







spark介绍
一.Spark概述
1.spark是什么
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
2.spark和Hadoop的区别
Hadoop
- Hadoop 是由 java 语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架
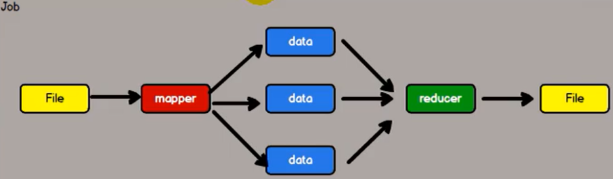
- 作为 Hadoop 分布式文件系统,HDFS 处于 Hadoop 生态圈的最下层,存储着所有的数据, 支持着 Hadoop 的所有服务。
- MapReduce 是一种编程模型, 作为 Hadoop的分布式计算模型,是 Hadoop 的核心。综合了 HDFS 的分布式存储和MapReduce 的分布式计算,Hadoop 在处理海量数据时,性能横向扩展变得非常容易。
- HBase 是一个基于HDFS 的分布式数据库,擅长实时地随机读/写超大规模数据集。它也是 Hadoop 非常重要的组件。
Spark
- Spark 是一种由 Scala 语言开发的快速、通用、可扩展的大数据分析引擎
- Spark Core 中提供了 Spark 最基础与最核心的功能
- Spark SQL 是Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用SQL 或者 Apache Hive
版本的 SQL 方言(HQL)来查询数据。 - Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
3.MR框架和spark框架如何选择
- Spark 就是在传统的MapReduce计算框架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的RDD算子模型。机器学习中ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。MR 这种模式不太合适,即使多MR 串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR 显然不擅长。
- Spark 所基于的 scala 语言擅长函数的处理。Spark是一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient DistributedDatasets),提供了比MapReduce 丰富的模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法。
- Spark 和Hadoop 的根本差异是多个作业之间的数据通信问题 : Spark 多个作业之间数据通信是基于内存,而Hadoop 是基于磁盘。Spark Task 的启动时间快。Spark 采用 fork 线程的方式,而 Hadoop采用创建新的进程的方式。Spark 只有在 shuffle 的时候将数据写入磁盘,而 Hadoop 中多个 MR作业之间的数据交互都要依赖于磁盘交互,Spark 的缓存机制比HDFS 的缓存机制高效。
- 在绝大多数的数据计算场景中,Spark 比 MapReduce 更有优势。但是Spark是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会由于内存资源不够导致 Job 执行失败,此时,MapReduce其实是一个更好的选择,所以 Spark 并不能完全替代 MR。
二.Spark核心模块
- Spark Core
Spark Core 中提供了 Spark 最基础与最核心的功能,Spark 其他的功能如:Spark SQL, Spark Streaming,GraphX, MLlib 都是在 Spark Core 的基础上进行扩展的 - Spark SQL
Spark SQL 是Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL 或者Apache Hive 版本的 SQL 方言(HQL)来查询数据。 - Spark Streaming
Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。 - Spark MLlib
MLlib 是 Spark 提供的一个机器学习算法库。MLlib 不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。 - Spark GraphX
GraphX 是 Spark 面向图计算提供的框架与算法库。
三.Spark运行环境
1.Local模式
所谓的Local 模式,就是不需要其他任何节点资源就可以在本地执行 Spark 代码的环境,一般用于教学,调试,演示等
2.Standalone模式
- local 本地模式毕竟只是用来进行练习演示的,真实工作中还是要将应用提交到对应的集群中去执行,这里我们来看看只使用 Spark自身节点运行的集群模式,也就是我们所谓的独立部署(Standalone)模式。Spark 的 Standalone模式体现了经典的master-slave 模式
- 配置高可用( HA),所谓的高可用是因为当前集群中的 Master节点只有一个,所以会存在单点故障问题。所以为了解决单点故障问题,需要在集群中配置多个 Master 节点,一旦处于活动状态的 Master发生故障时,由备用 Master 提供服务,保证作业可以继续执行。这里的高可用一般采用Zookeeper 设置
3.Yarn模式
独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark 主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成会更靠谱一些。所以Spark 在强大的Yarn 环境下工作(在国内工作中,Yarn 使用的非常多)。
4.K8S & Mesos 模式
Mesos 是Apache 下的开源分布式资源管理框架,它被称为是分布式系统的内核,在Twitter 得到广泛使用,管理着 Twitter 超过 30,0000 台服务器上的应用部署,但是在国内,依然使用着传统的Hadoop 大数据框架,所以国内使用 Mesos 框架的并不多,但是原理其实都差不多,这里我们就不做过多讲解了。

- 容器化部署是目前业界很流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是Kubernetes(k8s),而 Spark也在最近的版本中支持了k8s部署模式。这里我们也不做过多的讲解。给个链接大家自己感受一下:https://spark.apache.org/docs/latest/running-on-kubernetes.html
5.Windows模式
Spark 非常暖心地提供了可以在windows 系统下启动本地集群的方式
四.Spark端口号
- Spark 查看当前 Spark-shell 运行任务情况端口号:4040(计算)
- Spark Master 内部通信服务端口号:7077
- Standalone 模式下,Spark Master Web 端口号:8080(资源)
- Spark 历史服务器端口号:18080
- Hadoop YARN 任务运行情况查看端口号:8088















 8265
8265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









