






动态规划(dynamic programming)简称DP。
目录
一,重叠子问题、最优子结构
先看几个简单的问题:
1,斐波那契数列
1,1,2,3,5,8......
求第n项
int fac(int n)
{
if(n<3)return 1;
return fac(n-1)+fac(n-2);
}时间复杂度O (1.6 ^ n)
递归写法(备忘录法):
int ans[1000]={0};
int fac(int n)
{
if(n<3)return 1;
if(ans[n])return ans[n];
return ans[n]=fac(n-2)+fac(n-1);
}非递归写法:
int ans[1000]={0,1,1};
int fac(int n)
{
for(int i=3;i<=n;i++)ans[i]=ans[i-1]+ans[i-2];
return ans[n];
}递归写法不需要控制DP的计算顺序,非递归写法需要严格控制计算顺序。
读者可此处思考一下上述递归写法的实际计算顺序,假设编译器是默认先执行加法左边的,再执行加法右边的。
两种写法的时间复杂度都是O(n)
为什么差异这么大?
这就是DP的第一个重要特性:重叠子问题
2,求数列中位数
这个题,能不能像上一题这么做呢?
如果我用f(n)表示数列前n个数的中位数,那么,由f(n-1)和f(n-2)可以直接推导出f(n)吗?
不能!
差异在哪?差异在于问题本身的性质不同。
这种由子问题的答案可以直接推导出原问题答案的性质,其实就是最优子结构。
最优子结构:问题的最优解包含了子问题的最优解。
再来看看一个动态规划的题目,当我们分析它的时候,我们在想些什么?
3,数列的DP问题
一维
力扣 OJ 300. 最长上升子序列
力扣OJ 1218. 最长定差子序列
二维
力扣 OJ 1143. 最长公共子序列
CSU - 1060 Nearest Sequence (三个数组的最长公共子序列)
4,最短路问题
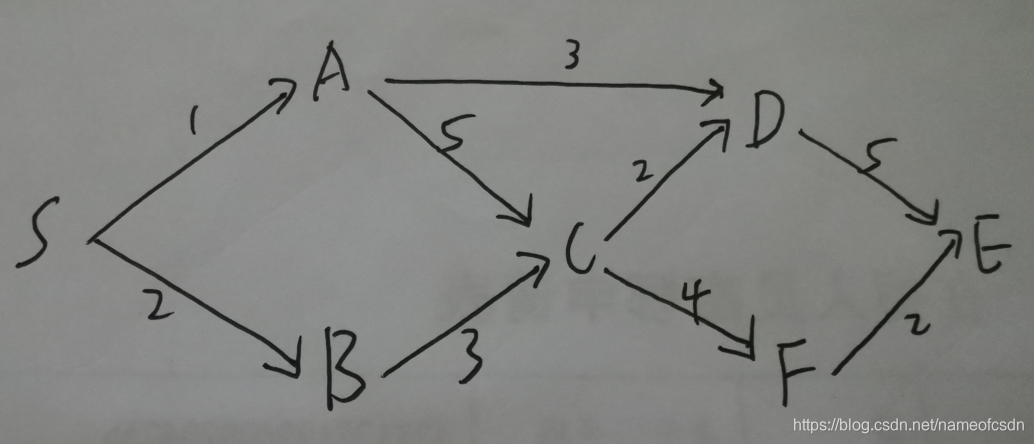
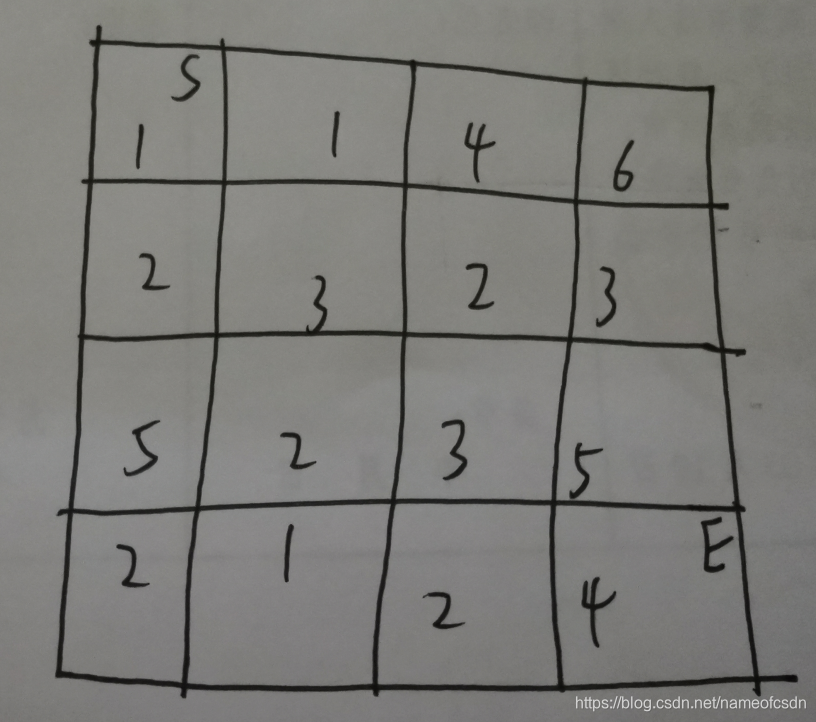
动态规划的题目,当我们分析它的时候,主要就是:
问题研究的对象、问题的子问题、最优子结构(即递推式)、解空间结构
递归写法和非递归写法其实都是解空间的遍历,而绝大部分问题的解空间都可以映射为树空间,树的遍历主要就是DFS和BFS,递归基本上就是DFS。
什么是解空间结构?
解空间就是问题可能的解组成的集合,根据问题的属性,空间的结构也有不同,有的是数组有的是树等等。
按照问题研究的对象类型和解空间结构,DP问题可以分为数列DP、区间DP、树形DP、数位DP、状态压缩DP、概率与期望DP、高维DP等等。
DP的更深用法:
空间压缩、时间优化
二,问题本身的固有属性决定数据结构和算法
1,数据结构
数据结构不仅取决于问题研究的对象本身的数据结构,也取决于在这个对象上,我们需要什么样的形式的一个答案。
例如:力扣OJ 740. 删除与获得点数
同样是数组,我们可以寻求很多种不同形式不同结构的答案。
常规的是一种基于顺序的,或者基于子序列的答案,而本题是基于数值的。
也就是说,我们访问了一个元素之后,要立即删除和他数值隔1的那些数,这个当然不能总靠暴力枚举了,
对于这样的一种形式的问题,我们的数据结构也就需要按照数值来排序,
而实现此目的的方式主要有两种,一种是基于数值的排序,比如快速排序,比如sort函数,一种是基于数值的排序,比如计数排序。
我在力扣OJ 740. 删除与获得点数 中使用的是计数,因为题目规定了每个数不超过10000
2,算法——指针滑动和动态规划
为什么力扣OJ 1248. 统计「优美子数组」是指针滑动,而力扣OJ 1218. 最长定差子序列 不是呢?
依然是由问题的形式决定的。
前者,连续 子数组中恰好有 k 个奇数数字,我们就认为这个子数组是「优美子数组」,这个题目探讨的对象是连续的一段,
后者,等差子序列是一种基于数值的定义,我们不知道能构成等差数列的下一个数在哪,我们只知道这个数是多少。
三,空间压缩
动态规划的空间压缩,本质上就是用时间取代空间的其中一维,使得空间复杂度降低,但时间复杂度不变。
具体来说,空间压缩就是,在同一个空间位置,不停刷新值,随着时间的推移,他的含义一直在变化,而他的值一直是对应他的含义。
首先举个最简单的例子感受一下:
求斐波那契数列的第1000项
int ans[1005]={0,1,1};
for(int i=3;i<=1000;i++)ans[i]=ans[i-1]+ans[i-2];时间复杂度和空间复杂度都是O(n)
而空间压缩的写法:
int a=1,b=1,c;
for(int i=3;i<=1000;i++)c=a+b,a=b,b=c;这里的a和b就是表示,在我们的计算过程中的斐波那契数列的最后两项的值,随着计算的不断进行,a和b到底是对应哪2个数是一直在变化的。
更常规的例子是二维或者二维以上的DP,使用空间压缩可以降低一个维度。
例如:
力扣 OJ 1223. 掷骰子模拟 力扣OJ(1001-1400)_nameofcsdn的博客-CSDN博客
HDU - 1244 Max Sum Plus Plus Plus 数列DP_nameofcsdn的博客-CSDN博客
CSU 1899: Yuelu Scenes 高维DP_nameofcsdn的博客-CSDN博客
四,问题的形式化描述
动态规划的核心在于分析最优子结构,其中包含如下内容:
如何描述问题,如何描述子问题,问题的解和子问题的解之间的关系,即递推式,问题的解空间结构,如何遍历这个解空间,等等。
问题的描述形式,取决于我们所求的答案的形式和结构.
个人理解主要分三种情形:
(1)完全按照题目所求来描述
(2)基于答案分解,附加特殊规则的精确化描述
(3)自带空间压缩的降维描述
对于问题本身的描述很复杂的题目,我们的描述越精确,我们的递推式也就越简洁。
例如:
(1)完全按照题目所求来描述
例1:力扣 OJ 1143. 最长公共子序列
f(a,b)表示数组A的前a个数和数组B的前b个数的最长公共子序列
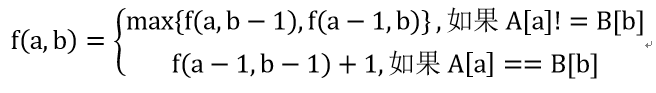
(2)基于答案分解,附加特殊规则的精确化描述
什么叫基于答案分解呢?
要求前n个数的最长上升子序列,我们可以把答案分解为n种情况:
以第i个数(i从1到n)为结尾的最长上升子序列
例2:力扣 OJ 300. 最长上升子序列
给定一个无序的整数数组,找到其中最长上升子序列的长度。
f(i)表示以第i个数结尾的最长上升子序列的长度
f(i-1)表示以第i-1个数结尾的最长上升子序列的长度
所以f(i)=max{f(j) | j<i && num[j]<num[i]}
例3:CSU 1225: ACM小组的队列(最长上升子序列的个数)
这个题目需要把以第i个数结尾的最长上升子序列的长度和数目一起算出来。
PS:完全按照题目所求来描述,求得的值就是答案,
基于答案分解,附加特殊规则的精确化描述,求得值之后,还要在所有值里面取一个最优解
PS:基于答案分解是根据答案的最后一个值,分解成很多情况,得到的是分解问题,形式和原问题不同
而子问题是形式和原问题相同,但规模比原问题小,是原问题经过分治思想得到的。
(3)自带空间压缩的降维描述
什么叫自带空间压缩的降维描述:
例4:力扣OJ 1218. 最长定差子序列
给定差值dif,求最长等差子序列
如果数组没有重复的数,那就简单,ans[arr[i]]=ans[arr[i]-dif]+1
如果有重复的数,那么相同的数如何选取?
自然是取第i个数之前,等于arr[i]-dif且ans值最大的那个,但是如果搜索的话就会超时,必须在O(1)的时间内找到这个数或者找到它的ans值。
所以我们除了需要知道ans[arr[i]]表示以第i个数结尾的最长等差子序列之外,还需要确定,ans[x]表示啥?
ans[x]=ans[arr[j]],其中j=max{j | arr[j]=x,j<i}
没错,这么一个精准的形式化描述,让我们意识到,ans[x]的含义中包含了i这个变量,也就是说ans数组的值的含义是随着时间一直在变化的,这其实是隐含了空间压缩。
五,二维DP
因为最近在写DP总结系列,所以选了一个二维DP的题目,把各种代码都写了一遍,并在此进一步探索。
力扣OJ 63. 不同路径 II (二维DP)力扣OJ(0001-100)-CSDN博客
这里面的4个代码,涉及到递归和非递归、非递归的不同顺序、空间压缩。
第一个问题来了,非递归写法有没有空间压缩写法呢?
以题目中的数据和我的递归算法为例
输入:
[
[0,0,0],
[0,1,0],
[0,0,0]
]
int dp(vector<vector<int>>& obs,int x,int y)
{
if(x<0||x>=obs.size()||y<0||y>=obs[0].size()||obs[x][y])return 0;
if(ans[x][y])return ans[x][y];
return ans[x][y]=dp(obs,x,y-1)+dp(obs,x-1,y);
}首先看看递归写法的调用过程:
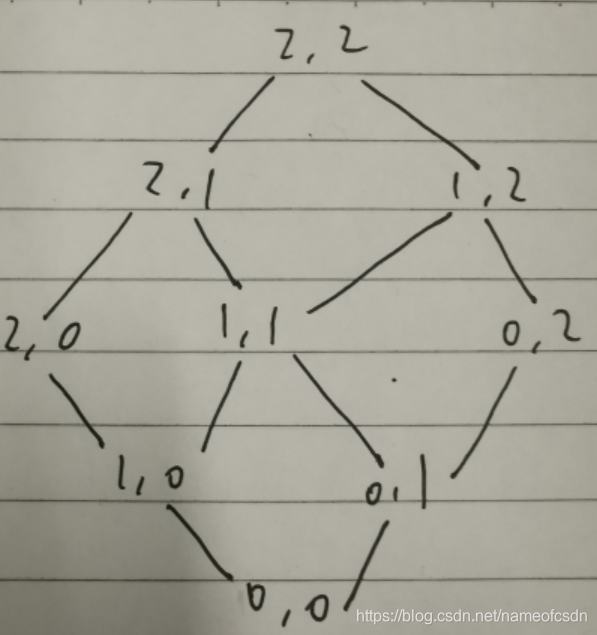
可以发现,这棵树其实是一个斜着的矩形,而这个矩形和输入的矩形obs是对应的。
然后,我们看看dp函数实际被调用的过程:
class Solution {
public:
vector<vector<int>>ans;
int dp(vector<vector<int>>& obs,int x,int y)
{
cout<<x<<" "<<y<<" ";
if(x<0||x>=obs.size()||y<0||y>=obs[0].size()||obs[x][y])return 0;
if(ans[x][y])return ans[x][y];
return ans[x][y]=dp(obs,x,y-1)+dp(obs,x-1,y);
}
int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {
ans=obstacleGrid;
for(int i=0;i<ans.size();i++)for(int j=0;j<ans[0].size();j++)ans[i][j]=0;
ans[0][0]=1;
return dp(obstacleGrid,obstacleGrid.size()-1,obstacleGrid[0].size()-1);
}
};
int main()
{
vector<int>v1;
v1.push_back(0);
v1.push_back(0);
v1.push_back(0);
vector<vector<int>>obs;
obs.push_back(v1);
obs.push_back(v1);
obs.push_back(v1);
obs[1][1]=1;
Solution s;
cout<<s.uniquePathsWithObstacles(obs);
return 0;
}输出:
2 2 2 1 2 0 2 -1 1 0 1 -1 0 0 1 1 1 2 1 1 0 2 0 1 0 0 -1 1 -1 2 2
把-1去掉,得到:
2 2 2 1 2 0 1 0 0 0 1 1 1 2 1 1 0 2 0 1 0 0
用同样的方法,如果输入的是
[
[0,0,0],
[0,1,0],
[0,0,0]
]
那么递归的实际执行过程就是
2 2 2 1 2 0 2 -1 1 0 1 -1 0 0 1 1 1 0 0 1 0 0 -1 1 1 2 1 1 0 2 0 1 -1 2 6
把-1去掉,得到:
2 2 2 1 2 0 1 0 0 0 1 1 1 0 0 1 0 0 1 2 1 1 0 2 0 1
不难看出来,这就是DFS
总结:
1,递归程序都是基于栈的。
2,DFS是基于栈的,BFS是基于队列的。
3,动态规划的问题,解空间都可以映射为树。
4,动态规划的递归程序,是对解空间的DFS。

















 8670
8670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









