







在C语言面试和考试中经常会遇到内存字节对齐的问题。今天就来对字节对齐的知识进行小结一下。
首先说说为什么要对齐。为了提高效率,计算机从内存中取数据是按照一个固定长度的。以32位机为例,它每次取32个位,也就是4个字节(每字节8个位,计算机基础知识,别说不知道)。字节对齐有什么好处?以int型数据为例,如果它在内存中存放的位置按4字节对齐,也就是说1个int的数据全部落在计算机一次取数的区间内,那么只需要取一次就可以了。如图a-1。如果不对齐,很不巧,这个int数据刚好跨越了取数的边界,这样就需要取两次才能把这个int的数据全部取到,这样效率也就降低了。
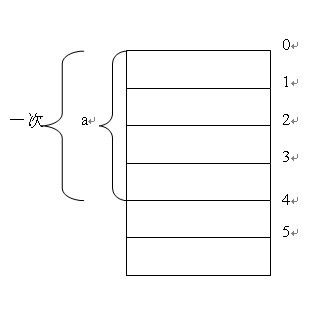
图:a-1

图:a-2
内存对齐是会浪费一些空间的。但是这种空间上得浪费却可以减少取数的时间。这是典型的一种以空间换时间的做法。空间与时间孰优孰略这个每个人都有自己的看法,但是C语言既然采取了这种以空间换时间的策略,就必然有它的道理。况且,在存储器越来越便宜的今天,这一点点的空间上的浪费就不算什么了。
需要说明的是,字节对齐不同的编译器可能会采用不同的优化策略,以下以GCC为例讲解结构体的对齐.
一、原则:
1.结构体内成员按自身按自身长度自对齐。
自身长度,如char=1,short=2,int=4,double=8,。所谓自对齐,指的是该成员的起始位置的内存地址必须是它自身长度的整数倍。如int只能以0,4,8这类的地址开始
2.结构体的总大小为结构体的有效对齐值的整数倍
结构体的有效对齐值的确定:
1)当未明确指定时,以结构体中最长的成员的长度为其有效值
2)当用#pragma pack(n)指定时,以n和结构体中最长的成员的长度中较小者为其值。
3)当用__attribute__ ((__packed__))指定长度时,强制按照此值为结构体的有效对齐值
二、例子
1。
struct AA{
char a;
int b;
char c;
}aa
结果,sizeof(aa)=12
何解?首先假设结构体内存起始地址为0,那么地址的分布如下
0 a
1
2
3
4 b
5 b
6 b
7 b
8 c
9
10
11
char的字对齐长度为1,所以可以在任何地址开始,但是,int自对齐长度为4,必须以4的倍数地址开始。所以,尽管1-3空着,但b也只能从4开始。再加上c后,整个结构体的总长度为9,结构体的有效对齐值为其中最大的成员即int的长度4,所以,结构体的大小向上扩展到12,即9-11的地址空着。
2.
struct AA{
char a;
char c;
int b;
}aa
sizeof(aa)=8,为什么呢
0 a
1 c
2
3
4 b
5 b
6 b
7 b
因为c为char类型,字对齐长度为1,所以可以有效的利用1-3间的空格。看见了吧,变量定义的位置的不同时有可能影响结构体的大小的哦!
3.
#pragma pack(2)
struct AA{
char a;
int b;
char c;
}aa
sizeof(aa)=10,为什么呢?a到c只占9字节长度,因为结构体的有效对齐长度在pack指定的2和int的4中取
较小的值2。故取2的倍数10。
如果当pack指定为8呢?那就仍然按4来对齐,结果仍然是12。
4.
struct AA{
char a;
int b;
char c;
}__attribute__((__8__))aa
sizeof(aa)=16,)
为咩?其实a到c仍然只占9字节长度,但结构体以8对齐,故取8的倍数16.
如果其指定2,则结果为10
如果pragma pack和__attribute__ 同时指定呢?以__attribute__ 的为准。
需要说明的是,不管pragma pack和__attribute__如何指定,结构体内部成员的自对齐仍然按照其自身的对齐值。
另外,不同的编译器可能会对内存的分布进行优化,
例如有些编译器会把立体1中的程序优化成例题2的样子。但这属于编译器的问题,
这里不做详细讨论。如果要作为编程的参考的话,最好当做编译器不会做优化,
尽量在保持代码清晰的情况下,自己手动将例题1优化成例题2的样子。
如果是做题的话,按照以上原则做就可以了,不用考虑不同编译器的特性。















 1630
1630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









