






作者:张政俊,中欧基金DBA
上次打了慢sql日志,发现有很多包含count逻辑的sql,周末抽空来梳理下mysql里的count。
一. count(*)的实现与执行
在mysql中,不同的存储引擎,count(*)的实现方式是不同的
Myisam:
Myisam会把表的行数存在磁盘上,每当执行count(*)的时候,直接返回就行了,所以速度非常快。
Innodb:
Innodb执行count(*)的时候,需要一条一条把数据从存储引擎里读出来,然后累计计数。
既然myisam的count这么快,为什么innodb不能基于myisam的原理也去把行数存起来呢?
主要还是因为 MVCC。
1. Innodb 引擎下的 count
MVCC限制了innodb存储引擎不可以记录行数。
假设同一时间有多个查询会话,test表共有100条数据:
| session A | session B | session C |
|---|---|---|
| begin; | ||
| select count(*) from test; | ||
| insert into test 插入一行 | ||
| begin; | ||
| insert into test 插入一行 | ||
| select count(*) from test;共100 | select count(*) from test;共101 | select count(*) from test;共102 |
可以看到在最后时刻,每个session拿到的总行数是不一样的。
mysql5.6后默认的隔离级别是RR(目前生产也是使用的RR),它是通过多版本并发机制实现的。在count的时候,每一行记录都要判断自己是否对这个会话可见,所以innodb只能把数据一行一行地读出来依次判断,如果判断为当前session可见行,那就把它加到统计的总行数上。
2. count(*) 执行计划
先模拟点数据,看看 count(*) 时mysql自身给出的执行计划
建表:
CREATE TABLE `count_test` (
`id` bigint NOT NULL AUTO_INCREMENT,
`var_col` varchar(300) NOT NULL,
`int_col` int(11) NOT NULL,
`insert_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `var_col` (`var_col`,`int_col`),
KEY `create_time` (`insert_time`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
存储过程插入数据:
CREATE PROCEDURE insert_person()
begin
declare i integer default 1;
while i<=200000 do
insert into count_test values(i, concat('var_col',i), i, date_sub(NOW(), interval i second));
set i=i+1;
end while;
end
call insert_count_test();
查看执行计划:
select count(*) from count_test;

可以看到,使用了 create_time 的普通索引。这里很多人会有疑惑,执行计划为什么不走主键呢?
3. count(*) 的内部优化
innodb是索引组织表,主键索引的叶子结点存放的是完整数据,普通索引叶子结点存放的是主键值。因此,普通索引要比主键索引小得多(除非全表所有列设为一个联合索引)。
在执行count(*)的时候,遍历哪个索引树得到的结果都是一样的,所以mysql优化器会去寻找最小的那颗树来遍历。
数据库系统设计的原则之一,就是在保证逻辑正确的前提下,尽量减少扫描的数据量。
4. rows 的计算
还有个地方可以很快地返回全表行数:
执行计划或者 show table status 命令会输出当前表的行数信息(rows),

这个语句结果返回非常非常快,不像是一张张表 count(*) 出来的。那这个rows是不是就是表的真实行数呢?
实际上它类似索引统计值,是通过采样来估算的,官方文档说误差有可能达到40%以上,所以这个不具备使用条件。
采样统计:innodb默认选择N个数据页,统计这些页上的不同值,得到一个平均值后,再乘以这个索引的页面数
5. 小结
Mysiam快,但是不支持事务,而且加上where条件判断后,就没了快的优势;
show table status 命令虽然返回很快,但是值不准确;
innodb直接count(*)会遍历全表,性能较差;
count(*) 函数调用时,是先要把表中数据加载到内存缓冲区,然后扫描全表获得行的总记录数。如果使用主键的话,innodb 先要读取所有20万数据到数据缓冲区,而且主键叶子结点存有所有字段的数据,这个操作需要消耗很多I/O。
而辅助索引,只保存index的值,不包含其他字段数据,I/O消耗要少很多,所以执行速度会更快。
二. Mysql 中各类的count
1. count(主键id)
innodb引擎会遍历全表,把每一行id都取出来,返回给server层,逐条累加。
2. count(1)
innodb引擎会遍历整张表,但是不取值,server层对于返回的每一行放一个数字“1”进去,逐行累加。
3.count(字段)
如果字段是not null ,一行行从记录里读出这个字段,逐行累加;
如果允许为null,取值的时候需要判断,不为null的,才累加;
4. 小结
因为count(*)是特殊优化过的,几个count性能排序如下:
count(*) 大于等于 count(1) 大于 count(主键id) 远大于 count(字段)
三. 优化count统计方案
我们再回过头来看下,有没有好一点的方案能解决innodb下count(*)慢的情况呢?优化思想应该还是通过存下该数据,需要的时候,可以快速响应。
方案一:缓存
想要快,用缓存。
比如用redis,当表中有数据插入式时,redis计数就加1,删除数据的时候,redis减1。
这种方案也是存在风险的:
1. 持久化风险:
redis是存在内存中,你可以使用rdb或者aof去持久化,如果刚插入条数据redis在内存中加1了,但是这是redis重启了,重新启动后redis加载的备份文件中没有新加的1,那这时候数据就不一致了。
当然上面的情况可以通过其他方式处理,就是需要额外考虑性能和成本,比如redis重启后,先去数据库里count一把,把它写回redis中。
2. 逻辑风险:
| session A | session B |
|---|---|
| 插入一条记录 | |
| 读取redis的计数,发现是100 | |
| redis计数加1 |
在并发系统里,无法精准控制不同线程的执行时间,如上图,即使redis正常工作,个别情况下计数的逻辑还有有点不够精准的。
方案二:数据库中保存
新建一张专门计数的表,专门存放表的计数数据。
这样即使数据库重启起码数据不会丢(redo log保证)。
| session A | session B |
|---|---|
| begin; | |
| 计数表记录加1 | |
| begin; | |
| 读取计数表,查到100条 | |
| commit; | |
| 插入一条数据 | |
| commit; |
session B 是独立的事务,因为session A没提交,所以计数表记录加1这个操作是对B不可见的。
通过数据库事务的特性,把执行时序的问题给解决掉。
方案三:其他数据库
其他数据库的话首推 clickhouse,之前测试ch时发现执行count(*)速度非常快,截一张当时的PPT:
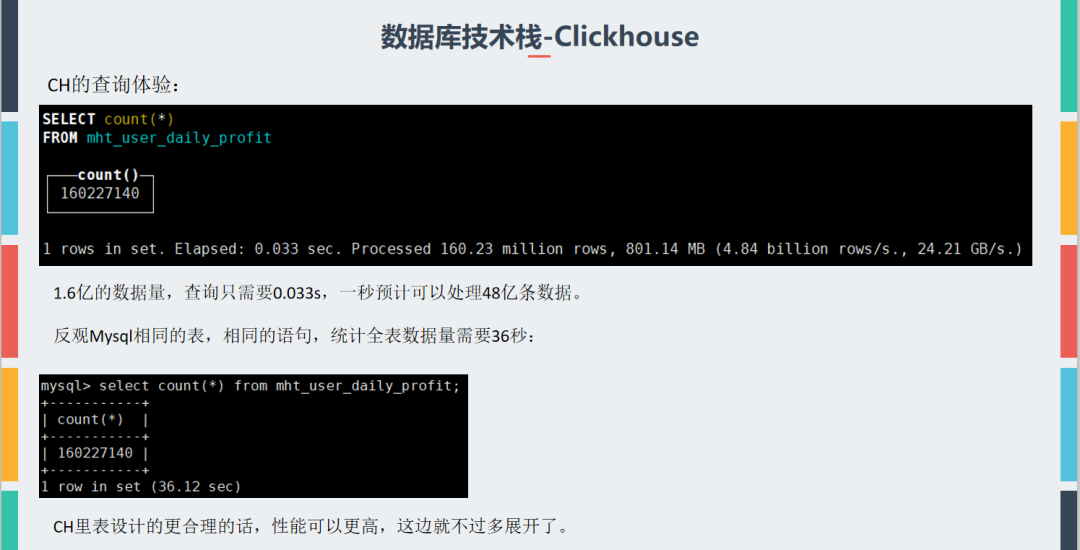
当然异构数据库最大的问题就是要解决增量同步。mysql 同步至 CH,目前大多数的方案是使用python工具,该方案还不成熟,相信随着时间推移会有更好的方案,届时很多 OLAP 或者 count(*) 业务都可以在 clickhouse 上进行。
小结
如果对行数这种实时性、响应性要求很高,而数据库本身也已无法满足,这时候才应该考虑去持久化计数。各种方案都是有利有弊,找到合适自己的才是最好的。
四. 关于查询成本
在测试count性能时,想到了select操作会涉及查询成本,于是特意把之前写的有关查询成本的内容贴了过来,希望可以帮到大家,也给自己做个知识点回顾。
执行计划
再额外看下mysql的查询成本,以一条sql为例:
SELECT
*
FROM
count_test
WHERE
var_col > 'var_co1123456'
AND insert_time < '2020-10-26 10:10:12'
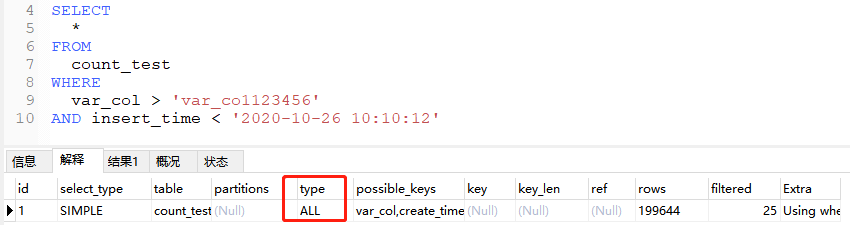
这条sql不出意外扫了全表,可能是由于用了 select * 需要回表,开销较大。接下来改成索引覆盖的形式。
索引覆盖:
SELECT
insert_time
FROM
count_test
WHERE
var_col > 'var_co1123456'
AND insert_time < '2020-10-26 10:10:12'
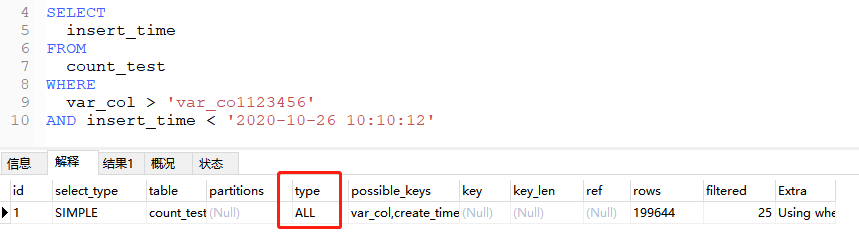
执行计划显示还是用了全表。
索引覆盖+强制索引:
使用 force index ,让它强制使用时间索引:
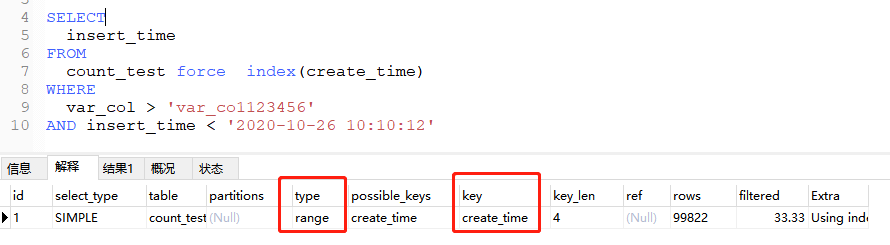
执行计划用到了时间索引。
查询成本核算
核算公式:
cost = rows*0.2 + data_length/(1024*16)
1. 全表查询成本

199644 * 0.2 + 9977856 / (1024 * 16) = 40,537.8
代入公式可以算出,全表的成本约为 40537.8
2. 各索引查询成本
通过 optimizer_trace 方式查看:
SET optimizer_trace="enabled=on";
SELECT insert_time FROM count_test WHERE var_col > 'var_co1123456' AND insert_time < '2020-10-26 10:10:12';
SELECT * FROM information_schema.OPTIMIZER_TRACE;
SET optimizer_trace="enabled=off";
然后看下走索引的预估成本:
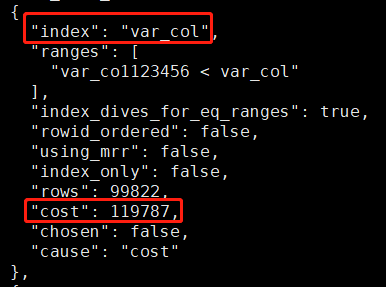
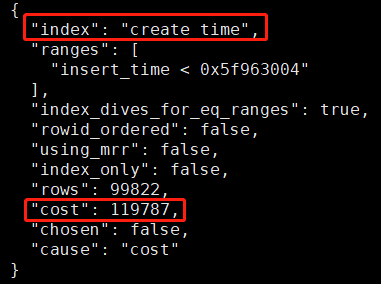
optimizer_trace 下全表查询的预估成本:
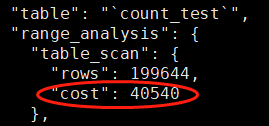
40540 和我们之前计算的 40537.8 差不多,这个值要远小于走索引的成本。
所以 mysql 在执行此 sql 的时候会使用全表扫描,都是基于执行成本来判断的。
全文完。
Enjoy MySQL :)















 2603
2603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









