







在数据库和大数据领域,TPC提供的基准测试数据集是做Benchmark的事实标准。常用且主要的TPC数据集有如下几种:
- TPC-C:模拟一个库存-订单系统以及其上的多用户并发事务;
- TPC-DI:模拟多种类型的大数据源的ETL过程;
- TPC-DS:模拟大型零售业务的系统,该系统主要用于BI和决策支持,数据量和OLAP查询复杂度都很高,是TPC数据集中最大的;
- TPC-E:模拟证券经纪人的系统,该系统主要用于提供大量查询的OLTP服务;
- TPC-H:可以近似视为TPC-DS的简化版本。
最近正在写一篇大数据领域SQL优化器(基于规则优化、基于代价优化)方面的文章,需要现成的基准数据来做支持,TPC正好符合这种需求。下面选择TPC-H来生成测试数据,并将其导入到Hive。
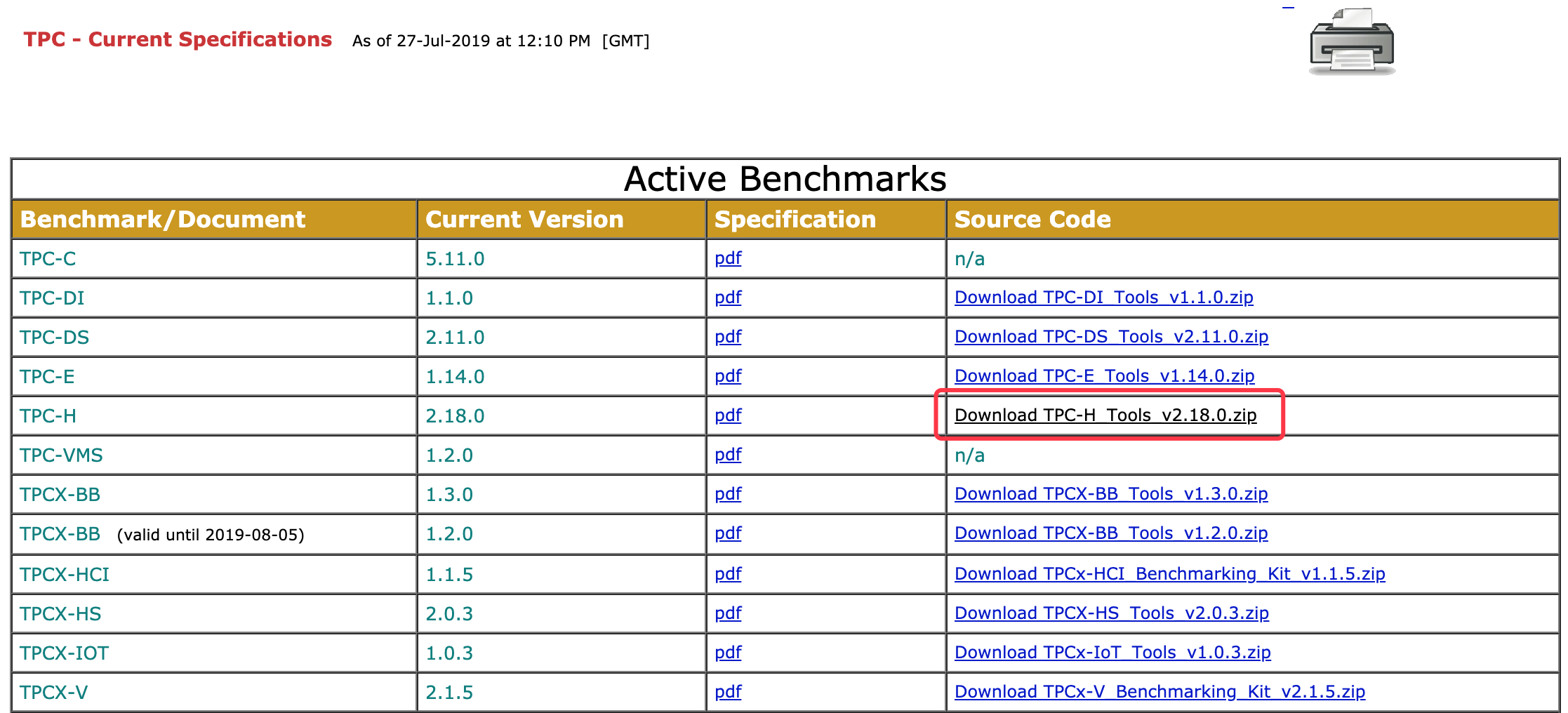
来到http://www.tpc.org/tpc_documents_current_versions/current_specifications.asp,其中列出了当前有效的TPC数据集文档以及源码。点击图中红框链接的TPC-H源码。
然后会要求填写包括邮箱在内的基本信息,点击captcha确认之后,下载链接会发送到邮箱,直接下载即可。注意有效期只有3个小时。
将其上传到服务器上空间比较充裕的分区,并解压之,然后修改其中的makefile文件。
~ cd /var/tpc-h/2.18.0_rc2/dbgen
~ cp makefile.suite makefile
~ vim makefile
################
## CHANGE NAME OF ANSI COMPILER HERE
################
CC = gcc
# Current values for DATABASE are: INFORMIX, DB2, TDAT (Teradata)
# SQLSERVER, SYBASE, ORACLE, VECTORWISE
# Current values for MACHINE are: ATT, DOS, HP, IBM, ICL, MVS,
# SGI, SUN, U2200, VMS, LINUX, WIN32
# Current values for WORKLOAD are: TPCH
DATABASE = SQLSERVER
MACHINE = LINUX
WORKLOAD = TPCH
如果机器上没有GCC的话,就另外安装。从上面的数据库支持列表可以看出并没有原生支持Hive,所以就得借助其他类型(比如SQL Server),再修改一下源码,将其对应的语句改成Hive风格的。
~ vim tpcd.h
#ifdef SQLSERVER
#define GEN_QUERY_PLAN "explain;"
#define START_TRAN "start transaction;\n"
#define END_TRAN "commit;\n"
#define SET_OUTPUT ""
#define SET_ROWCOUNT "limit %d;\m"
#define SET_DBASE "use %s;\n"
#endif
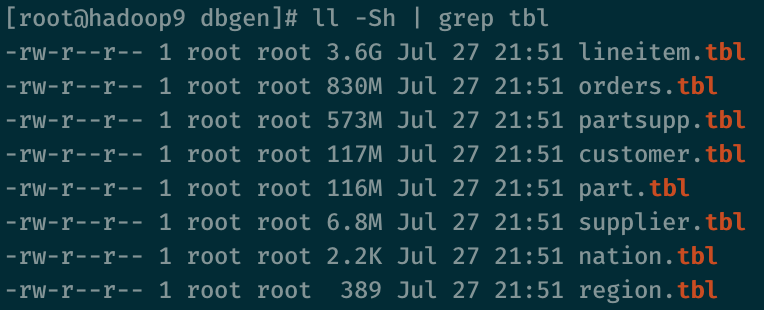
在该目录下执行make命令,再执行./dbgen -s 5命令,即可以生成测试数据。其中5代表数据大小为5个SF,可以视需要更改。SF为TPC中描述数据量的单位,1个SF约等于1GB(仅包含原始数据量,不包含索引等其他结构)。最终会生成8个扩展名为.tbl的文件,代表8张表的数据,如下图所示。
建表语句在dss.ddl文件中,但是它的格式与HiveQL不符,因此需要另外改写建表语句,如下所示。
create database tpch;
use tpch;
create external table lineitem (
l_orderkey int,
l_partkey int,
l_suppkey int,
l_linenumber int,
l_quantity double,
l_extendedprice double,
l_discount double,
l_tax double,
l_returnflag string,
l_linestatus string,
l_shipdate string,
l_commitdate string,
l_receiptdate string,
l_shipinstruct string,
l_shipmode string,
l_comment string)
row format delimited
fields terminated by '|'
stored as textfile
location '/tpch/lineitem';
create external table nation (
n_nationkey int,
n_name string,
n_regionkey int,
n_comment string)
row format delimited
fields terminated by '|'
stored as textfile
location '/tpch/nation';
create external table region (
r_regionkey int,
r_name string,
r_comment string)
row format delimited
fields terminated by '|'
stored as textfile
location '/tpch/region';
create external table part (
p_partkey int,
p_name string,
p_mfgr string,
p_brand string,
p_type string,
p_size int,
p_container string,
p_retailprice double,
p_comment string)
row format delimited
fields terminated by '|'
stored as textfile
location '/tpch/part';
create external table supplier (
s_suppkey int,
s_name string,
s_address string,
s_nationkey int,
s_phone string,
s_acctbal double,
s_comment string)
row format delimited
fields terminated by '|'
stored as textfile
location '/tpch/supplier';
create external table partsupp (
ps_partkey int,
ps_suppkey int,
ps_availqty int,
ps_supplycost double,
ps_comment string)
row format delimited
fields terminated by '|'
stored as textfile
location '/tpch/partsupp';
create external table customer (
c_custkey int,
c_name string,
c_address string,
c_nationkey int,
c_phone string,
c_acctbal double,
c_mktsegment string,
c_comment string)
row format delimited
fields terminated by '|'
stored as textfile
location '/tpch/customer';
create external table orders (
o_orderkey int,
o_custkey int,
o_orderstatus string,
o_totalprice double,
o_orderdate date,
o_orderpriority string,
o_clerk string,
o_shippriority int,
o_comment string)
row format delimited
fields terminated by '|'
stored as textfile
location '/tpch/orders';
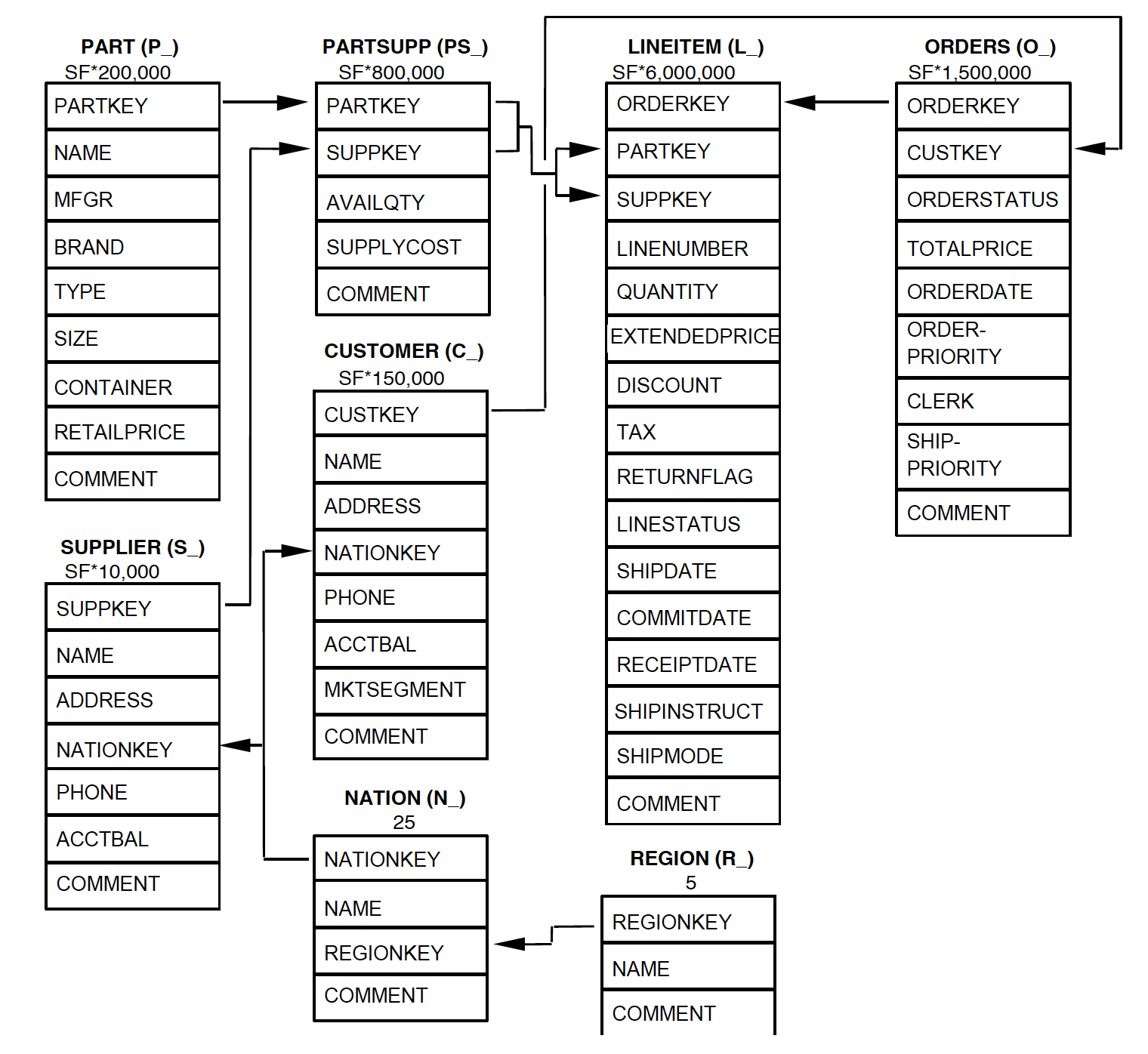
以上8个表的Schema如下图,其行数也是SF的倍数。
接下来就可以用load data语句导入数据了,以lineitem表为例。
load data local inpath '/var/tpc-h/2.18.0_rc2/dbgen/lineitem.tbl'
into table tpch.lineitem;
TPC-H一共有22条基准SQL查询,把它们都改写成Hive风格显然很费事。好在这件事已经有人做过了,见HIVE-600。下载其中的压缩包并解压,tpch文件夹中的文件即是。
关于这22条语句的具体分析,可以查看之前下载下来的压缩包中Specification文档,也可以参考中文版的分析。














 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









