









41. Redis 分布式锁详解
什么是分布式锁?
-
分布式锁其实就是,控制分布式系统不同进程共同访问共享资源的一种锁实现的方式,如果不同的系统或者同一个系统的不同主机之间共享了某个临界资源,往往需要互斥来防止彼此干扰,以保证一致性
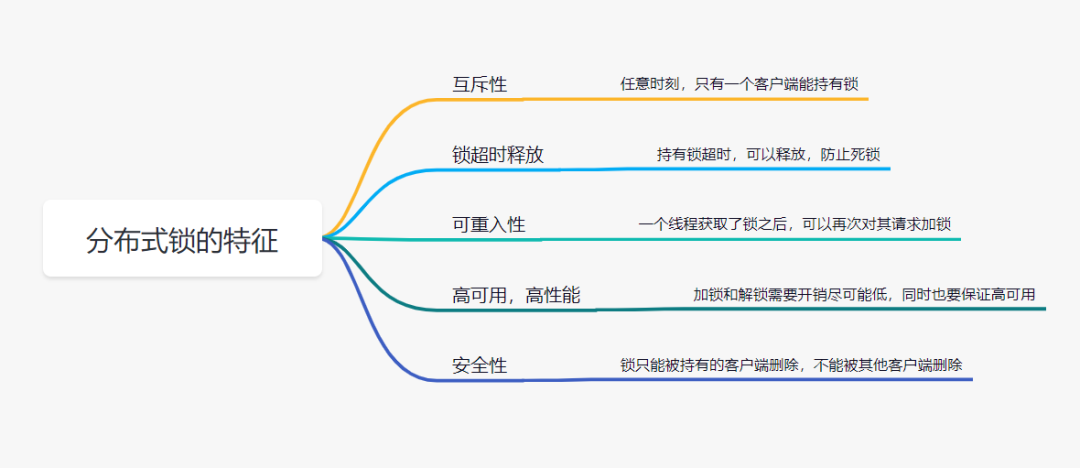
- 互斥性:任意时刻,只有一个客户端能持有锁
- 锁超时释放:持有锁超时,可以释放,防止不必要的资源浪费,也可以防止死锁
- 可重入性:可重入锁,也叫做递归锁,指的是在同一线程内,外层函数获得锁之后,内层递归函数仍然可以获取到该锁。 说白了就是同一个线程再次进入同样代码时,可以再次拿到该锁。 (作用:防止在同一线程中多次获取锁导致死锁发生)
- 高性能和高可用:加锁和解锁需要开销尽可能低,同时也要保证高可用,避免分布式锁失效(高性能:查询快,高可用:节点故障时,服务仍然能正常运行或进行降级后提供部分服务)
- 安全性:锁只能被持有的用户删除,不能被其他客户端删除
Redis 分布式锁实现一:SETNX + EXPIRE
但是使用这个方案要注意 setnx 与 expire 之间的原子性操作,如果在执行完 setnx 之后服务器 crash 或重启了导致加的这个锁没有设置过期时间,就会导致死锁的情况(别的线程就永远获取不到锁了)
Redis 分布式锁实现二:SETNX + value 值(系统时间 + 过期时间)
把过期时间放在 setnx 的 value 里面,如果加锁失败,再拿出 value 值校验一下即可。
加锁代码:
//系统时间+设置的过期时间
long expires = System.currentTimeMillis() + expireTime;
String expiresStr = String.valueOf(expires);
// 如果当前锁不存在,返回加锁成功
if (jedis.setnx(key_resource_id, expiresStr) == 1) {
return true;
}
// 如果锁已经存在,获取锁的过期时间
String currentValueStr = jedis.get(key_resource_id);
// 如果获取到的过期时间,小于系统当前时间,表示已经过期
if (currentValueStr != null && Long.parseLong(currentValueStr) < System.currentTimeMillis()) {
// 锁已过期,获取上一个锁的过期时间,并设置现在锁的过期时间(不了解redis的getSet命令的小伙伴,可以去官网看下哈)
String oldValueStr = jedis.getSet(key_resource_id, expiresStr);
if (oldValueStr != null && oldValueStr.equals(currentValueStr)) {
// 考虑多线程并发的情况,只有一个线程的设置值和当前值相同,它才可以加锁
return true;
}
}
//其他情况,均返回加锁失败
return false;
}
- 这个方案的优点是:移除了 expire 单独设置过期时间的操作,把过期时间放到 setnx 的 value 值里面来,解决了所得不到释放的问题。
- 这个方案也是有缺点的:
- 过期时间是客户端自己生成的(System.currentTimeMillis() 是当前系统的时间),必须要求分布式环境下,每个客户端的时间必须同步。
- 如果所过期的时候,并发多个客户端同时请求过来,都执行 jedis.getSet(),最终只能有一个客户端加锁成功,但是该客户端锁的过期时间,可能被其他的客户端覆盖。
- 该锁没有保存持有者的唯一标识,可能被别的客户端释放 / 解锁。
Redis 分布式锁方案三:使用 Lua 脚本(包含 SETNX + EXPIPE 两条指令)
实际上,我们可以使用 Lua 脚本来保证原子性(包含 setnx 和 expire 两条指令)
- lua 脚本如下:
if redis.call('setnx',KEYS[1],ARGV[1]) == 1 then
redis.call('expire',KEYS[1],ARGV[2])
else
return 0
end;
- 加锁代码如下:
String lua_scripts = "if redis.call('setnx',KEYS[1],ARGV[1]) == 1 then" +
" redis.call('expire',KEYS[1],ARGV[2]) return 1 else return 0 end";
Object result = jedis.eval(lua_scripts, Collections.singletonList(key_resource_id), Collections.singletonList(values));
//判断是否成功
return result.equals(1L);
Redis 分布式锁方案四:SET 的扩展命令(SET EX PX NX)
-
除了使用 Lua 脚本,保证 SETNX + EXPIRE 两条指令的原子性,我们还可以使用 Redis 的 SET 指令扩展参数(SET key value [EX seconds] [PX milliseconds] [NX|XX]),它也是原子性的
SET key value[EX seconds][PX milliseconds][NX|XX]- NX :表示key不存在的时候,才能set成功,也即保证只有第一个客户端请求才能获得锁,而其他客户端请求只能等其释放锁,才能获取。
- EX seconds :设定key的过期时间,时间单位是秒。
- PX milliseconds: 设定key的过期时间,单位为毫秒
- XX: 仅当key存在时设置值
-
伪代码 demo 如下:
if(jedis.set(key_resource_id, lock_value, "NX", "EX", 100s) == 1){ //加锁
try {
do something //业务处理
}catch(){
}
finally {
jedis.del(key_resource_id); //释放锁
}
}
-
但是这个方案还存在一下问题:
-
问题一:「锁过期释放了,业务还没执行完」。假设线程a获取锁成功,一直在执行临界区的代码。但是100s过去后,它还没执行完。但是,这时候锁已经过期了,此时线程b又请求过来。显然线程b就可以获得锁成功,也开始执行临界区的代码。那么问题就来了,临界区的业务代码都不是严格串行执行的啦。
-
问题二:「锁被别的线程误删」。假设线程a执行完后,去释放锁。但是它不知道当前的锁可能是线程b持有的(线程a去释放锁时,有可能过期时间已经到了,此时线程b进来占有了锁)。那线程a就把线程b的锁释放掉了,但是线程b临界区业务代码可能都还没执行完呢。
-
Redis 分布式锁方案五:SET EX PX NX + 校验唯一随机值,再删除
既然锁可能被别的线程误删,那我们给value值设置一个标记当前线程唯一的随机数,在删除的时候,校验一下。
伪代码如下:
if(jedis.set(key_resource_id, uni_request_id, "NX", "EX", 100s) == 1){ //加锁
try {
do something //业务处理
}catch(){
}
finally {
//判断是不是当前线程加的锁,是才释放
if (uni_request_id.equals(jedis.get(key_resource_id))) {
jedis.del(lockKey); //释放锁
}
}
}
在这里,**「判断是不是当前线程加的锁」和「释放锁」**不是一个原子操作。如果调用jedis.del()释放锁的时候,可能这把锁已经不属于当前客户端,会解除他人加的锁。

为了更严谨,一般也是用lua脚本代替。lua脚本如下:
if redis.call('get',KEYS[1]) == ARGV[1] then
return redis.call('del',KEYS[1])
else
return 0
end;
Redis分布式锁方案六:Redisson框架
方案五还是可能存在**「锁过期释放,业务没执行完」**的问题。有些小伙伴认为,稍微把锁过期时间设置长一些就可以啦。其实我们设想一下,是否可以给获得锁的线程,开启一个定时守护线程,每隔一段时间检查锁是否还存在,存在则对锁的过期时间延长,防止锁过期提前释放。
当前开源框架Redisson解决了这个问题。我们一起来看下Redisson底层原理图吧:
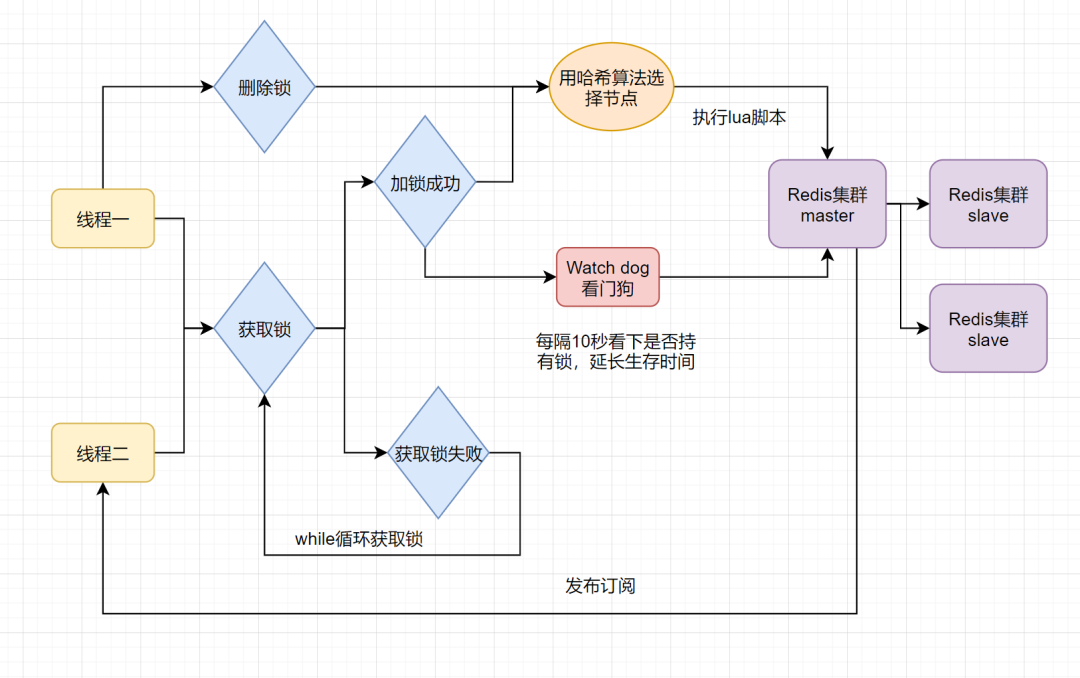
只要线程一加锁成功,就会启动一个watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果线程1还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用Redisson解决了**「锁过期释放,业务没执行完」**问题。
Redis分布式锁方案七:多机实现的分布式锁Redlock+Redisson
前面六种方案都只是基于单机版的讨论,还不是很完美。其实Redis一般都是集群部署的:
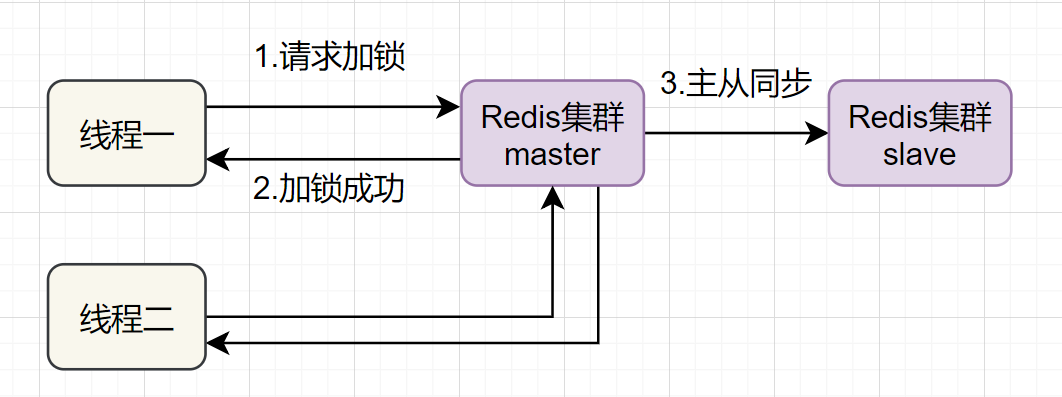
如果线程一在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。线程二就可以获取同个key的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。
为了解决这个问题,Redis作者 antirez提出一种高级的分布式锁算法:Redlock。Redlock核心思想是这样的:
搞多个Redis master部署,以保证它们不会同时宕掉。并且这些master节点是完全相互独立的,相互之间不存在数据同步。同时,需要确保在这多个master实例上,是与在Redis单实例,使用相同方法来获取和释放锁。
我们假设当前有5个Redis master节点,在5台服务器上面运行这些Redis实例。
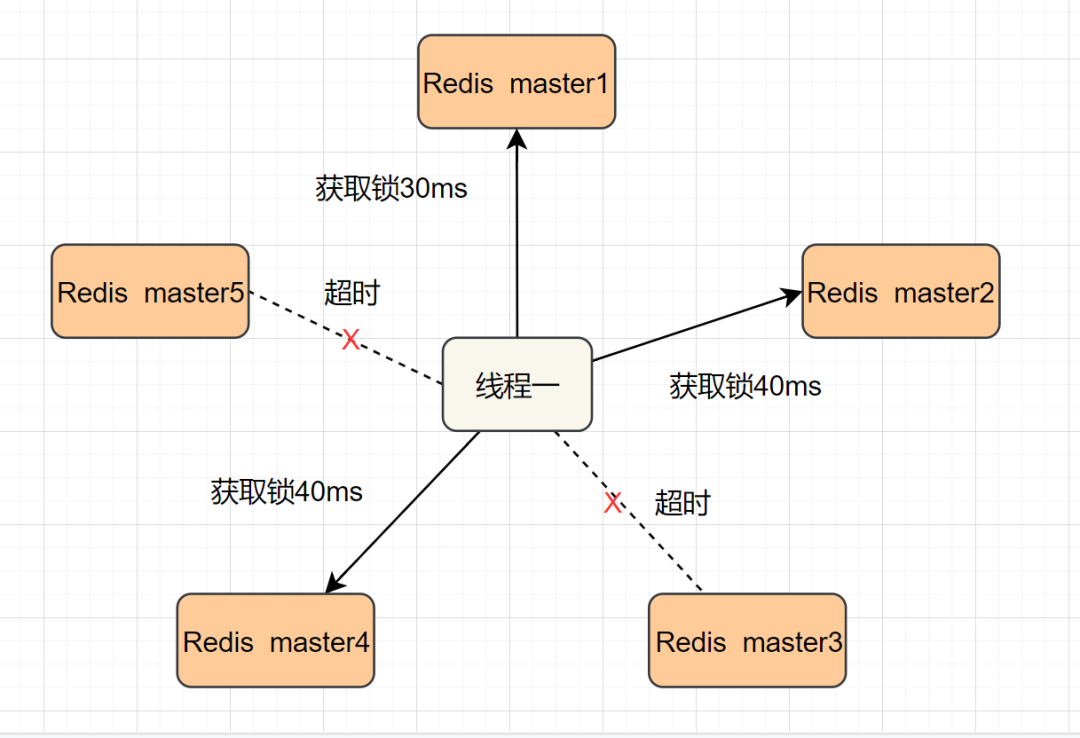
RedLock的实现步骤如下:
- 1.获取当前时间,以毫秒为单位。
- 2.按顺序向5个master节点请求加锁。客户端设置网络连接和响应超时时间,并且超时时间要小于锁的失效时间。(假设锁自动失效时间为10秒,则超时时间一般在5-50毫秒之间,我们就假设超时时间是50ms吧)。如果超时,跳过该master节点,尽快去尝试下一个master节点。
- 3.客户端使用当前时间减去开始获取锁时间(即步骤1记录的时间),得到获取锁使用的时间。当且仅当超过一半(N/2+1,这里是5/2+1=3个节点)的Redis master节点都获得锁,并且使用的时间小于锁失效时间时,锁才算获取成功。(如上图,10s> 30ms+40ms+50ms+4m0s+50ms)
- 如果取到了锁,key的真正有效时间就变啦,需要减去获取锁所使用的时间。
- 如果获取锁失败(没有在至少N/2+1个master实例取到锁,有或者获取锁时间已经超过了有效时间),客户端要在所有的master节点上解锁(即便有些master节点根本就没有加锁成功,也需要解锁,以防止有些漏网之鱼)。
简化下步骤就是:
- 按顺序向5个master节点请求加锁
- 根据设置的超时时间来判断,是不是要跳过该master节点。
- 如果大于等于3个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功啦。
- 如果获取锁失败,解锁!
来源:
https://www.cnblogs.com/wangyingshuo/p/14510524.html















 338
338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









