







概述
FFS(Fast File System),诞生于80年代的一款文件系统,对其前任进行了大量的性能优化,成为了现代类unix文件系统的始祖,其很多设计思想在今天依然有借鉴意义。本篇文章中,我们会详细阐述FFS的设计思想,剖析它的优化策略,并考量这些策略背后的利弊。
设计思想
提高block大小
FFS之前的文件系统块大小基本定义为512或1024 byte,该方案利弊:
-
优势:降低block内的碎片率,提高存储空间利用率;
-
劣势1:数据传输以block为单位,block较小可能导致传输速率的低下,此时寻道时间占据更大的比重,进一步恶化磁盘的IO效率;
-
劣势2:由于古老文件系统采用了直接+N级间接索引来定位文件数据块,较小的block大小可能导致需要的索引块更多,降低文件IO效率。
在文件普遍偏小的当时,采用较小块劣势没那么明显。但是随着应用发生变化,大文件场景越来愈多,如果采用更大的block,那么其优劣势正好与较小的块大小互换。明显地提升磁盘IO效率的同时可能也会带来较大的空间浪费(block内碎片)。
FFS激进地提升了文件系统块大小至4096字节,且block size可作为参数写入文件系统超级块。即意味着,块大小可定制,一般是4096乘以2的N次方,但该参数一旦固定,便不可再修改,除非重新格式化磁盘。
我们前面说,提升文件系统块大小的一大劣势是block内的碎片问题。那能不能在提升block大小的同时兼顾这个问题呢?
FFS给出的答案是通过将block再划分成更细粒度的fragment来解决时间和空间矛盾。fragment大小也可定制,记录在超级块。如典型的4096 byte的block配合1024 byte的fragment,每个block内部被划分为4个fragment。

设计者这么做的想法很简单:
将文件数据尽量集中在一个块内,增强数据连续性;同时尽量利用块内的所有存储空间。
采用该方案,分配的粒度便可以细化至fragment。应用程序执行一次追加写,磁盘块分配算法复杂程度上升:
如果当前block/fragment内尚有足够空间执行本次追加写,则写入当前block/fragment
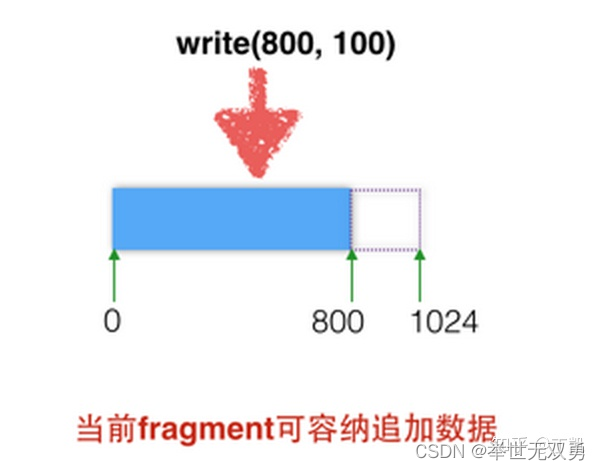
如果当前block内剩余空间不足以容纳所有的数据(也许可以写入一部分),那么先写入可容纳部分的数据,再判断剩下数据量,如果超过一个block,则分配一个block,如果不超过一个block,则找到空闲fragment符合大小的block并分配;

如果当前文件只包含一个或者多个fragment,那么判断其加上当前要写入的数据量是否超过1个block,如果超过,则分配一个新的block,将文件原有位于fragment的数据拷贝至新block,再执行写入。
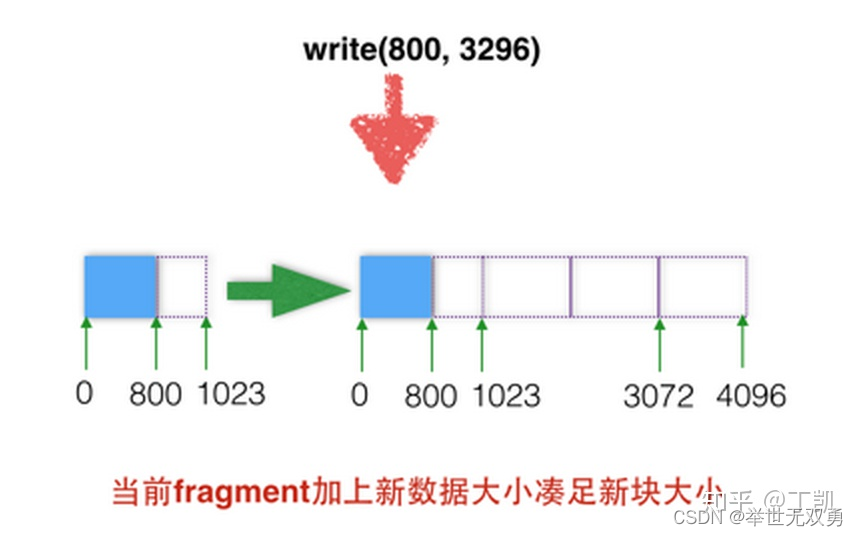
但是这么做也有其弊端,可能产生数据拷贝。
上面的第三种情况,为了将文件数据尽量存储与一个block内,不得不将已有的位于fragment内的数据copy至新的block。尤其是在上层应用程序每次只写少量数据时,FFS可能只会为其分配一个fragment,下次在写可能需要将上次分配的fragment内的数据搬移至新分配的block内,此时IO效率可想而知。
解决该问题的办法是控制数据发起层:在该层合并小写请求,聚集成大的请求再写入文件系统,最好按照块大小发起写请求。
cyclinder group
FFS将整个磁盘/磁盘分区划分成多个称为cylinder group的区域。每个cylinder group由多个连续的cylinder组成。cylinder的物理结构如下图所示:
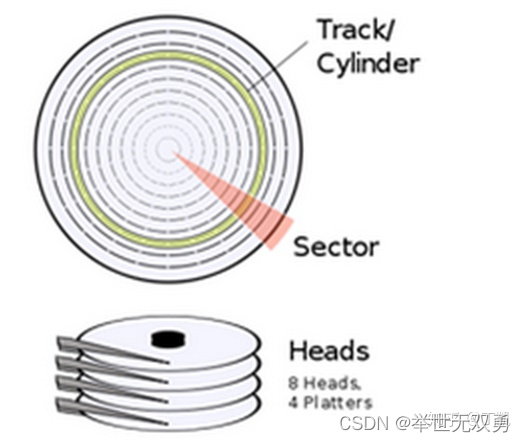
cylinder的特点是在多个cylinder之间切换只需切换磁头而已,无需机械运动,这对于我们后面组织数据,提升数据IO效率有较大帮助。
每个cylinder group看成是一个独立的逻辑单元,每个cylinder内部由super block副本、inode区、block bitmap区以及block组成,如下图:
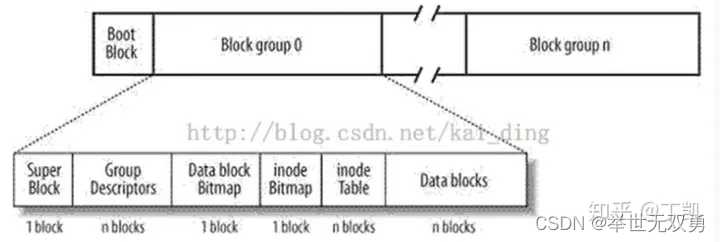
我们下面会看到为什么创造者要如此苦心孤诣地弄出这么一个结构。
数据分布
数据分布策略定义文件数据以及元数据如何存放在磁盘上,这对文件系统的IO性能有着决定性影响。由于机械磁盘的物理特性,所有的文件系统都在苦心孤诣地追求同一个目标:任何情况下的顺序IO,但理想很丰满,现实很骨感,我们只能尽可能向该理想奋斗。目前文件系统在磁盘存储的信息包括:
文件目录项:文件名至inode号的映射文件inode:记录文件属性(如大小、创建时间等)以及文件数据块位置文件数据块:存储文件数据。
一次典型的文件读取包括:
从磁盘读取文件目录项;
从磁盘读取文件inode;
从磁盘读取数据块。
最差情况下可能得经历3次IO,如果是随机IO,会导致文件访问效率急剧下降。为了将文件读取的随机IO变成顺序IO,我们就要尽可能地将文件的元数据(目录项、inode)以及数据块连续存放。在FFS内:
-
将磁盘划分成Cylinder group,这个我们在前面描述过。文件的数据和元数据尽量位于相同group存放;
-
创建文件时,将文件inode与其父目录的inode位于同一个cylinder group,这样对父目录进行ls时可提高效率;
-
创建目录时选择inode策略与创建inode不同:选择一个空闲inode数高于平均值且目录数最少的group。这样做可以使得目录被spread over到所有的cylinder group;
-
数据块分配时,对于低于阈值(48KB)的文件,其block分配在与文件inode相同的cylinder group,以后每涨1MB切换一个cylinder group。选择新cylinder group的准则是其拥有空闲block数量高于平均值。
在具体数据block分配时,block分配routine会给出一个参考block(当然是与文件前一个block连续的block),但是该参考block可能并非是free。因此,在这种情况下我们只好进行寻找:
-
寻找同一个cylinder内的下一个block;
-
如果cylinder已经无可用block,则在同一个cylinder group内继续寻找;
-
如果cylinder group也已经耗尽了所有的block,根据hash算法寻找下一个cylinder group;如果3的hash也失败,那么只能逐一查询所有的cylinder group来查找合适的block。
我们后面会说到,ext2的block分配算法基本就是来自FFS。
这种分布算法带来的优势:
- 文件尽量打散:因为目录被存放在不同的cylinder group;
- 元数据和数据位于相同cylinder group,寻道时间更短;
- 数据块尽量连续,一次寻道可进行大量数据传输。
总结
FFS总结了前任系统的优缺点,针对前任的缺点提出更加高效解决方案,较好地解决了文件系统的IO效率低下问题,属于现代文件系统的开山之作。

















 2667
2667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









