






Requests: 让 HTTP 服务人类
虽然Python的标准库中 urllib 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Humans”,说明使用更简洁方便。
Requests 继承了urllib的所有特性。Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的URL和 POST 数据自动编码。
安装requests:
pip3 install requests
GET请求
response = requests.get(“http://www.baidu.com/”)
也可以这么写
response = requests.request(
“get”,
“http://www.baidu.com/”
)
#请求参数分析
| :param method: | 设置请求方式 get、post、delete |
| :param url: | 目标url |
| param params | 跟的是get请求url地址后?后面拼接的参数 |
| param data | (optional) Dictionary, post请求的参数. |
| param headers | (optional) Dictionary 设置请求头. |
| param cookies: | (optional) Dict or CookieJar object 设置用户的cookies信息. |
| param files | (optional) Dictionary 文件上传(post). |
| param auth | Auth 认证. |
| param timeout | 设置请求的超时时间 |
| param allow_redirects | 设置是否允许重定向,默认是允许的 |
| param proxies | (optional) Dictionary 设置代理. |
param verify: (optional) Either a boolean, Defaults to True | .#忽略证书认证,则设置为False |
response的常用方法:
| response.text | 返回解码后的字符串 |
| respones.content | 以字节形式(二进制)返回。 |
| response.status_code | 响应状态码 |
| response.request.headers | 请求的请求头 |
| response.headers | 响应头 |
| response.encoding = ‘utf-8’ | 可以设置编码类型 |
| response.encoding | 获取当前的编码 |
| response.json() | 内置的JSON解码器,以json形式返回,前提返回的内容确保是json格式的,不然解析出错会抛异常 |
- 添加 headers 和 查询参数
如果想添加 headers,可以传入headers参数来增加请求头中的headers信息。如果要将参数放在url中传递,可以利用 params 参数。
import requests
kw = {‘wd’:‘长城’}
headers = {
“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36”
}
response = requests.get(
“http://www.baidu.com/s?”,
params = kw,
headers = headers
)
params 接收一个字典或者字符串的查询参数,
字典类型自动转换为url编码,不需要urlencode()
POST请求

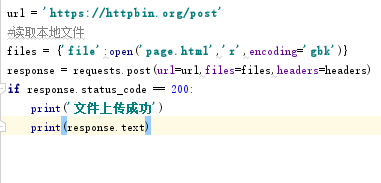
文件上传post请求
设置代理

cookie

session
在requests请求中,我们往往需要让上下请求保持联系,这时候需要用到session
实例化session对象
session = requests.session()
构建请求头
headers = {
‘User-Agent’:’…’
}
response = session.get(‘http://baidu.com/’,headers=headers)
print(response.headers)
print(session.cookies)
当session.cookies有用户信息后,再使用session.get()或者session.get()发起请求时就会自动携带cookies信息
XPath
什么是XPath?
*
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
什么是XML?
*
XML 指可扩展标记语言(EXtensible Markup Language)
*
XML 是一种标记语言,很类似 HTML
*
XML 的设计宗旨是传输数据,而非显示数据
*
XML 的标签需要我们自行定义。
*
XML 被设计为具有自我描述性。
*
XML 是 W3C 的推荐标准
区别
| 数据格式 | 描述 |
| XML | Extensible Markup Language (可扩展标记语言) |
| HTML | HyperText Markup Language (超文本标记语言) |
| HTML DOM | Document Object Model for HTML (文档对象模型) |
常用的路径表达式
| nodename | 选取此节点的所有子节点。 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性。 |
| //title //price | 选取文档中的所有 title 和 price 元素。 |
使用
from lxml import etree
| html = etree.HTML(html) | #构造一个Xpath解析对像,并且自动修正HTML文本 |
| text() | 获取标签文本 |
| @ | 属性名 获取标签属性值 |
| contains(@class,‘li’) | 属性多值匹配函数 |















 1634
1634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









