







一.Memory
- Memory表引擎直接将数据保存在内存中,数据既不会被压缩也不会被格式转化,数据在内存中保存的形态与查询时看到的如出一辙,因此,当clickhouse服务重启时,Memory表内的数据会全部丢失,所以在一些场合,会将Memory作为测试表使用
- Memory表更为广泛的应用场景是在clickhouse的内部,它会作为集群间分发数据的存储载体来使用,列如在分布式IN查询的场合中,会利用Memory临时表保存IN子句的查询结果,并通过网络将它传输到远端节点
二.Set
- Set引擎是拥有物理存储的,数据首先会被写至内存,然后被同步到磁盘文件中,所以当服务重启时,它的数据不会丢失,当数据表被重新装载时,文件数据会再次别全量加载至内存
- 众所周知,在Set数据结构中,所有元素都是唯一的,Set表引擎具有去重的能力,在数据写入的过程中,重复的数据会被自动忽略,
- Set表引擎的使用场景既特殊又有限,他虽然支持正常的insert写入,但并不能直接使用select对其进行查询,Set表引擎只能间接作为IN查询的右侧条件被查询使用
Set表引擎的存储结构由两部分组成,它们分别是:
[num].bin数据文件:保存了所有列字段的数据,其中,num是一个自增id,从1开始,伴随着每一批数据的写入(每一次INSERT),都会生成一个新的.bin文件,num也会随之加1。tmp临时目录:数据文件首先会被写到这个目录,当一批数据写入完毕之后,数据文件会被移除此目录
create table tb_set(
id Int8,
name String
)engine=Set();
insert into tb_set values(1,'zs'),(1,'zs'),(1,'ls'),(2,'ww');
select * from tb_set;
Code: 48. DB::Exception: Received from localhost:9500. DB::Exception: Method read is not supported by storage Set. //不能直接查询表数据
[root@spark-140 dev]# cd /data/clickhouse/data/test1/tb_set/
[root@spark-140 tb_set]# ll
total 8
-rw-r----- 1 root root 65 Sep 2 09:47 1.bin
drwxr-x--- 2 root root 4096 Sep 2 09:47 tmp
正确的查询方法是将Set表引擎作为IN查询的右侧条件
create table tb_set_source(
id Int8,
name String,
age Int8
)engine=Log;
insert into tb_set_source values(1,'ls',12),(2,'ww',32),(3,'zl',31);
select * from tb_set_source where(id,name) in tb_set;
┌─id─┬─name─┬─age─┐
│ 1 │ ls │ 12 │
│ 2 │ ww │ 32 │
└────┴──────┴─────┘
注意:in的条件和表的字段一致三.Buffer
Buffer表引擎完全使用内存装载数据,不支持文件的持久化存储,所以当服务重启之后,表内的数据会被清空,Buffer表引擎不是为了面向查询场景而设计的,他的作用是充当缓冲区的角色。假设有这样一种场景,我们需要将数据写入目标MergeTree表A,由于写入的并发数很高,这可能会导致MergeTree表A的合并速度慢于写入速度(因为每一次insert都会生成一个新的分区目录)。此时,可以引入Buffer表来缓解这类问题,将Buffer表作为数据写入的缓冲区,数据首先被写入Buffer表,当满足预设条件时,Buffer表会自动将数据刷新到目标表
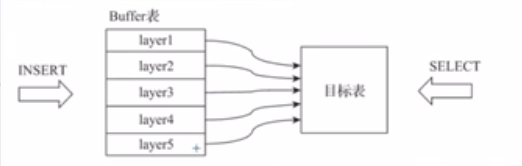
engine=Buffer(database,table,num_layers,min_time,max_time,min_rows,max_rows,min_bytes,max_bytes)其中参数可以分为基础参数和条件参数两类,首先说明基础参数的作用:
database:目标表的数据库table:目标表的名称,Buffer表内的数据会自动刷新到目标表num_layers:可以理解成线程数,Buffer表会按照num_layers的数量开启线程。以并行的方式将数据刷新到目标表,官方的建议设为16
Buffer表并不是实时刷新数据的,只存在阈值条件满足时它才会刷新,阈值条件由三组最小和最大值组成。接下来说明三组阈值条件参数的具体含义:
min_time和max_time:时间条件的最小和最大值,单位为秒,从第一次向表内写入数据的时候开始计算min_rows和max_rows:数据行条件的最小和最大值min_bytes和max_bytes:数据体量条件的最小和最大值,单位为字节
综上可知,Buffer表刷新的判断依据有三个,满足其中任意一个,Buffer表就会刷新数据,它们分别是:
- 如果三组条件中所有的最小阈值都已满足,则触发刷新动作
- 如果三组条件中至少有一个最大阈值条件满足,则触发刷新动作;
还有一点需要注意,上述三组条件在每一个num_layers中都是单独计算的,假设num_layers=16,则Buffer表最多会开启16个线程来响应数据的写入,它们 以轮询的方式接受请求,在每个线程内,会独立进行上述条件判断的过程
--创建一个目标表
create table tb_source1(
id UInt64
)engine=Log;
--创建一个缓存表
create table tb_source1_buffer as tb_source1
engine=Buffer(test1,tb_source1,16,10,100,2,5,10000000,100000000);
--向缓存表中插入数据
insert into tb_source1_buffer values(1),(2),(3),(4),(5);
--等待以后查看目标表中的数据
select * from tb_source1;
0 rows in set. Elapsed: 0.003 sec. //未触动刷新操作
insert into tb_source1_buffer values(6);
select * from tb_source1; //6被另一个线程处理了
┌─id─┐
│ 1 │
│ 2 │
│ 3 │
│ 4 │
│ 5 │
└────┘














 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









