







# coding=utf-8
import urllib2
from bs4 import BeautifulSoup
import re
import requests
import urllib
'''
<li class="gl-item" data-sku="1026202803" data-spu="1026202802" data-pid="1026202802">
<div class="gl-i-wrap">
<div class="p-img">
<a target="_blank" title="金猴(JINHOU)牛皮三接头男鞋07正装军官三接头皮鞋系带校尉男士官功勋鞋军鞋21568 黑色 39码" href="https://ccc-x.jd.com/dsp/nc?ext=aHR0cHM6Ly9pdGVtLmpkLmNvbS8xMDI2MjAyODAzLmh0bWw&log=fxOM_ueHrW7UGKIZdVQEBBwEUutaU1JD26F1Frmd1O3zBGnoLgr5dJSgyE0Fav6foT2T4g7bCQfDM_iVxM6LfUw0bCN84wnT__cFd8rScJeAOlexYaAXF_za2WlBRBkHFi3uJjWaIT5WRv_5OVgGytEu9LmOGizgGoJaPxOTRwJPLpL88I9_XbcVCr8Jz7uZ45g8eDqfIk8MaArVJNyuVvQkhUPitvWB89WFMIMsBQEWnv4IkeK65oyanZnzCde8-EHhMRd4cZeLhAdhi5Pvl6FOZQLVRRHQPMMdh0Cd6Pvkya2r8uZOi9Fbh8U94llrrdwtBm3juf0A0ocbPD1LNc46Sqe5_Ag3mMrTAJry2qJBchLaLdbb29qiMiIp4bEPXhUCAbe5xfMy6qxI9qE67P9F0zIEGS-HQr5EMoo-JB2xCucdKk2bXZIWlyOChGA7&v=404" οnclick="searchlog(1,1026202803,2,2,'','adwClk=1')">
<img width="220" height="220" class="err-product" data-img="1" src="//img13.360buyimg.com/n7/jfs/t3931/298/1926721561/180248/cd5ff34e/589d7d3aNcd7d919c.jpg" />
</a> <div data-lease="" data-catid="6906" data-venid="37844" data-presale=""></div>
</div>
'''
def get_content(keyword):
contents = []
for page in range(0,12):
if page%2==0:
url = 'https://search.jd.com/Search?keyword={}&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E9%9E%8B&page={}&s=55&click=0'.format(keyword, page)
request = urllib2.Request(url)
response = urllib2.urlopen(request)
content = response.read()
response.close()
# print content
lists = re.findall(r'<div class="p-img">.*?</div>', content, re.S)
for li in lists:
tem = re.search(r'<img width.*?src|data-lazy-img="(.*?)"', li, re.S)
src1 = tem.group(1)
if isinstance(src1, str):
src1 = 'http:' + src1
contents.append(src1)
# print contents
#jsoncontent = json.dumps(contents, ensure_ascii=False, encoding='utf-8')
return contents
# 用图片url下载图片并保存成制定文件名
def downloadJPG(imgUrl, fileName):
urllib.urlretrieve(imgUrl, fileName)
# 批量下载图片,默认保存到当前目录下
def batchDownloadJPGs(imgUrls, path='F:/dog/'):#F:/picT/
# 用于给图片命名
count = 1
for url in imgUrls:
downloadJPG(url,''.join([path, '{0}.jpg'.format(count)])) #将多个路径组合
count = count + 1
# 封装:从网页下载图片
def download():
jpgs = get_content('柴犬') #可以输入不同的关键字,比如"鞋”
batchDownloadJPGs(jpgs)
def main():
download()
if __name__ == '__main__':
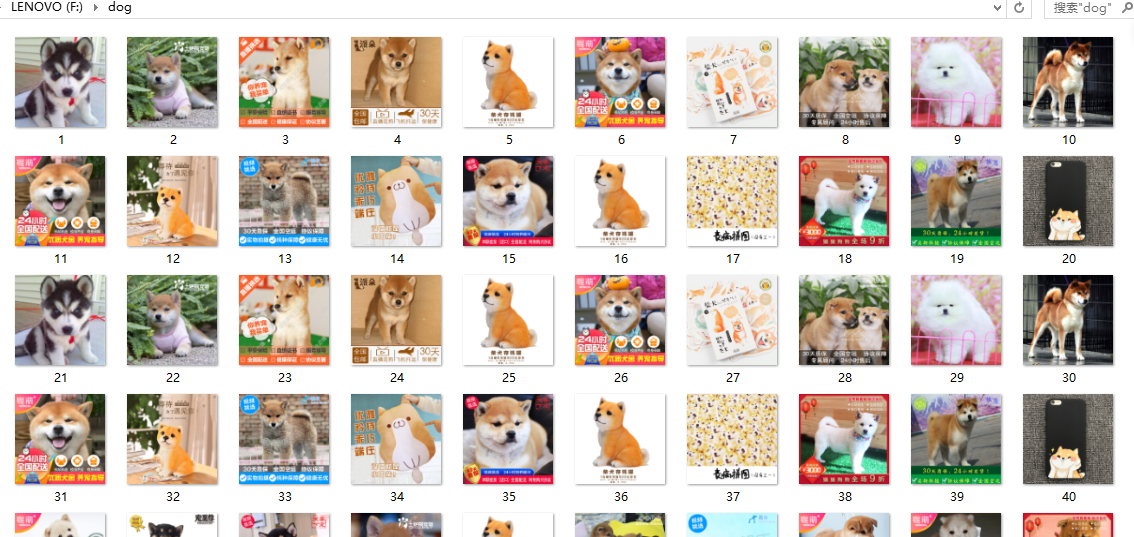
main()爬取结果截图:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









