




Hadoop杂烩
边学边写,持续更新中
配合目录用
启动进程
| 启动 | CODE |
|---|---|
| Namenode | sbin/hadoop-daemon.sh start namenode |
| Damenode | sbin/hadoop-daemon.sh start datanode |
| ResourceManager | sbin/yarn-daemon.sh start resourcemanager |
| NodeManager | sbin/yarn-daemon.sh start nodemanager |
| 历史服务器 | sbin/mr-jobhistory-daemon.sh start historyserver |
| 启动 | start-dfs.sh |
| 启动 | start-yarn.sh |
hdfs删除命令
bin/hdfs dfs -rm -r
虚拟机准备
博主用的是VM软件操作,以下步骤根据自己要求适当性安装
1. 安装VM Tool
为了方便虚拟机和电脑之间的复制粘贴
- 在菜单栏,点 虚拟机 ,点 安装Vmware Tool
- 打开桌面上的VM Tool文件,把后缀为
gz的文件复制,打开桌面左边栏的文件,新建一个文件夹,把刚才拷贝的文件粘贴
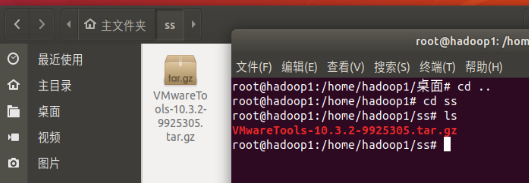
- 打开终端,找到文件解压
tar -zxvf VMwareTools-10.3.2-9925305.tar.gz - 进入到 vmware-tools-distrib 中,执行
./vmware-install.pl,期间一直敲回车 - 设置共享文件夹,
解决拖动文件卡死问题 - 在
/mnt/hgfs/share下
1. 将Ubuntu关机(power off),否则不能添加共享文件夹
2. 在VMware虚拟机窗口,选择虚拟机->设置->选项->共享文件夹
3. 点右边的“添加”,点“下一步”->选择事先创建好的共享目录的路径,然后点“下一步”->选中 启动共享->完成
4. 在窗口的右边,选择“总是启用”
5. 点 确定 退出
2. 换源
这里是18.04版本的源
- 进入管理员模式,
sudo -i cd ..退到根目录,vi /etc/apt/sources.list
按dd(长按)
按i
鼠标右键-粘贴下面的源
按Esc
:wq 退出保存
# 清华源 首推,还要阿里源 中科大源 可自行百度
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse
deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-proposed main restricted universe multiverse
- 执行下面代码更新
apt-get update
apt-get upgrade
3. 安装相应软件
- 安装vim
apt install vim - 安装ssh
apt-get install ssh - 安装rsync
apt-get install rsync
4. 安装Jdk和Hadoop
- 解压
tar -zxvf ****** - 配置环境变量
vim /etc/profile
输入相应的环境变量
## JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_144
## 路径不唯一 可以进入jkd 然后用pwd看路径
export PATH=$PATH:$JAVA_HOME/bin
## HADOOP
export HADOOP_HOME=/opt/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- 更新
source /etc/profile
5. grep案例
- 进入Hadoop目录下,创建一个文件
mkdir input - 复制文件
cp etc/hadoop/*.xml input - 运行grep
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+' - 查看结果
cat output/*
6. wordcount案例
- 在hadoop路径下创建一个wcinput文件夹
mkdir wcinput,然后创建touch wc.input - 编辑wc.input
vim wc.input在里面随便输点什么,保存退出 - 在/opt/Hadoop-2.7.2目录下执行 wordcount
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput - 看运行结果
cat wcoutput/part-r-00000
伪分布式案例
1. HDFS
1. 配置文件
- 配置core-site.xml,进入 /opt/hadoop-2.7.2/etc/hadoop 目录下,
vim core-site.xml - 在两个
<configuration>中间写入一下代码,保存退出
<!--指定HDFS中NameNode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!--指定Hadoop运行时产生文件的存储路径-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.2/data/tmp</value>
</property>
- 配置hadoop-env.sh,
vim hadoop-env.sh,写入JAVA_HOME,用echo $JAVA_HOME看java路径。如图
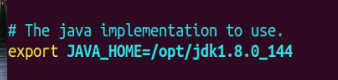
- 配置hdfs-site.xml,
vim hdfs-site.xml,写入以下代码
<!--指定HDFS副本数量-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
2. 启动集群
- 格式化NameNode
bin/hdfs namenode -format - 启动NameNode
sbin/hadoop-daemon.sh start namenode - 启动DataNode
sbin/hadoop-daemon.sh start datanode - 查看启动情况
jps或者是 在虚拟机里的网页打开localhost:50070或者是浏览器打开网页虚拟机ip:50070
3. 测试
- 创建文件 ,结果如图
bin/hdfs dfs -mkdir -p /user/root/input
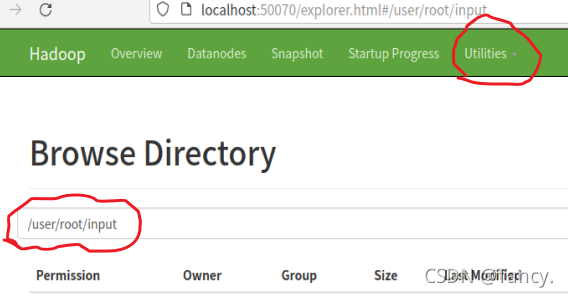
- 上传文件,这里是之前的那个wordcount案例的文件。刷新网页即看到文件
bin/hdfs dfs -put wcinput/wc.input /user/root/input

- 执行hdfs上的文件,output不能事先创建。结果如图
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/root/input /user/root/output

- 在本地看hdfs的结果
bin/hdfs dfs -cat /user/root/output/p*
2. YARN
1. 配置
- 配置yarn-env.sh ,删除export之前的
#,更改JAVA_HOMEvim yarn-env.sh,如图

- 配置yarn-site.xml,
vim yarn-site.xml,地址可以写自己的主机名或者是localhost
<!--Reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定Yarn的ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
- 配置mapred-env.sh,更改JAVA_HOME,
vim mapred-env.sh,如图
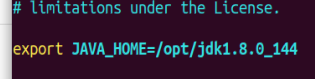
- 配置mapred-site.xml,先将mapred-site.xml.template重命名为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
然后再vim mapred-site.xml,加入以下代码
<!--指定MR运行在Yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2. 启动
- 启动集群,启动之前保证namenode和datanode已启动,用
jps看。
要在/opt//hadoop-2.7.2目录下启动
启动ResourceManager
sbin/yarn-daemon.sh start resourcemanager
启动NodeManager
sbin/yarn-daemon.sh start nodemanager
用 localhost:8088 网址看是否启动成功,如图
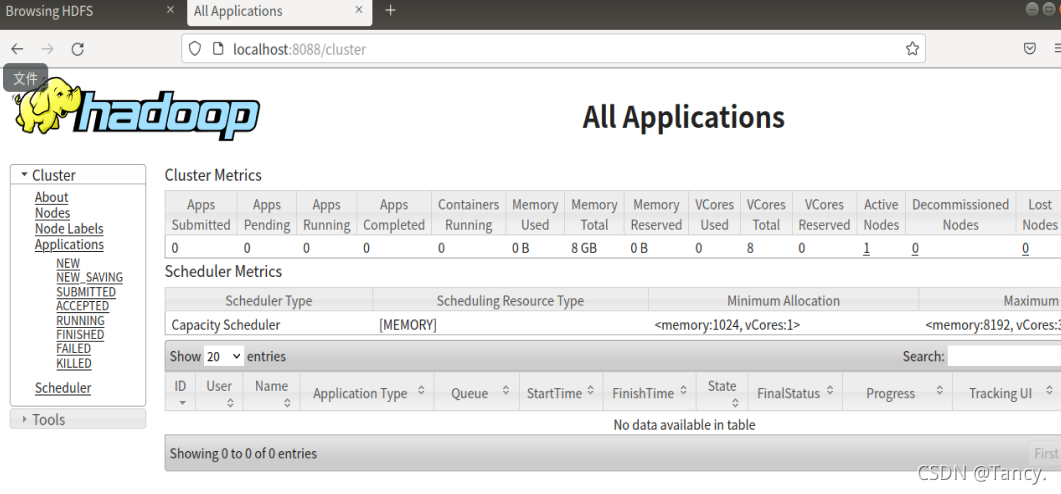
- 测试 运行wordcount案例
删除output
hdfs dfs -rm -r /user/root/output
运行wordcount
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/root/input /user/root/output
在Yarn上看进度
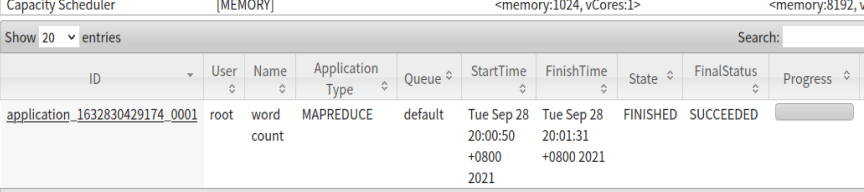
3. 配置历史服务器
1. 配置
配置mapred-site.xml vim mapred-site.xml
用hostname 看主机名
ipconfig 看ip
<!--历史服务器端地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>虚拟机主机名:10020</value>
</property>
<!--历史服务器Web端地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>虚拟机IP:19888</value>
</property>
2. 启动
启动
sbin/mr-jobhistory-daemon.sh start historyserver
用 jps 看,或者网址http://上面的IP:19888/jobhistory
测试
用wordcount案例测试,注意先删掉outout
4. 日志聚合
- 配置配置yarn-site.xml
vim yarn-site.xml加入以下代码
<!--日志聚合功能使能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--日志保留时间设置为七天-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
- 关闭NodeManager、ResourceManager、HistoryManager
sbin/mr-jobhistory-daemon.sh stop historyserver
sbin/yarn-daemon.sh stop nodemanager
sbin/yarn-daemon.sh stop resourcemanager
- 重启NodeManager、ResourceManager、HistoryManager
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
sbin/mr-jobhistory-daemon.sh start historyserver
- 再次运行wordcount案例去看聚合后的日志
完全分布式
1.环境准备
1. 主机名 IP 防火墙
- 主机名
- 安装软件包
apt-get install cloud-init - 修改/etc/cloud/cloud.cfg
vim /etc/cloud/cloud.cfg
找到preserve_hostname: false修改为preserve_hostname: true - 修改主机名(永久)
vim /etc/hostname
#映射主机名
vim /etc/hosts
- 静态IP
- 打开Vm状态栏的编辑,点 虚拟网络编辑器 ,点第三个NAT模式,点 NAT设置,记住网关地址
- 打开终端,查IP
ifconfig记住ip 。若提示未安装net,按提示安装 - 设置静态ip
vim /etc/netplan/01-network-manager-all.yaml,注意这里不一定是01,去netplan目录下看再进入配置
# Let NetworkManager manage all devices on this system
network:
version: 2
renderer: networkd
ethernets:
enp33: #配置的网卡名称,使用ifconfig -a查看得到 注意这里的enp33是博主的
addresses: [ip地址/24] #设置本机IP及掩码
gateway4: 网关地址 #设置网关
nameservers:
addresses: [刚才记的网关地址] # DNS
- 让设置生效
netplan apply - 配置host
vim /etc/hosts如图
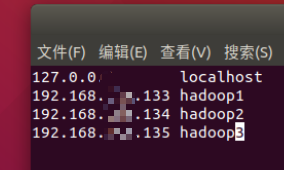
- 关闭防火墙
查看当前防火墙状态ufw status
关闭防火墙ufw disable
完成三步操作后,重启
2. 配置环境(ssh免密)
- SSH配置及免密配置
- 进入root用户,安装ssh,
apt-get install ssh,用ssh localhost检测 - 重置root用户的密码,
passwd root,可以输入登录root时的密码。为了解决permission denied,please try again问题!!! - 允许以 root 用户通过 ssh 登录:
vi /etc/ssh/sshd_config,找到 PermitRootLogin prohibit-password ,取消注释,并改为 PermitRootLogin yes。然后重启ssh,service ssh restart - SSH免密登录设置:
ssh-keygen -t rsa生成公钥和私钥,连续敲三个回车。分发给自己和其他两个虚拟机,ssh-copy-id hadoop1ssh-copy-id hadoop2ssh-copy-id hadoop3,过程中输入yes和对应的密码 - ping一下看连接上了吗
ping -c 1 主机名
- jdk和hadoop
- 把jdk和hadoop拷贝到其他两台虚拟机
scp -r /opt root@主机名:/opt我这里的opt目录下有jdk和Hadoop的安装包,这个命令是把opt目录下所有文件递归的复制过去。这里需要输入另一台虚拟机root密码 - 分别拷贝完。然后就解压,配置环境变量。见上面的步骤
另外的方法是:在一台主机上解压和配置完,然后scp到其他虚拟机上,环境变量的是scp -r /etc/profile root@主机名:/etc/profile
2. 集群配置
1. 集群分发脚本
- xsync
cd /usr/local/bintouch xsyncvim xsync粘贴以下代码
#!/bin/bash
if [[ ! -x $(command -v rsync) ]]; then
echo no rsync found!
exit 1
fi
#1 获取输入参数的个数;如果没有参数,直接退出
pcount=$#
if ((pcount==0)); then
echo no args!
exit
fi
#2 获取文件名称
p1=$1
fname=$(basename $p1)
echo fname=$fname
#3 获取文件绝对路径
pdir=$(cd -P $(dirname $p1); pwd)
echo pdir=$pdir
#4 获取当前用户名称
usr=$(whoami)
#5 循环体
for ((host=2; host<4; host++)); do
echo ---hadoop${host}---
rsync -rvl $pdir/$fname ${usr}@hadoop${host}:${pdir}
done
chmod +x xsync赋予权限
2. 集群配置
记住这张图
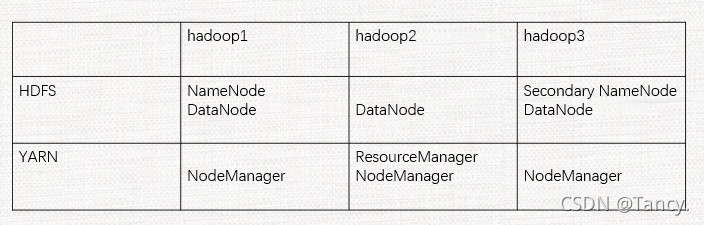
- 配置core-site.xml
vim /opt/hadoop-2.7.2/etc/hadoop core-site.xml
<!--指定HDFS中NameNode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9000</value>
</property>
<!--指定Hadoop运行时产生文件的存储路径-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.7.2/data/tmp</value>
</property>
注意这里的主机名,和上图对应
- 配置hadoop-env.sh
同伪分布操作,见上文 - 配置hdfs-site.xml
vim /opt/hadoop-2.7.2/etc/hadoop hdfs-site.xml
<!--指定HDFS副本数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定Hadoop Secondary NameNode配置-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop3:50090</value>
</property>
- 配置 yarn-env.sh 环境变量
vim /opt/hadoop-2.7.2/etc/hadoop yarn-env.sh见上文 - 配置 yarn-site-xml
vim /opt/hadoop-2.7.2/etc/hadoop yarn-site-xml
<!--Reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定Yarn的ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop2</value>
</property>
<!--防止主机名进不去-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop2的ip:8088</value>
</property>
- 配置mapred-env.sh 环境变量
vim /opt/hadoop-2.7.2/etc/hadoop mapred-env.sh见上文 - 配置mapred-site.xml
vim opt/hadoop-2.7.2/etc/hadoop mapred-site.xml
<!--指定MR运行在Yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 配置历史服务器 mapred-site.xml
放在第一台主机,IP和主机名都填第一台的
<!--历史服务器端地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<!--历史服务器Web端地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1的IP:19888</value>
</property>
- 日志聚合 yarn-site.xml
详情见伪分布式日志聚合
<!--日志聚合功能使能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--日志聚合功能使能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
- 分发配置
xsync /opt/hadoop-2.7.2/etc/hadoop
然后去另一台虚拟机检查是否分发成功
3. 群启与测试
1. 群启
- 配置slaves
vim ${HADOOP_HOME}/etc/hadoop/slaves
写入三台主机名,不能多余的空格回车 如图
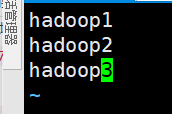
- 分发slaves
xsync salves去其他虚拟机看一下分发成功了吗 - 群起集群
先格式化Namenode,见上文
在 /opt/hadoop-2.7.2 目录下
在规划的NameNode(hadoop1)上执行:
sbin/start-dfs.sh
sbin/stop-dfs.sh
在规划的ResourceManager(hadoop2)上执行:
sbin/start-yarn.sh
sbin/stop-yarn.sh
启动历史服务器 (hadoop1)
sbin/mr-jobhistory-daemon.sh start historyserver
在每个虚拟机上用 jps 查看启动结果
2. 测试
- 上传文件
创建存储路径
hdfs dfs -mkdir -p /usr/root/input
上传小文件
hdfs dfs -put wcinput/wc.input /user/root/input
上传大文件
hdfs dfs -put /opt/hadoop-2.7.2.tar.gz /user/root/input - 上传之后,文件还是保存在本地的,可以在本地查看,然后拼接解压
- 测试wordcount案例
略,见上文
4. 时间同步
同步阿里服务器的时间
apt install ntpdate
ntpdate ntp4.aliyun.com
每一个服务器都设置一下
勿看,没写完
- 安装ntp
apt install ntp - 进入修改配置
vim /etc/ntp.conf
修改1,授权本网段所有主机可以从这台服务器上查询和同步时间,改为自己的网段,如图 网段就是IP的前三段
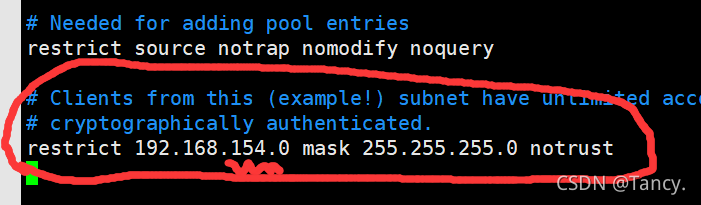
修改2,集群在局域网中,不使用其它互联网上的时间。注释掉与网络的连接,注释如图所示的白色代码部分
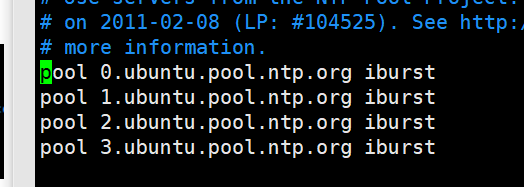
修改3,当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其它节点提供时间同步。在最后加入以下代码
保存退出后重启ntp
server 127.127.1.0
fudge 127.127.1.0 stratum10
-
ntp 相关设置
查看ntp状态service ntp status或者是watch "ntpq -p"
启动ntpservice ntp start
重启ntpservice ntp restart -
创建例行性命令,10分钟与时间服务器同步一次
创建/etc/cron.d/ntpupdate.cron文件
``
常见问题
- namenode启动后消失;namenode启动不了
方法一:查看core-site-xml 中的主机名,伪分布是localhost
方法二:格式化不干净,先停止namenode和datanode进程,然后删掉 opt 目录下的data文件和logs文件,再格式化namenode,再启动 - 虚拟机启动黑屏
解决方案:
1.运行cmd,执行 netsh winsock reset,重启电脑
2.设备-显示器-加速3D图形取消对勾
3.编辑-首选项-设备-虚拟打印机,选择启动虚拟打印机,重启电脑
能挂起就别关机
idea会省略细节,能不用就不用。避免更换开发环境不会写代码
端口
8088 mapreduce
50070 hdfs
ifconfig 看ip
| NAME | TIPS | TIPS |
|---|---|---|
| 清屏 | Ctrl + l | clear |


















 988
988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











