







 文章介绍了Starmie,一个数据湖中的数据集发现框架,通过无监督学习和KB辅助,进行列语义计算和关系联合搜索。文章还探讨了两种KB解决方案,以及SANTOS的实现,包括预处理、查询阶段和时间复杂度分析。
文章介绍了Starmie,一个数据湖中的数据集发现框架,通过无监督学习和KB辅助,进行列语义计算和关系联合搜索。文章还探讨了两种KB解决方案,以及SANTOS的实现,包括预处理、查询阶段和时间复杂度分析。
摘要
主要工作:提出了Starmie是一个端到端的数据湖中的数据集发现框架,以表可union搜索作为主要用例。
列的语义计算:以无监督的形式利用对比学习来在预训练语言模型的基础上训练列编码器,使用该列编码其能够捕获丰富的表内语义信息。
计算相似度:利用列嵌入向量的cos相似度来作为列的可union分数,同时提出了过滤、验证框架,能够有根据行的郧西探索很多的可union的设计。
特殊索引:HNSW
一. 介绍
贡献
语义表联合搜索新定义
KB解决方案。使用知识库(KB),以确定列和关系语义。为每张表构建语义图,表的节点是列,边是在KB中找到的二元关系
合成KB解决方案
- 使用数据湖本身来确定一组列是否具有相同或相似的语义,使用数据湖本身来确定一组列是否具有相同或相似的语义来判断
实证评价
- 两个解决方案旨在配合使用,以补偿仅部分覆盖数据湖的KB。
- 解决方案优于SOTA表联盟基线
基准。我们开发(并公开分享)三个新的关系联盟基准。
- 首先,我们重用了TUS基准的一部分[33],并将其标记为关系语义。
- 在第二种情况下,我们使用真实的开放数据表和查询,并标记一个groundtruth。
- 第三个是一个更大的数据湖,它有开放的数据表和查询,我们只标记我们的技术或基线技术返回的查询结果。因此,这个更大的基准可以用来评估精度和效率,但不能评估召回率。
三. 关系可连接性
列语义
语义标注、列类型发现[19,34,46]
给每一个列一组语义标注,标注可以是KB中的类型,或者当使用无监督技术时,会找到一组相同的但是未知标注的列。
由于发现过程是不确定的,因此每个标注会有一个置信分数
定义3 列语义:每一个列都有一个列语义CS©,是一组标注,每个标注都定义了一个是这个列所属的概念域,并且有一个0-1的置信分数。
- 例子:CS(公园名称)={地点、旅游景点、公园}
定义5 关系语义:使用表格两列之间的二元关系(不需要是一个函数),没一对列有一组关系,每个关系都有一个置信分数。
- 例如:Film Title和Film Director之间的DirectedBy
- 可以使用KB来给一对列分配已知关系,或者我们也可以使用无监督技术来看是否两对列对有相同但是未知的关系
- RS(c1,c2)一张表中的每一对列之间的有一个关系语义,是一组标注,每一个都表示表中这两列之间的关系,每个标注都有一个置信分数0-1
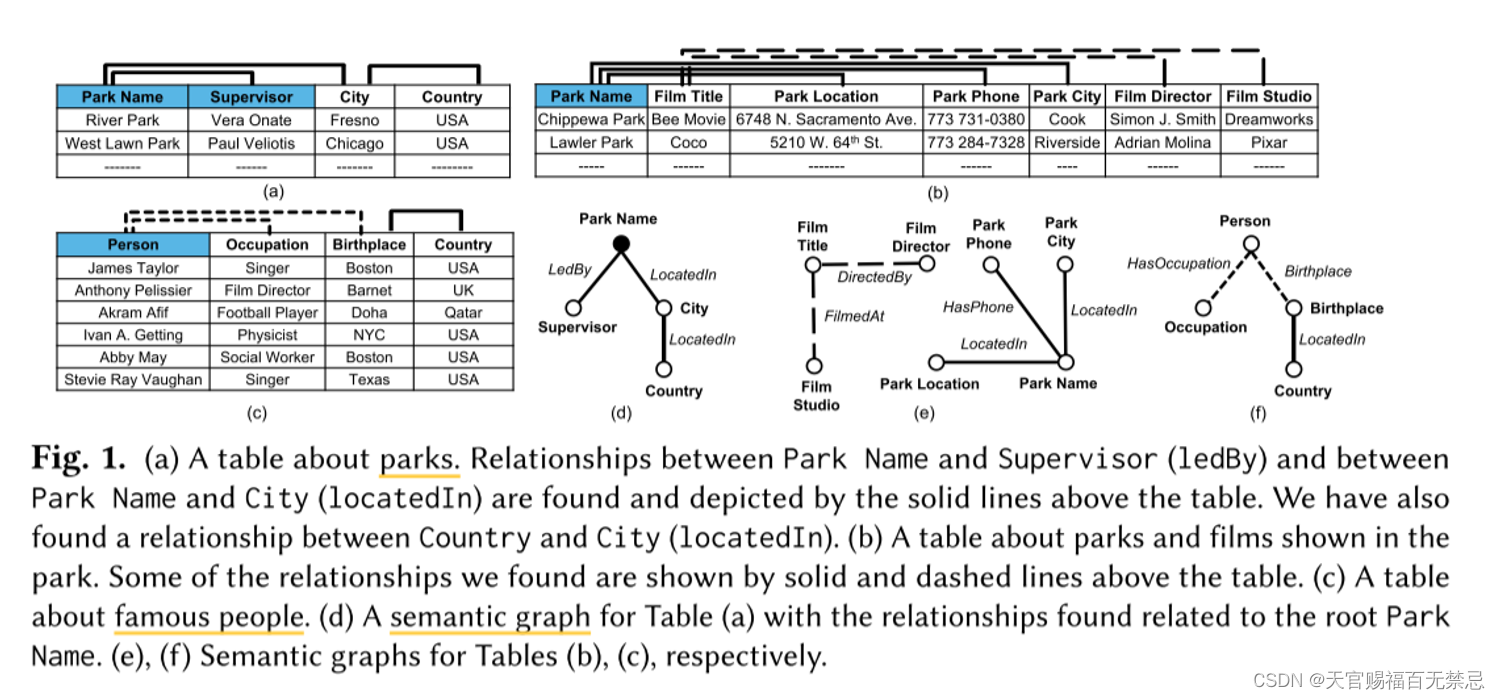
定义7 语义图:关系的表示方法1)表示为三元组(Subject、Predicate、Object),2)图中的边。
- 每个列ci都有一个不同的顶点vi,表T用语义图SG(T)=(V,E)来表示,对每一个列对(ci,cj)如果有非空的关系,则有一条边
- 本文中采用语义图的方法,语义图可能是不相连的 SG(T) 表格T的语义图
语义图上的可连接性搜索:用户提供查询表Q,并给出意图列(用I表示)。
- 为查询表创建一个语义图,该表被限制为以intent列为根的树,称为查询语义树
- 为数据湖中的所有表都构建语义图
- 更具体地说,在每个数据湖中的表所对应的语义图中匹配以intent列为根的查询树的子树
- 我们假设一个评分函数,它考虑列和关系匹配的强度以及查询树的匹配程度。
- 在搜索的过程中,找的那些表需要包含一个和意图列比较类似的列,有一些其它的列关系和这个意图列和其它列之间的关系比较接近。
- 在每一个语义图中找树(需要能够包含意图列),使得它能够匹配查询树的子树(根为意图列)
语义图匹配评分函数S,会对于每一个候选表返回一颗最高的评分子树,以及评分。
- 两种方法来创建语义图:使用现有KB的系统,用于数据湖上没有或部分KB覆盖时创建语义图(如企业和开放数据湖常见的那样)。
语义图
关系的表示形式(Subject,Predicate,Object)三元组 or 图上的边。
每个列是一个节点,如果两个列之间的关系RS(c1,c2)非空,则在图上画一条边
语义图上的可连接性搜索
给定数据湖表集合t,查询表Q和意图列I
- SANTOS首先会创建给查询表创建一个语义图(以意图类作为根节点→ 查询语义树)
- 接着找到在查询表中,意图列到其它列之间的关系,基于此来分析候选表(必须包含意图列的相似列)
- 这样可以让用户来限制itu列
- 即在数据湖的每个表生成的语义图中,找到一颗树,它能够与查询语义树中以意图列为跟的树想匹配
- 语义图匹配和打分函数S,对每一个表格,都可以返回一个最高的匹配
- 打分函数:考虑列的强度和关系匹配以及有多少拆卸念书被匹配
SANTOS Top-K搜素解决方案
给出了语义匹配、评分函数,对每一个数据湖中的表会返回一个T中评分最高的子树(与SG(Q)所匹配),并给出分数。
SANTOS能够找出前面K个表
四、使用KB来创建语义图
由于元数据缺失,只使用cell的值来计算
4.1 列语义
我们使用KB类型和类型层次来定义CS,因为可能存在与不同粒度级别的查询表匹配的表。
用一组类型来注释。
SANTOS可以使用的知识库
- 本文使用的YAGO
-
KB根目录是一个泛型类型,用作CS的一部分时没有任何信息。
-
利用已有的KB来确定各个列的语义标签
-
(将KB的根节点的子节点作为所有的顶层节点
对于每一列,判断其值属于KB的哪一个节点,并将其和其所有祖先节点都放入到该列的候选标签集合中,最后如果候选标签结合中包含了一种以上的顶层节点,则要删除)
-
列语义(CS,column semantics)
给每一列分配一组KB类型
- 使用KB类型和类型层级来定义CS(可能会有在不同层级上与查询表相匹配的表)
- 每一个列给不同维度的CStype标签,来适应不同的查询,查询的时候会根据查询表的CS来选择具体的某一个
- 利用KB类型层级来确保语义一致性,只将有ISA关系的标注给列标注
- 列语义构建步骤
- 1、构建候选列语义:将value放在KB中找可能的,对于每一列,判断其值属于KB的哪一个节点,并将其和其所有祖先节点都放入到该列的候选标签集合中
- 2、确定列语义:最后如果候选标签结合中包含了一种以上的顶层节点,则要删除)
4.2 列语义自信:
通过取频率分数(fs)和粒度分数(gs)的乘积为每种类型分配置信度分数
考虑到有一些type会被频繁使用
-
fs频率分数
- 频率分数:某一个type的频率分数=该列中所有映射到该type的唯一值的个数/该列中所有映射到该KB的唯一值的个数
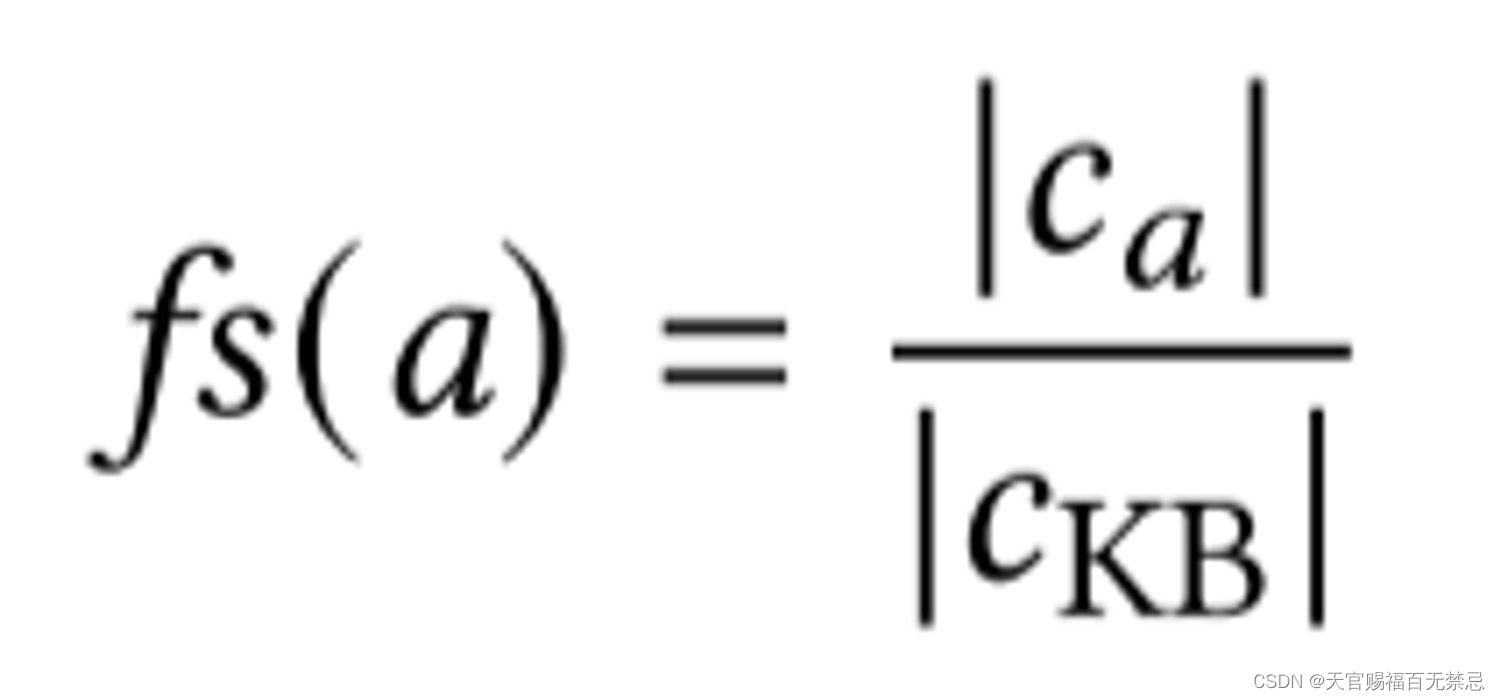
- 频率分数:某一个type的频率分数=该列中所有映射到该type的唯一值的个数/该列中所有映射到该KB的唯一值的个数
-
gs粒度分数
- 由于不同粒度的类型本来出现的概率就不同,对于高层的类型会频繁的出现,因此需要惩罚这些类型,利用它们的统计数据
- 基于所有匹配到type a实体的个数来进行统计(即在知识库中的)
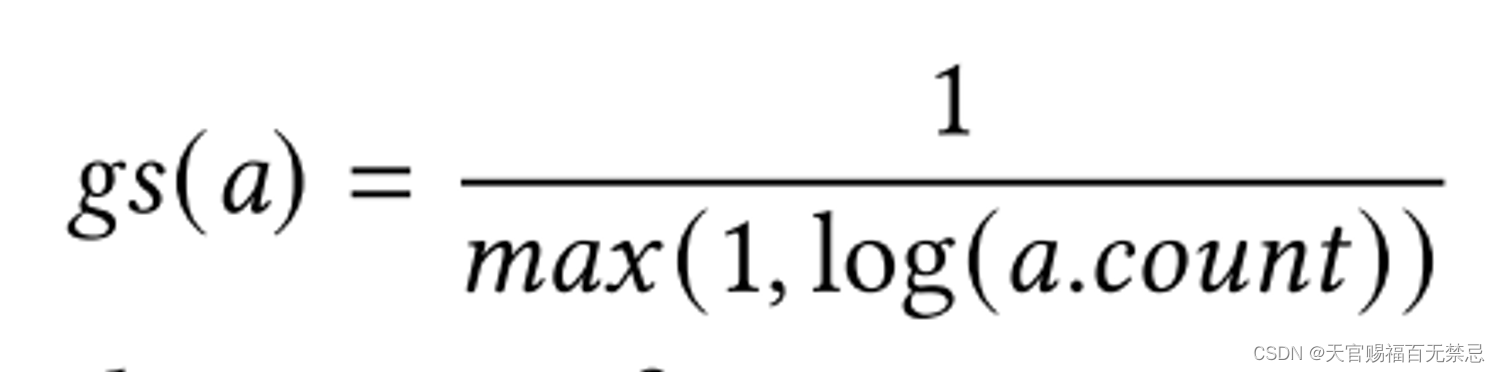
对照TF-IDF计算(考虑出现频率和特殊性)
- tf(术语的出现频率)→ fs
- idf(特殊性和稀缺性)→ gs
考虑信息理论:
- 理论上越高层级的类有更高的频率分数
- 根据信息理论,更小概率的结果展现了更多的信息→ 出现频率更高的类型展现了更少的信息
- 为了惩罚更频繁出现的,求了gs(a)
基于gs和fs计算列语义自信
- 对于标注为a的列c,KB列语义自信分数为
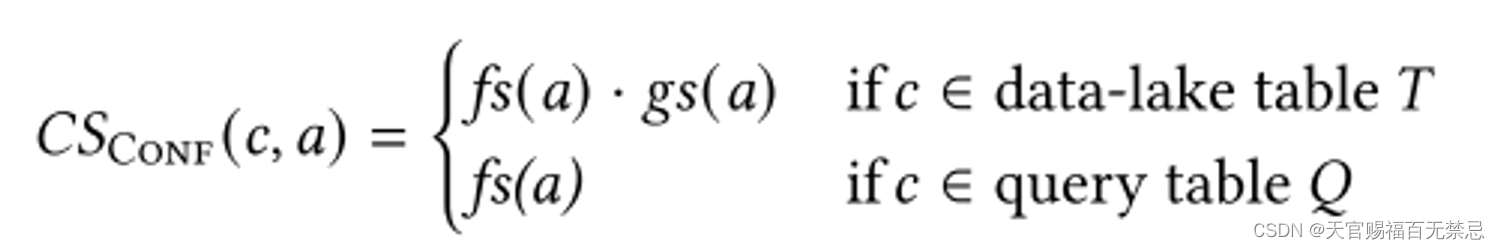
- 惩罚时候也需要注意:为了避免双倍惩罚,只惩罚在数据湖中表的顶级类型
4.3 列关系语义
对每一张表(查询表和数据湖内的每一张表)内的任意两列非数字的列都计算关系语义
最后保留在语义图中一条边上的只有得分最高的那个关系
列ci和cj满足KB中关系p的语义自信
- 统计i、j列中满足p的唯一value对的个数 / i、j列中满足KB中关系的唯一value对的个数
- 不进行惩罚,因为关系没有层次
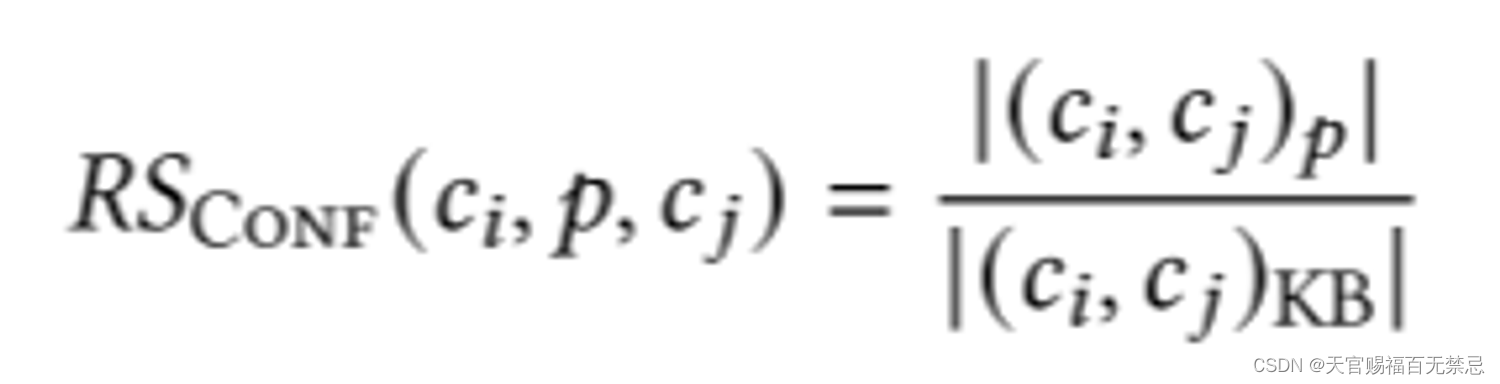
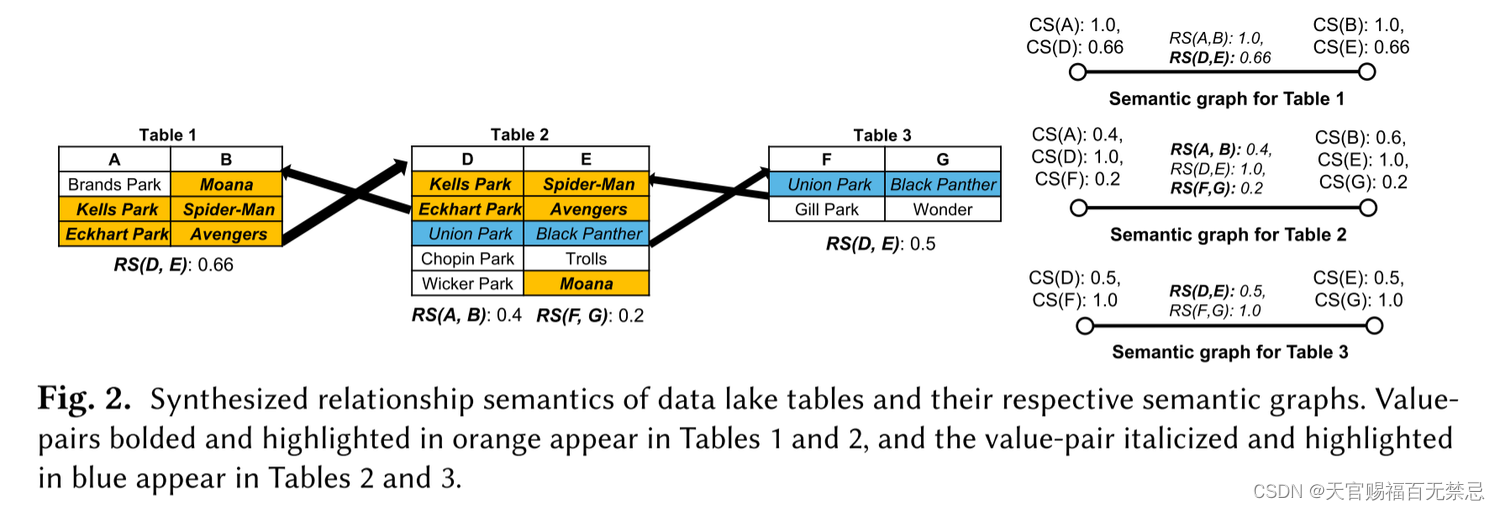
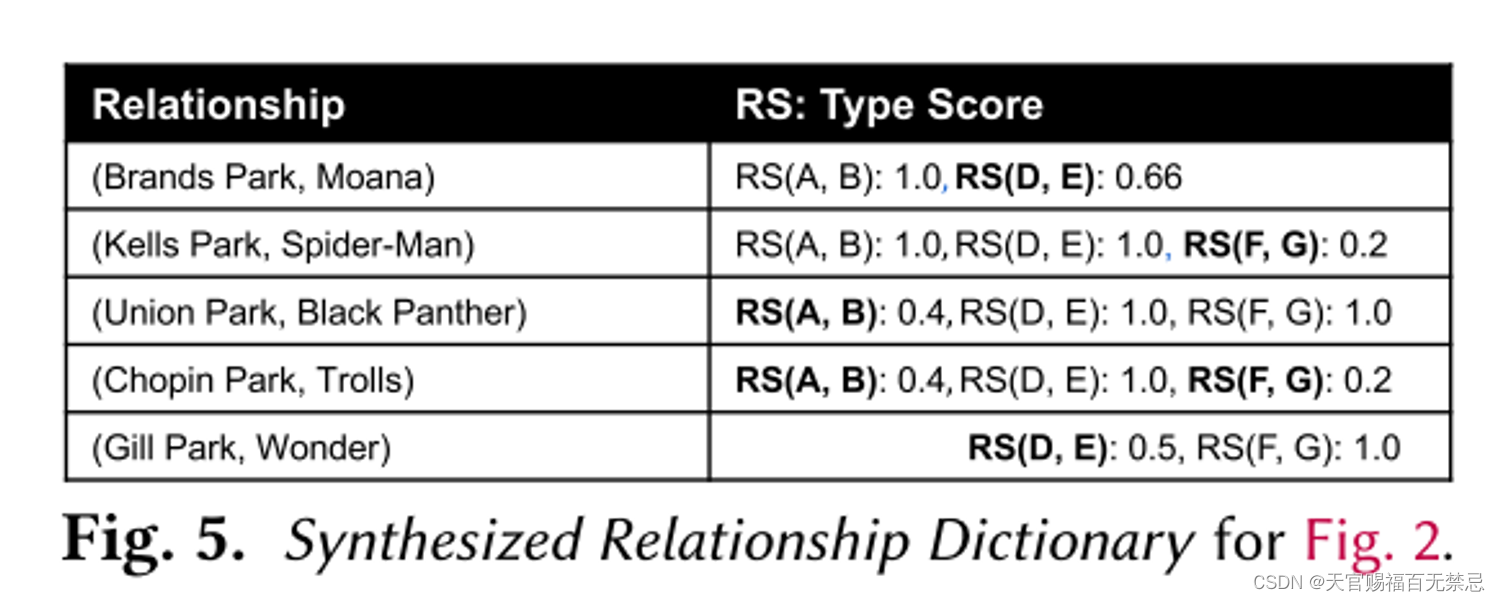
五、合成KB语义图
由于直接使用KB可能会出现覆盖不够的情况,因此可以利用数据驱动的方法创建合成的KB
- 主要思想:用一个合成KB能够捕获不同信息贡献能力的关系来替换利用已有
5.1 合成列语义
思想:每个列内的值表达的是相同的类型,假设没有同形异义词
步骤:
- 将每个数据湖中的列指派一个独一无二的合成语义,并赋予一个置信分数为1
- 如给四列分别赋予A、B、C、D
- 对于列c,如果c和cj的语义很近似,则c可以继承cj的CS a
- 置信分数:cj和c中相同的元素个数 / c中相同元素的个数
- a是列cj的合成类型
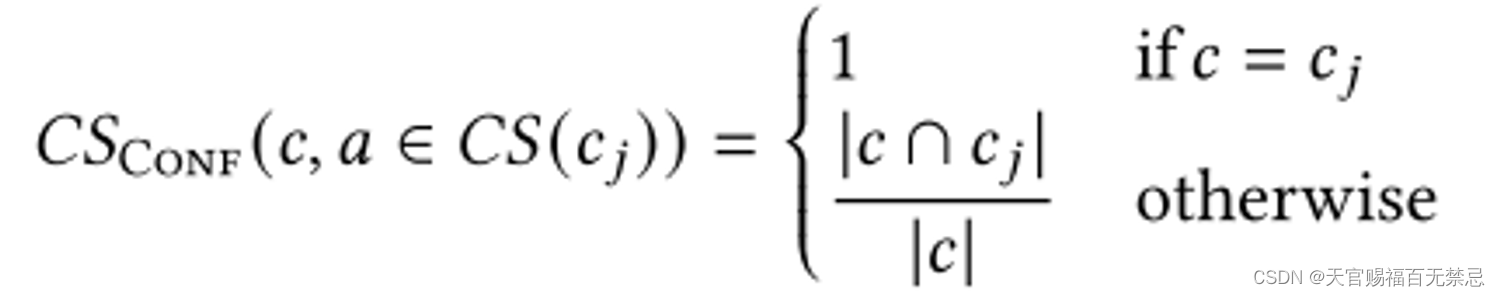
5.2 合成关系语义
在一张表中的列对如果有有意义的关系,则给他们一个合成关系语义
对于给(ci,cj)列对赋予(di,dj)列对语义p的置信分数
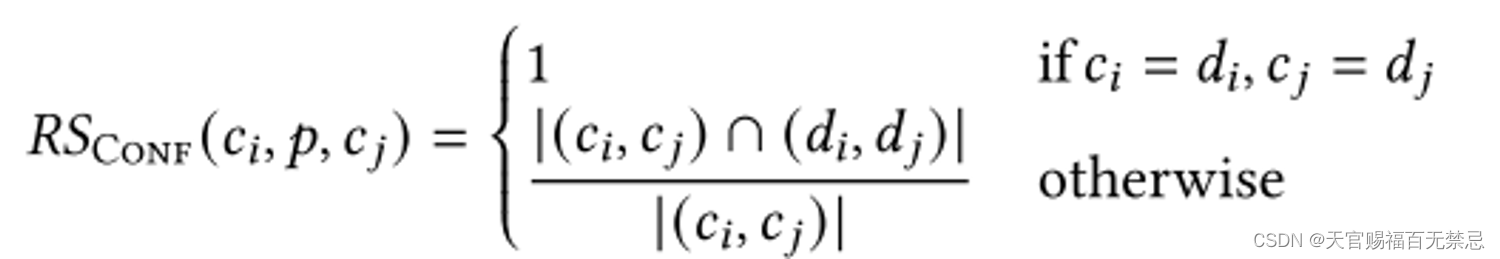
- 一对列之间会有很多种可能的关系,在查询阶段会选择和查询表最匹配的关系
六、SANTOS 的Union Search
本文中的打分
内容:查询表的列对和候选表的列队
自信度:匹配的质量
两阶段方法计算可连接性分数
-
intra-method:在一种语义图生成方法内计算最大的匹配分数
-
在查询表列Qc和数据湖表列Tc之间计算列匹配分数(选取它们共有的type,分别进行计算分数,取最大的)
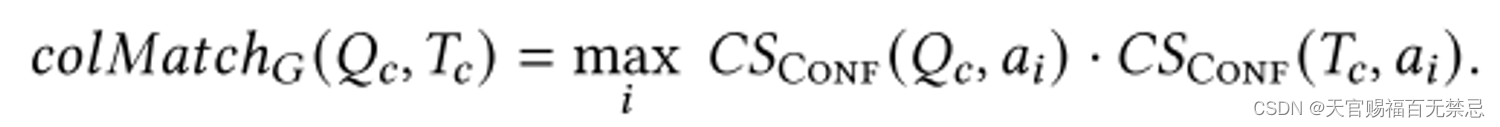
-
关系的匹配分数(类似,选择乘积最大的关系)
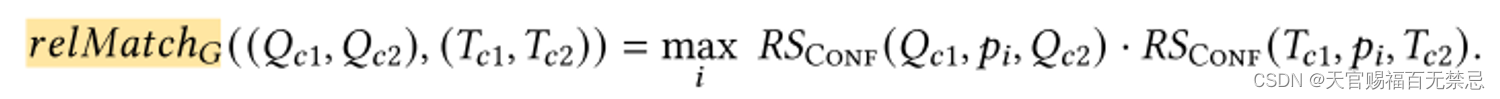
-
列对之间的总的匹配分数
- 两个列对的匹配程度:是从两个列都有的语义type中选择查询表该列和候选表该列乘积最高的作为结果
-
最终查询表内一对列和候选表内一对列的匹配程度为两列之间的语义对齐*关系对齐
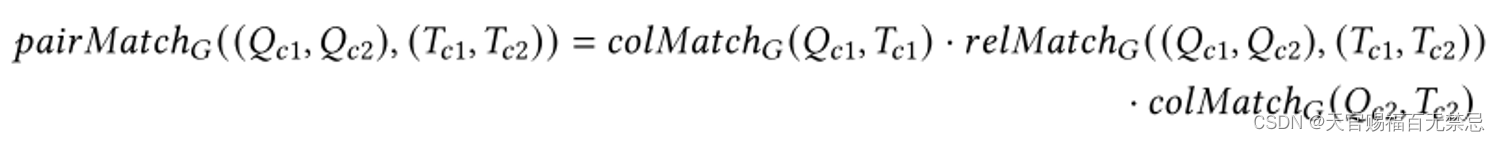
-
-
inter-method:在两种语义图生成方法中找到最大的总的分数
-
由于在利用已有KB进行计算时,利用了粒度分数进行惩罚,而在利用合成KB时则没有考虑。因此在计算方法间对匹配时,要忽略粒度分数。(对于KB计算出来的结果乘以两个gs对应的a1、a2粒度分数)
-
比较删除了粒度分数后是哪一种方法结果更大,则采取哪一种
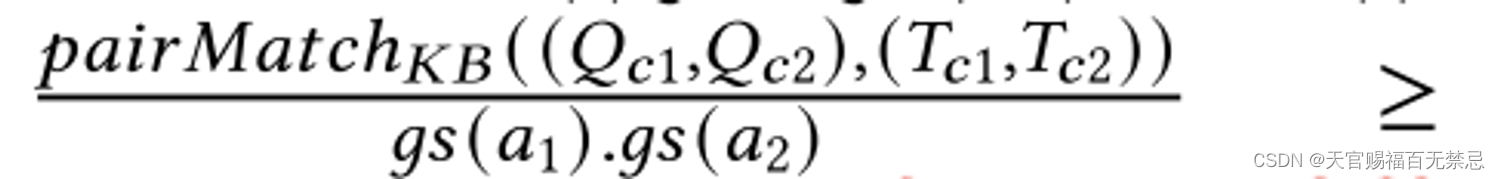
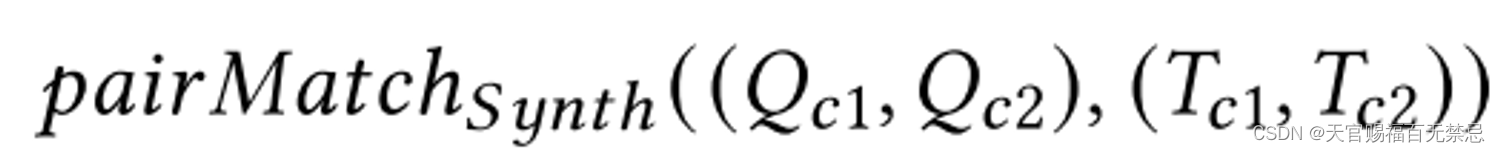
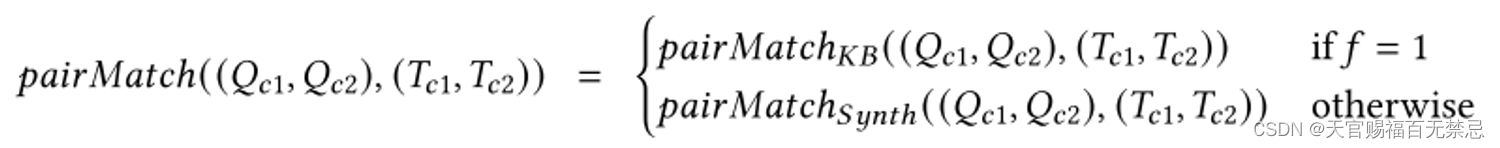
-
-
最终分数(两张表之间的分数)
- 是根节点和其它节点构成的列对的匹配分数之和(共有m个匹配列对,将所有匹配列对的分数进行加和)
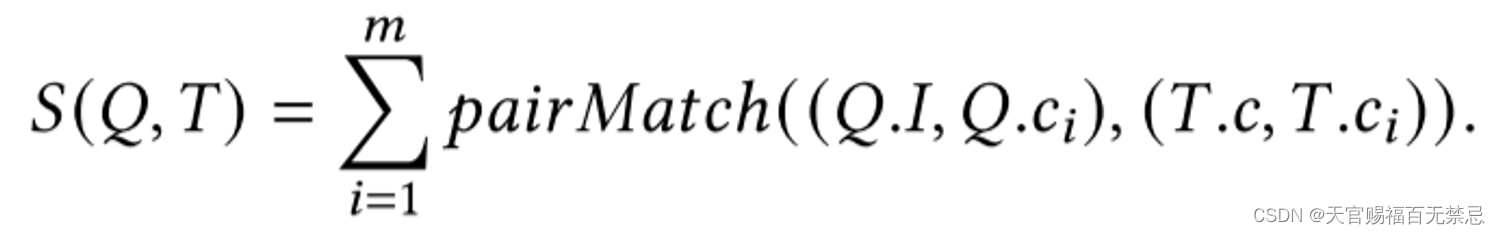
- 是根节点和其它节点构成的列对的匹配分数之和(共有m个匹配列对,将所有匹配列对的分数进行加和)
可以设计不同的惩罚类型函数(gs)
六、SANTOS的实现
知识图的实现、合成KB的创建、预处理阶段、查询阶段
7.1 知识图的实现
为KG创建字典提升效率
1、实体字典:描述实体的标签和别名,【标签-key,具体的类-value】
- 查询时,将列的值映射到KB中的标签or别名上
- YAGO支持同形异义字,即一个值可以映射到不同类型的实体上
2、创建层级字典(不同的层有的标签)
- 顶层的type以及它们的子type
3、类型字典:用entity作为key查找出(type,粒度评分)【entity-key,【所有的type数组(为了方便算gs)】】
4、关系字段:存储所有的二元关系(KB中每个value对对应的类型)
7.2 合成KB实现
创建合成类型字典和合成关系字典
- 由于直接将值看作实体,因此无需实体字典
- 由于type只有一层,无需层级字典
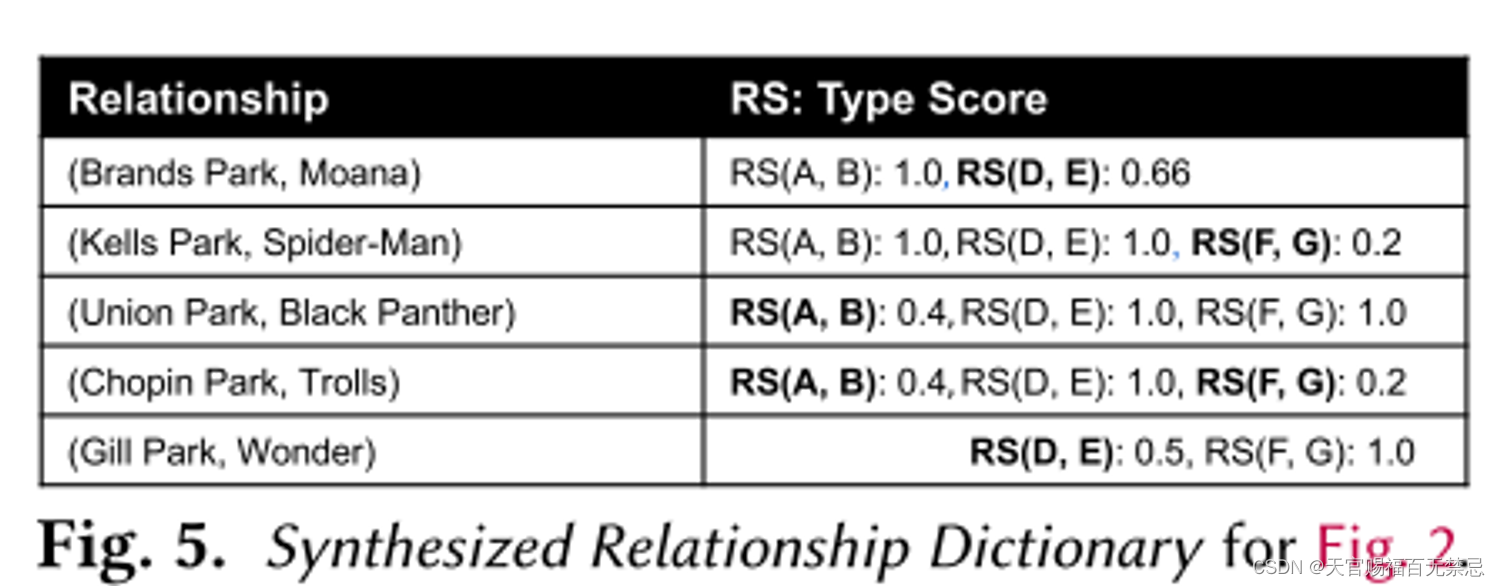
对于合成关系字典,只使用那些在已有KB中没有已有关系的列对,对它们的值进行增添。
- 类似的思想:主题建模[35],一些文档的潜在主题(值对)有其它文档的分布来表示(列对)
- SANTOS中首先为所有的列对都设置一个合成的RS,但是有一些RS会没有意义。→ 认为如果两列之间存在函数依赖关系,则说明它们之间的关系会有意义。→ 使用已有的函数依赖发现算法FDEP找到一元关系
- 合成字典的生成过程:
- a)首先找到所有的value对(需要不在已有的KB中,且这两列之间要有依赖关系)
- b)将这些value对写入到字典表中,赋予初始的合成RS关系,分数为1
- c)接着计算它可能属于别的RS的概率(利用的是前面计算value-pair之间重叠情况的分数来进行赋值
预处理阶段
线下的预处理阶段:利用现有KB来找到表的CS和RS,发现表之间的FD来帮助创建一个合成的KB。
为了减少时间,创建倒排索引:
- 节点逆序索引:将列映射到他对应的CS,带有其对应的CS分数CSconf)
- 边逆序索引:将RS映射到同一表内相关的列中,还有RS分数RSconf
时间复杂度
- CS:O(tmn)
- RS:O(tmcmc*n)
- 其中mc是一张表可能有CS的最大列数(有一些列找不到对应的CS)
创建合成KB的时间复杂度
- 包括创建合成类型字典和合成关系字典
- 合成类型字典的创建类型类似于CS
- 合成关系字典的创建类似于


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









