




 本文详细介绍了如何在Linux虚拟机上搭建Hadoop集群,包括单节点、伪分布式和全分布式配置。从安装Linux、设置静态IP、安装JDK和Hadoop,到配置环境变量、关闭防火墙、免密登录、配置Hadoop相关文件,以及进行测试案例,整个过程详细阐述,适合初学者参考。
本文详细介绍了如何在Linux虚拟机上搭建Hadoop集群,包括单节点、伪分布式和全分布式配置。从安装Linux、设置静态IP、安装JDK和Hadoop,到配置环境变量、关闭防火墙、免密登录、配置Hadoop相关文件,以及进行测试案例,整个过程详细阐述,适合初学者参考。
首先在vm上安装一台Linux系统虚拟机,安装方法可以在网上查找
下面是安装好虚拟机之后的操作
可以下载一个finallshell工具,操作更方便
链接:https://pan.baidu.com/s/1dAdk7qvX4uEN2KLWZ5VHQw
提取码:9527
JDK1.8下载
链接:https://pan.baidu.com/s/1ElO1vHFRb6HR5ijRj2j_og
提取码:9527
先在虚拟机系统上如下操作:
查看自己的IP
登录虚拟机
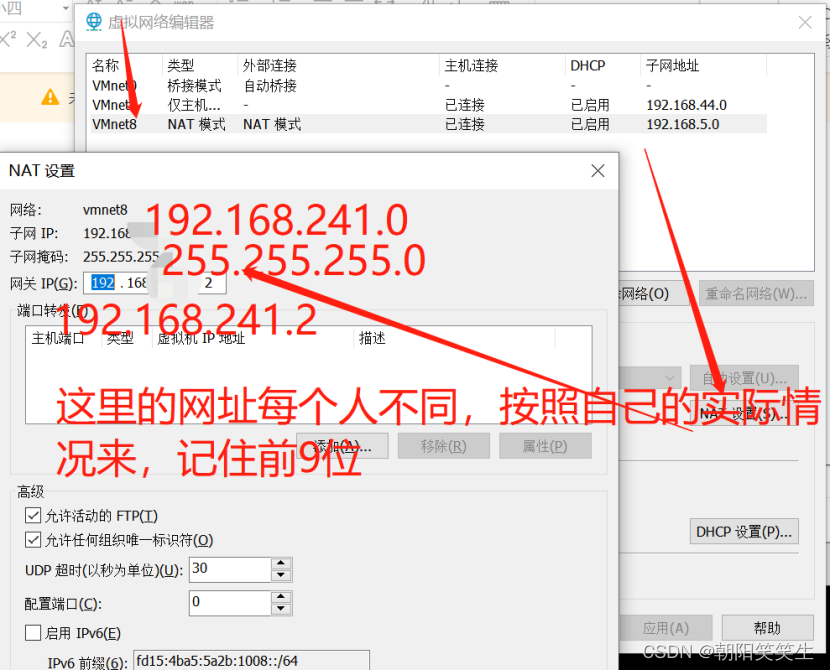
修改静态IP
首先找到/etc/sysconfig/network-scripts/下的ifcfg-ens33配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
![]()
把 BOOTPROTO = “dhcp” 改成 BOOTPROTO = “static” 表示静态获取,然后把 UUID 注释掉,把 ONBOOT 改为 yes,表示开机自动静态获取,然后在最后追加比如下面的配置:
IPADDR=192.168.241.161 #自己的ip地址,前9位和自己前面查看的相同,后三位可以150左右的值,我写了161,至于为什么可以网上查找
NETMASK=255.255.255.0
GATEWAY=192.168.241.2
DNS1=114.114.114.114
DNS2=8.8.8.8
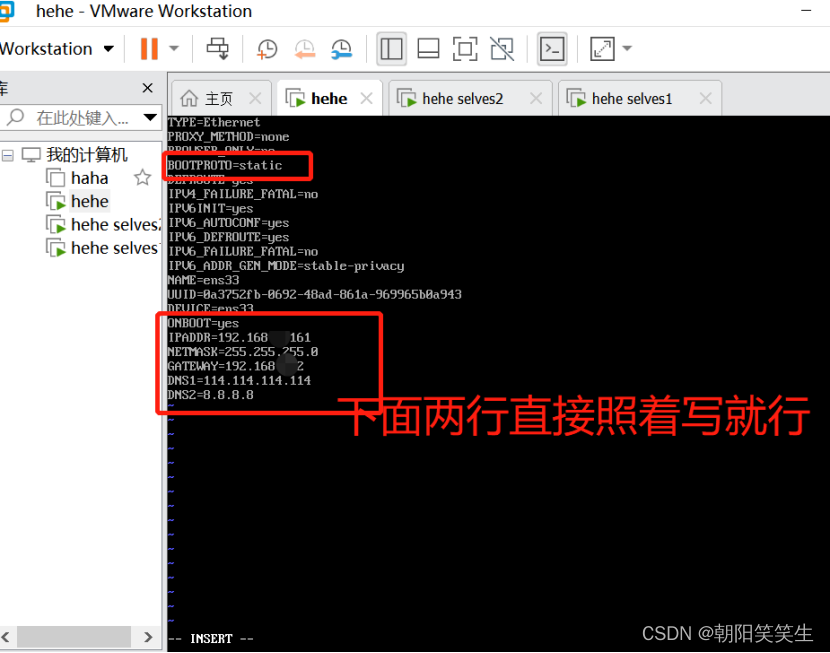
IPADDR就是静态IP,NETMASK是子网掩码,GATEWAY就是网关或者路由地址
重启网络服务
centos6的网卡重启方法:service network restart
centos7的网卡重启方法:systemctl restart network
然后用自己设置的IPADDR=192.168.241.161 #自己的ip地址
连接finallshell
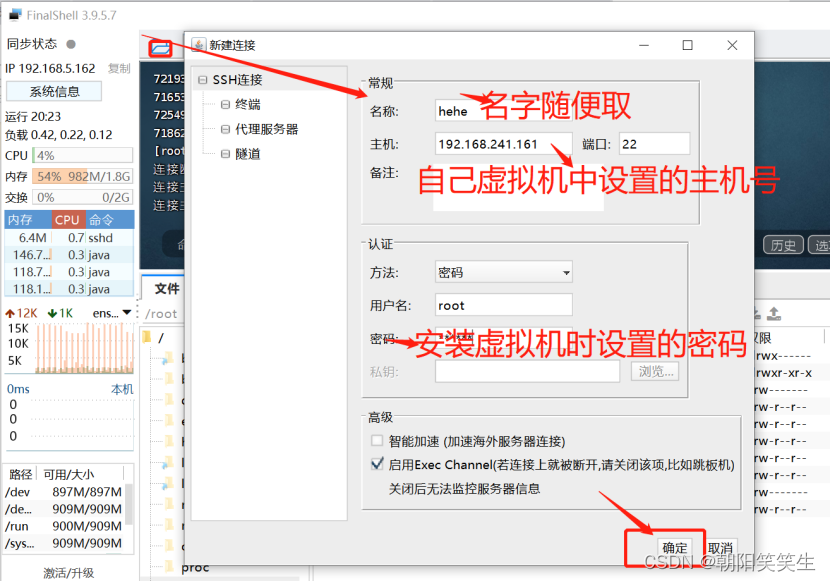
修改主机名 vi /etc/hostname
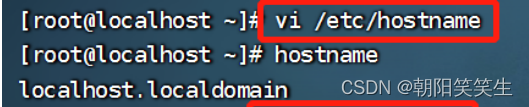

断开连接 shutdown -r

重新连接
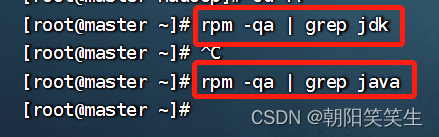
检查是否有jdk
rpm -qa | grep jdk
rpm -qa | grep java
进入opt文件夹创建software和apps文件夹用来存储软件包和解压包
cd /opt/
mkdir software
mkdir apps
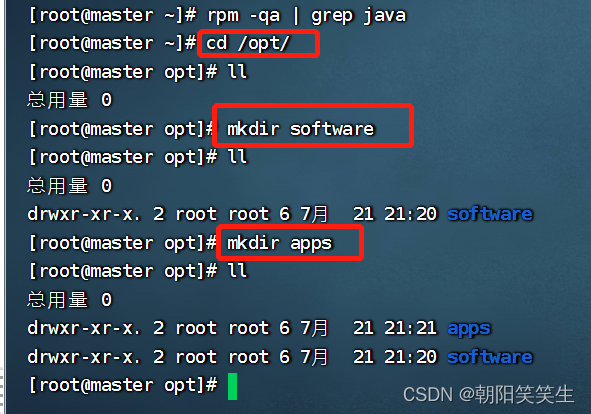
将安装包放入software文件夹中
然后进入software
cd software
执行解压命令解压到apps文件夹
tar -zxvf jdk-8u333-linux-x64.tar.gz -C /opt/apps/
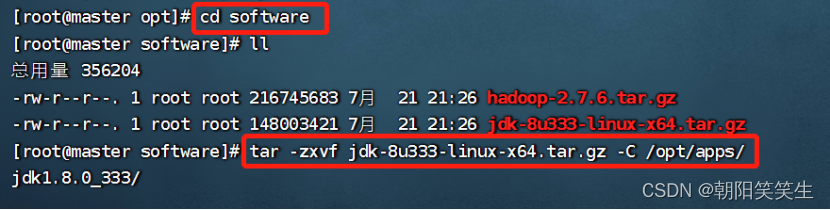
解压完成进入apps文件夹
cd ..
cd apps/
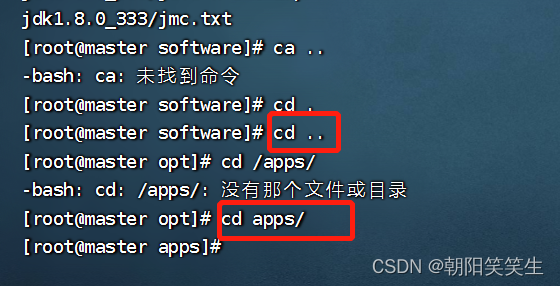
改名为jdk
mv jdk1.8.0_333 jdk
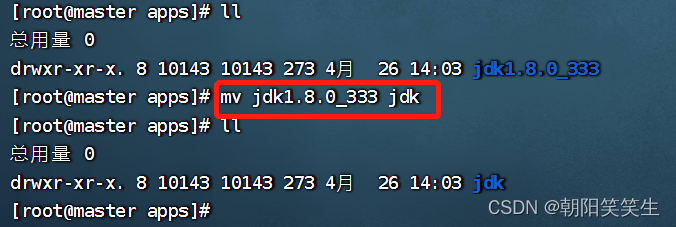
配置环境变量
vi /etc/profile
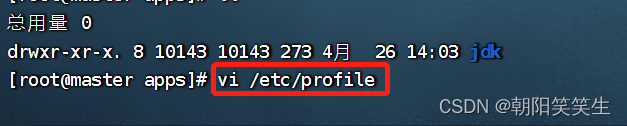
按i 编辑
export JAVA_HOME=/opt/apps/jdk
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/lib
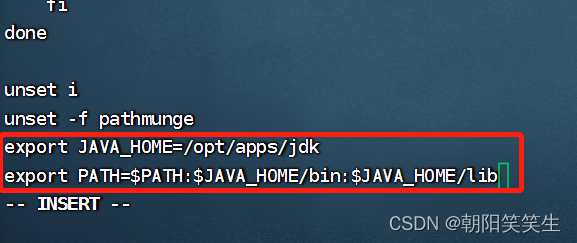
按esc键退出编辑模式
按:wq 按回车保存退出
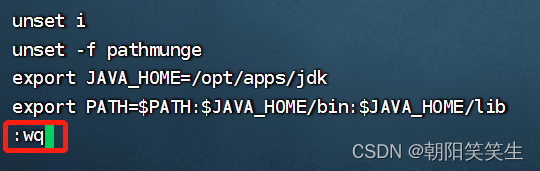
生效配置文件
source /etc/profile
检查配置文件
java -version
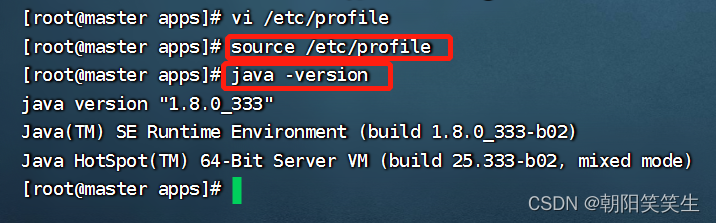
显示Java版本证明配置成功
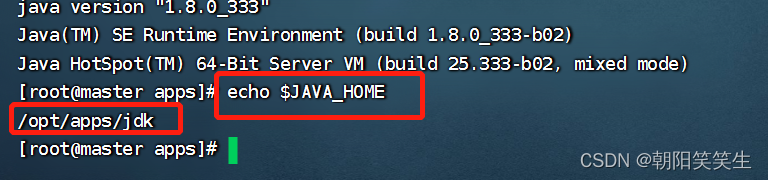
也可以用执行java_home 方式验证
echo $JAVA_HOME
安装hadoop
安装包放到software文件夹中
进入software文件夹
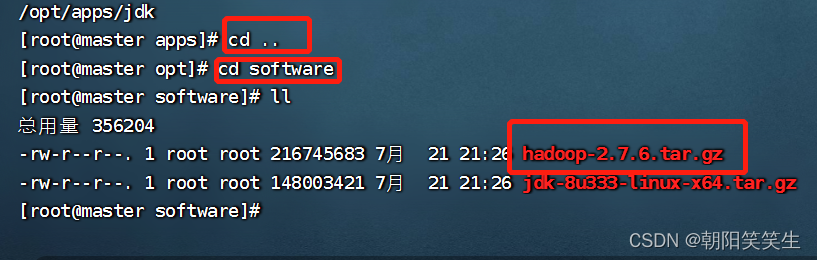
将安装包安装到apps文件夹下面
tar -zxvf hadoop-2.7.6.tar.gz -C /opt/apps/

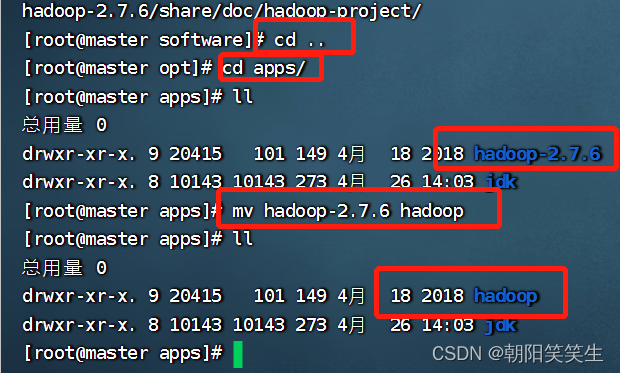
安装完成后,进入apps文件夹中,改名为hadoop
cd ..
cd apps/
mv hadoop-2.7.6 hadoop
配置环境变量
vi /etc/profile

export HADOOP_HOME=/opt/apps/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/lib:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

保存退出
生效配置文件
source /etc/profile
检查配置情况
hadoop version
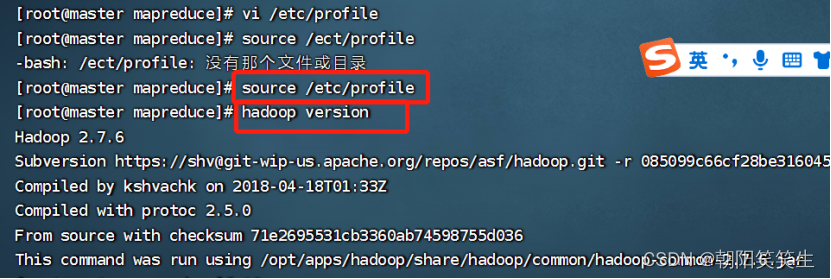
显示hadoop版本,单节点版配置成功
接下来
伪分布式搭建
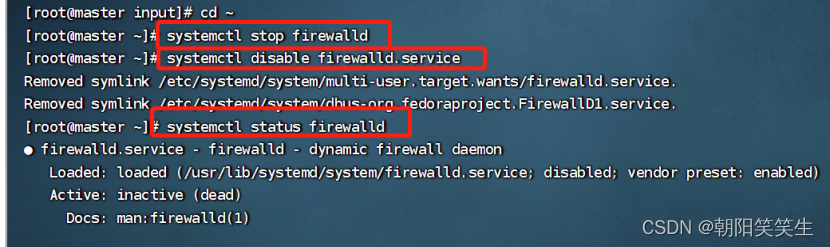
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld.service
systemctl status firewalld
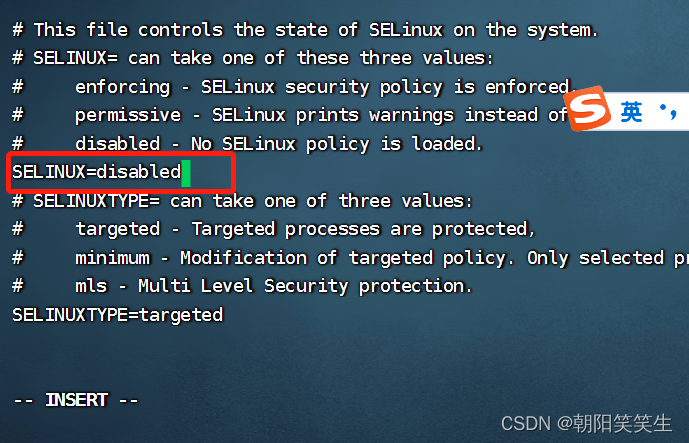
vi /etc/selinux/config

配置镜像文件
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1697
1697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









