
s = t;
}
if (s != null) //要是找到了,就直接unpark,要是还是没找到,那就算了
LockSupport.unpark(s.thread);
}
@ReservedStackAccess
protected final boolean tryRelease(int releases) {
int c = getState() - releases; //先计算本次解锁之后的状态值
if (Thread.currentThread() != getExclusiveOwnerThread()) //因为是独占锁,那肯定这把锁得是当前线程持有才行
throw new IllegalMonitorStateException(); //否则直接抛异常
boolean free = false;
if (c == 0) { //如果解锁之后的值为0,表示已经完全释放此锁
free = true;
setExclusiveOwnerThread(null); //将独占锁持有线程设置为null
}
setState(c); //状态值设定为c
return free; //如果不是0表示此锁还没完全释放,返回false,是0就返回true
}

公平锁一定公平吗?
@ReservedStackAccess
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() && //注意这里,公平锁的机制是,一开始会查看是否有节点处于等待
compareAndSetState(0, acquires)) { //如果前面的方法执行后发现没有等待节点,就直接进入占锁环节了
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
我们从上面可以看到,公平锁想要保证顺序是通过tryAcquire里的hasQueuedPredecessors判断的那么我们来看 hasQueuedPredecessors方法
public final boolean hasQueuedPredecessors() {
Node t = tail; // Read fields in reverse initialization order
Node h = head;
Node s;
//这里直接判断h != t,而此时线程2才刚刚执行完 tail = head,所以直接就返回false了
return h != t &&
((s = h.next) == null || s.thread != Thread.currentThread());
}
我们可以看到返回的第一个判断条件是头尾是否相同,这个就很奇妙了,因为我们在enq方法中有一步就是将头赋值给尾,所以如果a线程先拿了锁,导致b线程需要入队,而正在赋值这一句时,线程c正好发送请求了,开始执行hasQueuedPredecessors方法,因为头尾都是全局变量,所以就会误判,导致了a的锁如果释放这时就会给3
所以找锁的问题就是考虑是否可能在同一时刻有线程同时调用共同的东西,导致不一样的结果
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // 线程2进来之后,肯定是要先走这里的,因为head和tail都是null
if (compareAndSetHead(new Node()))
tail = head; //这里就将tail直接等于head了,注意这里完了之后还没完,这里只是初始化过程
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
Node pred = tail;
if (pred != null) { //由于一开始head和tail都是null,所以线程2直接就进enq()了
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node); //请看上面
return node;
}
Condition实现原理
我们知道一般的锁只能用一次wait/notify方法,但是这样无法添加多次,而condition可以有多个并且替代锁本身使用wait/notify,这样我们可以对多种条件分别用一个condition来锁,条理更清晰 ·
Condition的实现类也同样利用队列机制,并直接复用了Node,但是这个条件队列是单向列表,靠nextWaiter(在lock里这个存储的是独占node或者共享node)连接,不过依旧记录了头尾组成环
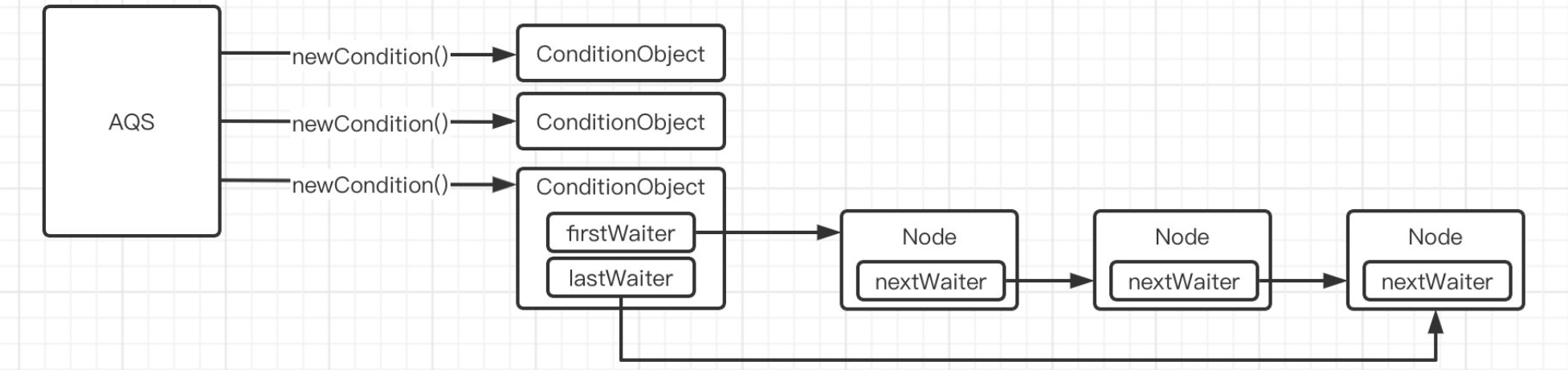
当一个线程调用await()方法时,会进入等待状态,直到其他线程调用signal()方法将其唤醒,而这里的条件队列,正是用于存储这些处于等待状态的线程。
我们首先来看await()的目标
-
只有已经持有锁的线程才可以使用此方法
-
当调用此方法后,会直接释放锁,无论加了多少次锁
-
只有其他线程调用
signal()或是被中断时才会唤醒等待中的线程 -
被唤醒后,需要等待其他线程释放锁,拿到锁之后才可以继续执行,并且会恢复到之前的状态(await之前加了几层锁唤醒后依然是几层锁)
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException(); //如果在调用await之前就被添加了中断标记,那么会直接抛出中断异常
Node node = addConditionWaiter(); //为当前线程创建一个新的节点,并将其加入到条件队列中
int savedState = fullyRelease(node); //完全释放当前线程持有的锁,并且保存一下state值,因为唤醒之后还得恢复
int interruptMode = 0; //用于保存中断状态
while (!isOnSyncQueue(node)) { //循环判断是否位于同步队列中,如果等待状态下的线程被其他线程唤醒,那么会正常进入到AQS的等待队列中(之后我们会讲)
LockSupport.park(this); //如果依然处于等待状态,那么继续挂起
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0) //看看等待的时候是不是被中断了
break;
}
//出了循环之后,那线程肯定是已经醒了,这时就差拿到锁就可以恢复运行了
if (acquireQueued(node, savedState) && interruptMode != THROW_IE) //直接开始acquireQueued尝试拿锁(之前已经讲过了)从这里开始基本就和一个线程去抢锁是一样的了
interruptMode = REINTERRUPT;
//已经拿到锁了,基本可以开始继续运行了,这里再进行一下后期清理工作
if (node.nextWaiter != null)
unlinkCancelledWaiters(); //将等待队列中,不是Node.CONDITION状态的节点移除
if (interruptMode != 0) //依然是响应中断
reportInterruptAfterWait(interruptMode);
//OK,接着该干嘛干嘛
}
接着是signal()
-
只有持有锁的线程才能唤醒锁所属的Condition等待的线程
-
优先唤醒条件队列中的第一个,如果唤醒过程中出现问题,接着找往下找,直到找到一个可以唤醒的
-
唤醒操作本质上是将条件队列中的结点直接丢进AQS等待队列中,让其参与到锁的竞争中
-
拿到锁之后,线程才能恢复运行
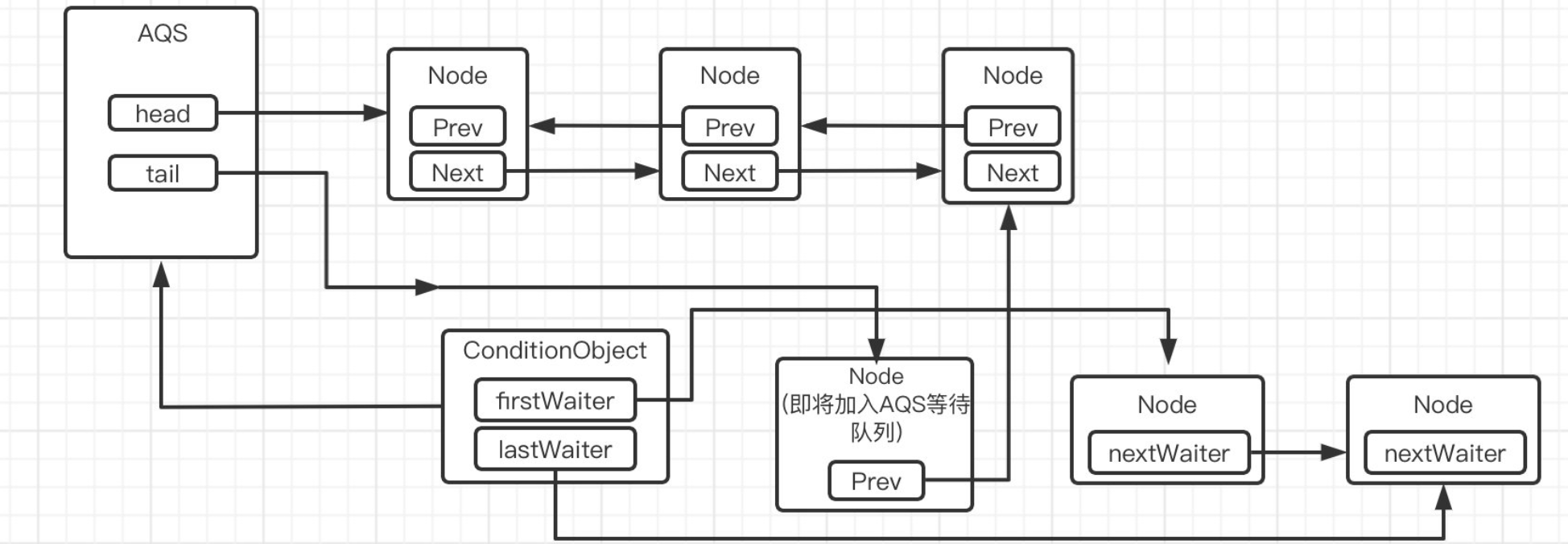
这里就是通过将等待队列的node给到AQS的循环队列里实现调用,建立连接
public final void signal() {
if (!isHeldExclusively()) //先看看当前线程是不是持有锁的状态
throw new IllegalMonitorStateException(); //不是?那你不配唤醒别人
Node first = firstWaiter; //获取条件队列的第一个结点
if (first != null) //如果队列不为空,获取到了,那么就可以开始唤醒操作
doSignal(first);
}
private void doSignal(Node first) {
do {
if ( (firstWaiter = first.nextWaiter) == null) //如果当前节点在本轮循环没有后继节点了,条件队列就为空了
lastWaiter = null; //所以这里相当于是直接清空
first.nextWaiter = null; //将给定节点的下一个结点设置为null,因为当前结点马上就会离开条件队列了
} while (!transferForSignal(first) && //接着往下看
(first = firstWaiter) != null); //能走到这里只能说明给定节点被设定为了取消状态,那就继续看下一个结点
}
final boolean transferForSignal(Node node) {
/*
* 如果这里CAS失败,那有可能此节点被设定为了取消状态
*/
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))
return false;
//CAS成功之后,结点的等待状态就变成了默认值0,接着通过enq方法直接将节点丢进AQS的等待队列中,相当于唤醒并且可以等待获取锁了
//这里enq方法返回的是加入之后等待队列队尾的前驱节点,就是原来的tail
Node p = enq(node);
int ws = p.waitStatus; //保存前驱结点的等待状态
//如果上一个节点的状态为取消, 或者尝试设置上一个节点的状态为SIGNAL失败(可能是在ws>0判断完之后马上变成了取消状态,导致CAS失败)
if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))
LockSupport.unpark(node.thread); //直接唤醒线程
return true;
}
倒数第二行,明明上面都正常进入到AQS等待队列了,应该是可以开始走正常流程了,那么这里为什么还要提前来一次unpark呢?
这里其实是为了进行优化而编写,直接unpark会有两种情况:
-
如果插入结点前,AQS等待队列的队尾节点就已经被取消,则满足wc > 0
-
如果插入node后,AQS内部等待队列的队尾节点已经稳定,满足tail.waitStatus == 0,但在执行ws >0之后
!compareAndSetWaitStatus(p, ws,Node.SIGNAL)之前被取消,则CAS也会失败,满足compareAndSetWaitStatus(p, ws,Node.SIGNAL) == false
如果这里被提前unpark,那么在await()方法中将可以被直接唤醒,并跳出while循环,直接开始争抢锁,因为前一个等待结点是被取消的状态,没有必要再等它了。

原子类
原子类顾名思义就是有着原子性的数据类型,有对应的原子类封装:
-
AtomicInteger:原子更新int
-
AtomicLong:原子更新long
-
AtomicBoolean:原子更新boolean
-
AtomicIntegerArray:原子更新int数组
-
AtomicLongArray:原子更新long数组
-
AtomicReferenceArray:原子更新引用数组
原子类和普通类不同的一点是赋值需要在构造方法的时候赋值,例如
public class Main {
public static void main(String[] args) {
AtomicInteger i = new AtomicInteger(1);
System.out.println(i.getAndIncrement());
}
}
为什么会这样呢?因为他底层也是与AQS类似,使用偏移量来进行CAS操作 至于原子性是通过内部维护一个volatile修饰的value值来保证可见
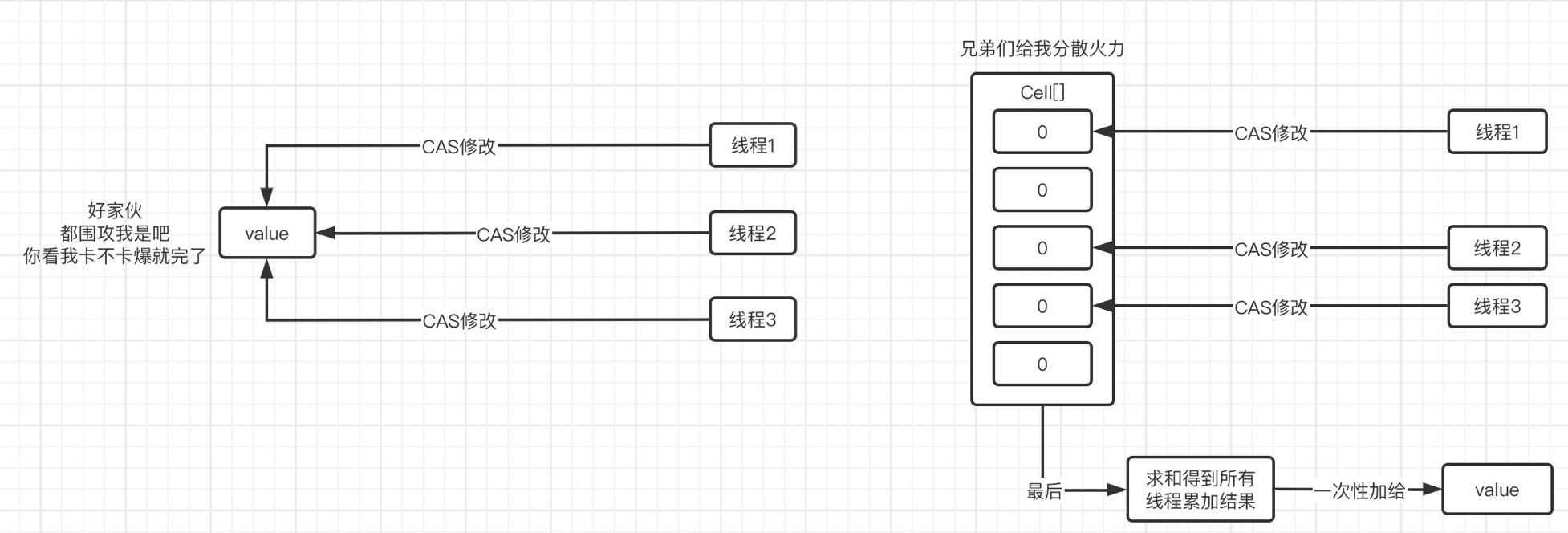
在JDK8之后,新增了DoubleAdder和LongAdder,在高并发情况下,LongAdder的性能比AtomicLong的性能更好,主要体现在自增上,它的大致原理如下:在低并发情况下,和AtomicLong是一样的,对value值进行CAS操作,但是出现高并发的情况时,AtomicLong会进行大量的循环操作来保证同步,而LongAdder会将对value值的CAS操作分散为对数组cells中多个元素的CAS操作(内部维护一个Cell[] as数组,每个Cell里面有一个初始值为0的long型变量,在高并发时会进行分散CAS,就是不同的线程可以对数组中不同的元素进行CAS自增,这样就避免了所有线程都对同一个值进行CAS),只需要最后再将结果加起来即可
public static void main(String[] args) throws InterruptedException {
LongAdder adder = new LongAdder();
Runnable r = () -> {
for (int i = 0; i < 100000; i++)
adder.add(1);
};
for (int i = 0; i < 100; i++)
new Thread(r).start(); //100个线程
TimeUnit.SECONDS.sleep(1);
System.out.println(adder.sum()); //最后求和即可
}
ABA问题
原子类的CAS操作其实也只是检查了期望值是否正确,但是有一种可能,之前的线程A将值从A->B->A,连续两次变换,这样检测出来的期望值不变,但是线程还在使用,这样就有线程安全问题了,那么我们希望能有唯一标识来识别,所以给每个操作都打上tag版本号
public static void main(String[] args) throws InterruptedException {
String a = "Hello";
String b = "World";
AtomicStampedReference<String> reference = new AtomicStampedReference<>(a, 1); //在构造时需要指定初始值和对应的版本号
reference.attemptStamp(a, 2); //可以中途对版本号进行修改,注意要填写当前的引用对象
System.out.println(reference.compareAndSet(a, b, 2, 3)); //CAS操作时不仅需要提供预期值和修改值,还要提供预期版本号和新的版本号
}
传统容器线程安全
例如hashmap,list等传统容器,因为没有锁,所以多线程情况下list可能会导致A扩容了,但是有B抢占了扩容得位置,导致A添加元素得时候越界。
hashmap会发生环状数据结构,问题发生在更新线程在遍历线程正在处理的Entry对象上添加新的元素或修改键值对。假设遍历线程刚刚遍历了键为1的Entry对象,并准备遍历键为2的Entry对象。此时,更新线程找到了键为2的Entry对象,并将其值更新为"New Value",然后删除这个Entry对象。
由于遍历线程的迭代器是基于之前的状态创建的,它不会意识到Entry对象已经被删除。因此,当遍历线程尝试访问键为2的Entry对象时,它会认为这个Entry对象仍然存在,并尝试输出其键和值。但由于这个Entry对象实际上已经被删除,这将导致ConcurrentModificationException异常。
当遍历线程尝试访问这个已经不存在的Entry对象时,迭代器会尝试回溯到下一个Entry对象,但是由于HashMap的结构已经被改变,这个下一个Entry对象可能已经不再存在,或者指向了不同的Entry对象。这导致迭代器可能会无限循环地在几个剩余的Entry对象之间来回移动,因为它无法找到它期望的顺序或达到迭代器的末尾。
这种情况下,迭代器不会抛出ConcurrentModificationException异常,因为它并没有检测到映射结构的根本改变,而是检测到了循环或不一致的引用。这种情况下,迭代器可能会进入一个看似无限循环的状态,因为它无法继续按照原来的路径遍历HashMap。
并发容器
首先是array的并发CopyOnWriteArrayList
他是通过内部获得一个锁,来保证线程,并且每次操作是新建一个数组操作后再赋值回去
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock(); //直接加锁,保证同一时间只有一个线程进行添加操作
try {
Object[] elements = getArray(); //获取当前存储元素的数组
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1); //直接复制一份数组
newElements[len] = e; //修改复制出来的数组
setArray(newElements); //将元素数组设定为复制出来的数组
return true;
} finally {
lock.unlock();
}
}
接下来是hashmap的并发ConcurrentHashMap
他的内部其实就是将某一个key给锁住,分段锁的思想这样可以让别的key操作可以并行,并且没有冲突
public V put(K key, V value) {
return putVal(key, value, false);
}
//有点小乱,如果看着太乱,可以在IDEA中折叠一下代码块,不然有点难受
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException(); //键值不能为空,基操
int hash = spread(key.hashCode()); //计算键的hash值,用于确定在哈希表中的位置
int binCount = 0; //一会用来记录链表长度的,忽略
for (Node<K,V>[] tab = table;;) { //无限循环,而且还是并发包中的类,盲猜一波CAS自旋锁
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable(); //如果数组(哈希表)为空肯定是要进行初始化的,然后再重新进下一轮循环
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //如果哈希表该位置为null,直接CAS插入结点作为头结即可(注意这里会将f设置当前哈希表位置上的头结点)
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // 如果CAS成功,直接break结束put方法,失败那就继续下一轮循环
} else if ((fh = f.hash) == MOVED) //头结点哈希值为-1,这里只需要知道是因为正在扩容即可
tab = helpTransfer(tab, f); //帮助进行迁移,完事之后再来下一次循环
else { //特殊情况都完了,这里就该是正常情况了,
V oldVal = null;
synchronized (f) { //在前面的循环中f肯定是被设定为了哈希表某个位置上的头结点,这里直接把它作为锁加锁了,防止同一时间其他线程也在操作哈希表中这个位置上的链表或是红黑树
if (tabAt(tab, i) == f) {
if (fh >= 0) { //头结点的哈希值大于等于0说明是链表,下面就是针对链表的一些列操作
...实现细节略
} else if (f instanceof TreeBin) { //肯定不大于0,肯定也不是-1,还判断是不是TreeBin,所以不用猜了,肯定是红黑树,下面就是针对红黑树的情况进行操作
//在ConcurrentHashMap并不是直接存储的TreeNode,而是TreeBin
...实现细节略
}
}
}
//根据链表长度决定是否要进化为红黑树
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i); //注意这里只是可能会进化为红黑树,如果当前哈希表的长度小于64,它会优先考虑对哈希表进行扩容
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
阻塞队列
阻塞队列其实就是基于lock实现的队列,这里看一下方法熟悉一下
public interface BlockingQueue<E> extends Queue<E> {
boolean add(E e);
//入队,如果队列已满,返回false否则返回true(非阻塞)
boolean offer(E e);
//入队,如果队列已满,阻塞线程直到能入队为止
void put(E e) throws InterruptedException;
//入队,如果队列已满,阻塞线程直到能入队或超时、中断为止,入队成功返回true否则false
boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException;
//出队,如果队列为空,阻塞线程直到能出队为止
E take() throws InterruptedException;
//出队,如果队列为空,阻塞线程直到能出队超时、中断为止,出队成功正常返回,否则返回null
E poll(long timeout, TimeUnit unit)
throws InterruptedException;
//返回此队列理想情况下(在没有内存或资源限制的情况下)可以不阻塞地入队的数量,如果没有限制,则返回 Integer.MAX_VALUE
int remainingCapacity();
boolean remove(Object o);
public boolean contains(Object o);
//一次性从BlockingQueue中获取所有可用的数据对象(还可以指定获取数据的个数)
int drainTo(Collection<? super E> c);
int drainTo(Collection<? super E> c, int maxElements);
我们可以看到大部分要么有时限,要么就是有取有出
接下来我们来看基于阻塞队列的消费者和生产者的例子
public class Main {
public static void main(String[] args) throws InterruptedException {
BlockingQueue<Object> queue = new ArrayBlockingQueue<>(1);
Runnable supplier = () -> {
while (true){
try {
String name = Thread.currentThread().getName();
System.err.println(time()+"生产者 "+name+" 正在准备餐品...");
TimeUnit.SECONDS.sleep(3);
System.err.println(time()+"生产者 "+name+" 已出餐!");
queue.put(new Object());
} catch (InterruptedException e) {
e.printStackTrace();
break;
}
}
};
Runnable consumer = () -> {
while (true){
try {
String name = Thread.currentThread().getName();
System.out.println(time()+"消费者 "+name+" 正在等待出餐...");
queue.take();
System.out.println(time()+"消费者 "+name+" 取到了餐品。");
TimeUnit.SECONDS.sleep(4);
System.out.println(time()+"消费者 "+name+" 已经将饭菜吃完了!");
} catch (InterruptedException e) {
e.printStackTrace();
break;
}
}
};
for (int i = 0; i < 2; i++) new Thread(supplier, "Supplier-"+i).start();
for (int i = 0; i < 3; i++) new Thread(consumer, "Consumer-"+i).start();
}
private static String time(){
SimpleDateFormat format = new SimpleDateFormat("HH:mm:ss");
return "["+format.format(new Date()) + "] ";
}
}
基于阻塞队列一般有三个常用的实现类
-
ArrayBlockingQueue:有界带缓冲阻塞队列(就是队列是有容量限制的,装满了肯定是不能再装的,只能阻塞,数组实现)
-
SynchronousQueue:无缓冲阻塞队列(相当于没有容量的ArrayBlockingQueue,因此只有阻塞的情况)
-
LinkedBlockingQueue:无界带缓冲阻塞队列(没有容量限制,也可以限制容量,也会阻塞,链表实现)
final ReentrantLock lock;
private final Condition notEmpty;
private final Condition notFull;
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair); //底层采用锁机制保证线程安全性,这里我们可以选择使用公平锁或是非公平锁
notEmpty = lock.newCondition(); //这里创建了两个Condition(都属于lock)一会用于入队和出队的线程阻塞控制,这里就是前面condition提到的分条理控制
notFull = lock.newCondition();
}
SynchronousQueue内部是通过一个transfer通过线程交接的方式来进行操作的,因为只有两种状态回来,所以直接在一个方法里编写两种情况
E transfer(E e, boolean timed, long nanos) { //注意这里面没加锁,肯定会多个线程之间竞争
QNode s = null;
boolean isData = (e != null); //e为空表示消费者,不为空表示生产者
for (;;) {
QNode t = tail;
QNode h = head;
if (t == null || h == null) // 头结点尾结点任意为空(但是在构造的时候就已经不是空了)
continue; // 自旋
if (h == t || t.isData == isData) { // 头结点等于尾结点表示队列中只有一个头结点,肯定是空,或者尾结点角色和当前节点一样,这两种情况下,都需要进行入队操作
QNode tn = t.next;
if (t != tail) // 如果这段时间内t被其他线程修改了,如果是就进下一轮循环重新来
continue;
if (tn != null) { // 继续校验是否为队尾,如果tn不为null,那肯定是其他线程改了队尾,可以进下一轮循环重新来了
advanceTail(t, tn); // CAS将新的队尾节点设置为tn,成不成功都无所谓,反正这一轮肯定没戏了
continue;
}
if (timed && nanos <= 0) // 超时返回null
return null;
if (s == null)
s = new QNode(e, isData); //构造当前结点,准备加入等待队列
if (!t.casNext(null, s)) // CAS添加当前节点为尾结点的下一个,如果失败肯定其他线程又抢先做了,直接进下一轮循环重新来
continue;
advanceTail(t, s); // 上面的操作基本OK了,那么新的队尾元素就修改为s
Object x = awaitFulfill(s, e, timed, nanos); //开始等待s所对应的消费者或是生产者进行交接,比如s现在是生产者,那么它就需要等到一个消费者的到来才会继续(这个方法会先进行自旋等待匹配,如果自旋一定次数后还是没有匹配成功,那么就挂起)
if (x == s) { // 如果返回s本身说明等待状态下被取消
clean(t, s);
return null;
}
if (!s.isOffList()) { // 如果s操作完成之后没有离开队列,那么这里将其手动丢弃
advanceHead(t, s); // 将s设定为新的首节点(注意头节点仅作为头结点,并非处于等待的线程节点)
if (x != null) // 删除s内的其他信息
s.item = s;
s.waiter = null;
}
return (x != null) ? (E)x : e; //假如当前是消费者,直接返回x即可,x就是从生产者那里拿来的元素
} else { // 这种情况下就是与队列中结点类型匹配的情况了(注意队列要么为空要么只会存在一种类型的节点,因为一旦出现不同类型的节点马上会被交接掉)
QNode m = h.next; // 获取头结点的下一个接口,准备进行交接工作
if (t != tail || m == null || h != head)
continue; // 判断其他线程是否先修改,如果修改过那么开下一轮
Object x = m.item;
if (isData == (x != null) || // 判断节点类型,如果是相同的操作,那肯定也是有问题的
x == m || // 或是当前操作被取消
!m.casItem(x, e)) { // 上面都不是?那么最后再进行CAS替换m中的元素,成功表示交接成功,失败就老老实实重开吧
advanceHead(h, m); // dequeue and retry
continue;
}
advanceHead(h, m); // 成功交接,新的头结点可以改为m了,原有的头结点直接不要了
LockSupport.unpark(m.waiter); // m中的等待交接的线程可以继续了,已经交接完成
return (x != null) ? (E)x : e; // 同上,该返回什么就返回什么
}
}
}
我们知道,SynchronousQueue并没有使用锁,而是采用CAS操作保证生产者与消费者的协调,但是它没有容量,而LinkedBlockingQueue虽然是有容量且无界的,但是内部基本都是基于锁实现的,性能并不是很好,这时,我们就可以将它们各自的优点单独拿出来,揉在一起,就成了性能更高的LinkedTransferQueue
接着我们来了解一些其他的队列:
-
PriorityBlockingQueue - 是一个支持优先级的阻塞队列,元素的获取顺序按优先级决定。
-
DelayQueue - 它能够实现延迟获取元素,同样支持优先级。
先看优先阻塞队列
public static void main(String[] args) throws InterruptedException {
PriorityBlockingQueue<Integer> queue =
new PriorityBlockingQueue<>(10, Integer::compare); //可以指定初始容量(可扩容)和优先级比较规则,这里我们使用升序
queue.add(3);
queue.add(1);
queue.add(2);
System.out.println(queue); //注意保存顺序并不会按照优先级排列,所以可以看到结果并不是排序后的结果
System.out.println(queue.poll()); //但是出队顺序一定是按照优先级进行的
System.out.println(queue.poll());
System.out.println(queue.poll());
}
再来看延迟队列
public static void main(String[] args) throws InterruptedException {
DelayQueue<Test> queue = new DelayQueue<>();
queue.add(new Test(1, 2, "2号")); //1秒钟延时
queue.add(new Test(3, 1, "1号")); //1秒钟延时,优先级最高
System.out.println(queue.take()); //注意出队顺序是依照优先级来的,即使一个元素已经可以出队了,依然需要等待优先级更高的元素到期
System.out.println(queue.take());
private static class Test implements Delayed {
private final long time; //延迟时间,这里以毫秒为单位
private final int priority;
private final long startTime;
private final String data;
private Test(long time, int priority, String data) {
this.time = TimeUnit.SECONDS.toMillis(time); //秒转换为毫秒
this.priority = priority;
this.startTime = System.currentTimeMillis(); //这里我们以毫秒为单位
this.data = data;
}
@Override
public long getDelay(TimeUnit unit) {
long leftTime = time - (System.currentTimeMillis() - startTime); //计算剩余时间 = 设定时间 - 已度过时间(= 当前时间 - 开始时间)
return unit.convert(leftTime, TimeUnit.MILLISECONDS); //注意进行单位转换,单位由队列指定(默认是纳秒单位)
}
@Override
public int compareTo(Delayed o) {
if(o instanceof Test)
return priority - ((Test) o).priority; //优先级越小越优先
return 0;
}
@Override
public String toString() {
return data;
}
}
}
线程池
corePoolSize:核心线程池大小,我们每向线程池提交一个多线程任务时,都会创建一个新的核心线程,无论是否存在其他空闲线程,直到到达核心线程池大小为止,之后会尝试复用线程资源。当然也可以在一开始就全部初始化好,调用prestartAllCoreThreads()即可。
maximumPoolSize:最大线程池大小,当目前线程池中所有的线程都处于运行状态,并且等待队列已满,那么就会直接尝试继续创建新的非核心线程运行,但是不能超过最大线程池大小。
keepAliveTime:线程最大空闲时间,当一个非核心线程空闲超过一定时间,会自动销毁。
unit:线程最大空闲时间的时间单位
workQueue:线程等待队列,当线程池中核心线程数已满时,就会将任务暂时存到等待队列中,直到有线程资源可用为止,这里可以使用我们上一章学到的阻塞队列。
threadFactory:线程创建工厂,我们可以干涉线程池中线程的创建过程,进行自定义。
handler:拒绝策略,当等待队列和线程池都没有空间了,真的不能再来新的任务时,来了个新的多线程任务,那么只能拒绝了,这时就会根据当前设定的拒绝策略进行处理。
定义例子如下
ThreadPoolExecutor executor =
new ThreadPoolExecutor(2, 4,
3, TimeUnit.SECONDS,
new SynchronousQueue<>(),
new ThreadPoolExecutor.CallerRunsPolicy());
我们通过流程来理解一下这几个参数 按照最大核心线程数创建核心线程->如果线程满了->放入阻塞队列->阻塞队列满了->创建最大线程池大小允许的新线程->如果还是超了->拒绝策略决定怎么处理
-
AbortPolicy(默认):像上面一样,直接抛异常。
-
CallerRunsPolicy:直接让提交任务的线程运行这个任务,比如在主线程向线程池提交了任务,那么就直接由主线程执行。
-
DiscardOldestPolicy:丢弃队列中最近的一个任务,替换为当前任务。
-
DiscardPolicy:什么也不用做。
接下来看看封装好的线程池
ExecutorService service = Executors.newSingleThreadExecutor();
//ExecutorService service = Executors.newFixedThreadPool(2);
for (int i = 0; i < 2; i++) {
service.submit(()->{
System.out.println("hhhh");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
}
service.shutdown();
有返回值的线程池
public static void main(String[] args) throws InterruptedException, ExecutionException {
ExecutorService service = Executors.newFixedThreadPool(1);
// Future<String> future = service.submit(() ->{
// try {
// TimeUnit.SECONDS.sleep(3);
// } catch (InterruptedException e) {
// throw new RuntimeException(e);
// }
// }, "我是字符串!");
FutureTask<String> task = new FutureTask<>(() -> "我是字符串!");
service.submit(task);
System.out.println(task.get());
service.shutdown();
}
设置定时任务的线程池
public static void main(String[] args) throws InterruptedException, ExecutionException {
ScheduledExecutorService service = new ScheduledThreadPoolExecutor(1);
//ScheduledExecutorService service = Executors.newScheduledThreadPool(1);
//ScheduledFuture<String> schedule = service.schedule(() ->"hello", 3, TimeUnit.SECONDS);
//按照间隔执行
service.scheduleAtFixedRate(() -> System.out.println("Hello World!"),
3, 1, TimeUnit.SECONDS);
//System.out.println("线程池剩余时间" + schedule.getDelay(TimeUnit.MILLISECONDS) / 1000.0 + "s");
//System.out.println(schedule.get());
service.shutdown();
}
线程池实现原理(下次再看)
并发工具类
CountDownLatch
这是一个可以在多线程里计数的一个工具类,先看使用例子
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(20); //创建一个初始值为20的计数器锁
for (int i = 0; i < 20; i++) {
int finalI = i;
new Thread(() -> {
try {
Thread.sleep((long) (2000 * new Random().nextDouble()));
System.out.println("子任务"+ finalI +"执行完成!");
} catch (InterruptedException e) {
e.printStackTrace();
}
latch.countDown(); //每执行一次计数器都会-1
}).start();
}
//开始等待所有的线程完成,当计数器为0时,恢复运行
latch.await(); //这个操作可以同时被多个线程执行,一起等待,这里只演示了一个
System.out.println("所有子任务都完成!任务完成!!!");
//注意这个计数器只能使用一次,用完只能重新创一个,没有重置的说法
}
通过调用await()来等待计数器衰减到0的时候再接着执行
再来简单看一下原理
-
首先是利用共享锁实现
-
在一开始的时候就是已经上了count层锁的状态,也就是
state = count -
await()加了共享锁,但是必须state为0才能加锁成功,否则按照AQS的机制,会进入等待队列阻塞,加锁成功后结束阻塞 -
countDown()结果上就是解1层锁,也就是靠这个把state的值减到0 -
共享锁是线程共享的,同一时刻能有多个线程拥有共享锁。
-
如果一个线程刚获取了共享锁,那么在其之后等待的线程也很有可能能够获取到锁,所以得传播下去继续尝试唤醒后面的结点,不像独占锁,独占的压根不需要考虑这些。
-
如果一个线程刚释放了锁,不管是独占锁还是共享锁,都需要唤醒后续等待结点的线程。
CyclicBarrier
好比一场游戏,我们必须等待房间内人数足够之后才能开始,并且游戏开始之后玩家需要同时进入游戏以保证公平性。
假如现在游戏房间内一共5人,但是游戏开始需要10人,所以我们必须等待剩下5人到来之后才能开始游戏,并且保证游戏开始时所有玩家都是同时进入
public static void main(String[] args) {
CyclicBarrier barrier = new CyclicBarrier(10, //创建一个初始值为10的循环屏障
() -> System.out.println("飞机马上就要起飞了,各位特种兵请准备!")); //人等够之后执行的任务
for (int i = 0; i < 10; i++) {
int finalI = i;
new Thread(() -> {
try {
Thread.sleep((long) (2000 * new Random().nextDouble()));
System.out.println("玩家 "+ finalI +" 进入房间进行等待... ("+barrier.getNumberWaiting()+"/10)");
barrier.await(); //调用await方法进行等待,直到等待的线程足够多为止
//开始游戏,所有玩家一起进入游戏
System.out.println("玩家 "+ finalI +" 进入游戏!");
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}).start();
}
}
我们可以看到,也是调用了await()方法,barrier就是一个调度中心,所有人都来这报道,等到barrier的容量满了就释放执行下面的语句
在调用reset()之后,处于等待状态下的线程,全部被中断并且抛出BrokenBarrierException异常,循环屏障等待线程数归零。那么要是处于等待状态下的线程被中断了呢?屏障的线程等待数量会不会自动减少?
当await()状态下的线程被中断,那么屏障会直接变成损坏状态,一旦屏障损坏,那么这一轮就无法再做任何等待操作了。只能进行reset()重置操作进行重置才能恢复正常。
-
CountDownLatch:
-
它只能使用一次,是一个一次性的工具
-
它是一个或多个线程用于等待其他线程完成的同步工具
-
-
CyclicBarrier
-
它可以反复使用,允许自动或手动重置计数
-
它是让一定数量的线程在同一时间开始运行的同步工具
-
Semaphore
信号量有n个许可证,多个线程来夺取,可以用来对某个数据做流量限制
public static void main(String[] args) throws InterruptedException {
Semaphore semaphore = new Semaphore(3); //只配置一个许可证,5个线程进行争抢,不内卷还想要许可证?
for (int i = 0; i < 5; i++)
new Thread(semaphore::acquireUninterruptibly).start(); //可以以不响应中断(主要是能简写一行,方便)
Thread.sleep(500);
System.out.println("剩余许可证数量:"+semaphore.availablePermits());
System.out.println("是否存在线程等待许可证:"+(semaphore.hasQueuedThreads() ? "是" : "否"));
System.out.println("等待许可证线程数量:"+semaphore.getQueueLength());
System.out.println("收回剩余许可数量:"+semaphore.drainPermits()); //直接回收掉剩余的许可证
}
Exchanger
线程间数据交换
public static void main(String[] args) throws InterruptedException {
Exchanger<String> exchanger = new Exchanger<>();
new Thread(() -> {
try {
System.out.println("收到主线程传递的交换数据:"+exchanger.exchange("AAAA"));
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
System.out.println("收到子线程传递的交换数据:"+exchanger.exchange("BBBB"));
}
Fork/Join框架
public class Main {
public static void main(String[] args) throws InterruptedException, ExecutionException {
ForkJoinPool pool = new ForkJoinPool();
System.out.println(pool.submit(new SubTask(1, 1000)).get());
}
//继承RecursiveTask,这样才可以作为一个任务,泛型就是计算结果类型
private static class SubTask extends RecursiveTask<Integer> {
private final int start; //比如我们要计算一个范围内所有数的和,那么就需要限定一下范围,这里用了两个int存放
private final int end;
public SubTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
if(end - start > 125) { //每个任务最多计算125个数的和,如果大于继续拆分,小于就可以开始算了
SubTask subTask1 = new SubTask(start, (end + start) / 2);
subTask1.fork(); //会继续划分子任务执行
SubTask subTask2 = new SubTask((end + start) / 2 + 1, end);
subTask2.fork(); //会继续划分子任务执行
return subTask1.join() + subTask2.join(); //越玩越有递归那味了
} else {
System.out.println(Thread.currentThread().getName()+" 开始计算 "+start+"-"+end+" 的值!");
int res = 0;
for (int i = start; i <= end; i++) {
res += i;
}
return res; //返回的结果会作为join的结果
}
}
}
}















 3045
3045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









