







也谈Quartz
Quartz是什么?google一下,你就知道^_^
在java开发领域,quartz基本就是开源的作业调度(或称定时任务)代名词。她可以与J2EE与J2SE应用程序相结合也可以单独使用。Quartz可以用来创建简单或为运行十个,百个, 甚至是好几万个Jobs这样复杂的日程序表。Jobs可以做成标准的Java组件或 EJBs。
前一段时间,因项目开发需要,采用她,事实证明这种选择是完全正确的。
刚开始用时,也是手忙脚乱,也不知从哪里下手,好在现在有互联网,下载《Quartz开发指南》,pdf格式的。
思路初步定下来:为避免采用quartz- 1.5.2 /docs/dbTables下数据表脚本创建大量数据表,自建trigger、job数据表。但后来证明这个思路本身就有问题,暂且不表。
按《指南》精神,若想持久化作业调度信息,就必须配置其自带quartz.properties,该文件默认配置把相关信息保存本地xml文件中,改为以下:
org.quartz.scheduler.instanceName = DefaultQuartzScheduler
#org.quartz.scheduler.instanceName = QuartzScheduler
#org.quartz.scheduler.instanceId = AUTO
org.quartz.scheduler.rmi.export = f al se
org.quartz.scheduler.rmi.proxy = f al se
org.quartz.scheduler.wrapJobExecutionInUserTransaction = f al se
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount = 1
org.quartz.threadPool.threadPriority = 5
org.quartz.threadPool.threadsInheritContextClassLoaderOfIniti al izingThread = true
org.quartz.jobStore.misfireThreshold = 60000
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.jobStore.useProperties = f al se
org.quartz.jobStore.dataSource = myDS
org.quartz.jobStore.tablePrefix = QRTZ_
org.quartz.jobStore.isClustered = f al se
org.quartz.dataSource.myDS.driver = oracle.jdbc.driver.OracleDriver
org.quartz.dataSource.myDS.URL = jdbc:oracle:thin:@127.0.0.1:1521:yp
org.quartz.dataSource.myDS.user = yp
org.quartz.dataSource.myDS.password = yp
org.quartz.dataSource.myDS.maxConnections = 5
org.quartz.plugin.triggHistory.class =org.quartz.plugins.history.LoggingTriggerHistoryPlugin
org.quartz.plugin.triggHistory.triggerFiredMessage = Trigger{1}.{0}firedjob{6}.{5}at:{4,date,HH:mm:ssMM/dd/yyyy}
org.quartz.plugin.triggHistory.triggerCompleteMessage = Trigger{1}.{0}completedfiringjob{6}.{5}at{4,date,HH:mm:ssMM/dd/yyyy}withresultingtriggerinstructioncode:{9}
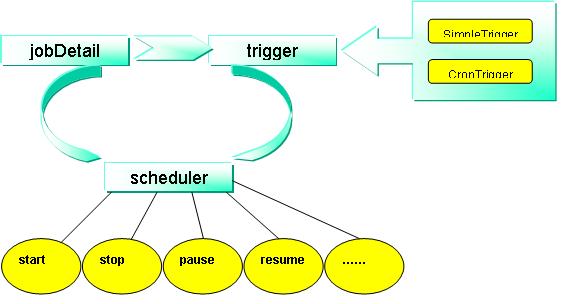
然后,按以下步骤运作: Quartz示意图
从上图可以看到有一个jobDetail,其实她就是你要指定的job信息及内容。该内容说白了就是让quartz具体做什么工作,假若一定要用一个词来概括jobDetail,那就是:what。quartz之所以被人到处称道,大概是因为她有一个很好的理念:分离工作本身定义和内容。
从上图可以看到trigger分SimpleTrigger和CronTrigger两种。前者简单定时器,只在某个时刻执行,或者,在某个时刻开始,然后按照某个时间间隔重复执行,值得一提的是结束时间属性优先级高于重复次数属性,我一般用她做测试,然后判断我定义的job有没有问题;后者就是功能强大cron表达式定时器。假若一定要用一个词来概括trigger,那就是:when。
从上图可以看到分别定义jobDetail和trigger,当然还要有一个容器把她们全包括进来,就是scheduler,有了她就可以安排任务了,她可以做很多高难度动作哟,比如start、stop等。假若一定要用一个词来概括scheduler,那就是:how。
按原来思路,当走到创建jobDetail时,就开始碰壁了,后来想想,碰壁也是正常的,干革命哪有一帆风顺的?!因为创建jobDetail时,你调用quartz的api,该api会自动把你自定义job信息存入其相应系统表内。这些系统表数据由其自身维护,不用你操心^_^
切,我还懒得操心,哈
但笔者使用过程中发现一个问题,采用simpletrigger,若作业调度全部完成后,该类trigger会自动删除。难道我辛辛苦苦创建的trigger,若执行完成再想执行同样调度,还要重新创建?此时我自己构建trigger数据表就派上用场了,我只要控制与quartz系统表基本一致就可以了。
刚开始,我还后悔,没参悟透彻quartz全部理念,自建一套quartz表结构,还要维护自建表与系统表中trigger状态一致性,好麻烦。
现在quartz系统表调度完成后自动删除,我自建那个trigger表中该信息并不删除,只要改变其状态就可以了。
若系统表发现已经有待创建的自建表jobDetail或trigger信息,会报错有冲突,怎么办?也好办呀,创建前先判断一下,若存在就不再创建;反之,就创建。
塞翁失马,焉知祸福。
闲话少说,以代码为证吧:
TestQuartz.java
package test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Loc al e;
import org.quartz.JobDetail;
import org.quartz.Scheduler;
import org.quartz.SchedulerFactory;
import org.quartz.SimpleTrigger;
import org.quartz.impl.StdSchedulerFactory;
/**
* 调度器测试
* @version 2.0 Apr 8, 2008
* @author 俞鹏
* @since JDK1.5
*/
public class TestQuartz {
private SchedulerFactory scheduleFactory = null;
public static void main(String[] args){
TestQuartz test = new TestQuartz();
try {
test.startSchedule();
}
catch (Exception e) {
e.printStackTrace();
}
}//end main
/**
* 调度
*/
public void startSchedule() throws Exception
{
//创建jotDetail,其中TestJob自定义job类
JobDetail jobDetail =
new JobDetail("testJob01", Scheduler.DEFAULT_GROUP, TestJob.class);
//结束时间
long end = System.currentTimeMillis() + 9000L ;
//创建简单触发器,执行2次,每1秒执行一次,到9秒后结束
SimpleTrigger trigger = new SimpleTrigger("testTrigger01",null,strToDate(" 2008 -06-17 10:27:00"),null,2,1000);
//CronTrigger trigger = new CronTrigger("trigger6", Scheduler.DEFAULT_GROUP, "0 0 0 ? * *");
//创建调度器,若其他没特别用途,用以下默认方式就可以
SchedulerFactory sf = new StdSchedulerFactory();
Scheduler scheduler = sf.getScheduler();
//加载jobDetail和trigger
scheduler.scheduleJob(jobDetail, trigger);
//调度器启动
scheduler.start();
}
}
TestJob.java(自定义job类)
package test;
import java.sql.Blob;
import java.sql.Clob;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.ResultSetMet aDa ta;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.Hashtable;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import org.quartz.JobDataMap;
import org.quartz.JobDetail;
import org.quartz.JobExecutionContext;
import org.quartz.SchedulerException;
import org.quartz.StatefulJob;
/**
* 自定义job
* @version 2.0 Apr 8, 2008
* @author 俞鹏
* @since JDK1.5
*/
public class TestJob implements Job{
// 覆盖execute方法
public void execute(JobExecutionContext context) {
// 每个Job都有独立的JobDetail
JobDetail jobDetail = context.getJobDetail();
// name在Job定义中指定
String jobName = jobDetail.getName();
// 每个Job都有一个Job Data map来存放扩展的信息
JobDataMap dataMap = jobDetail.getJobDataMap();
try {
//打印trigger状态,这个也可算本job另一功能吧
System.out.println("trigState:"+context.getScheduler().getTriggerState("testTrigger01", null));
} catch (SchedulerException e) {
e.printStackTrace();
}
//job实现功能
System.out.println("Hello World!!!");
}















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}