







假设接收到一串gbk的字节流,应该如何将其转换为unicode
这种情况是比较好解决的,例如,'我'的gbk编码是CED2,那么这个使用两个字节存储的,第一个字节是0xCE,第二个字节是0xD2,这样就有:
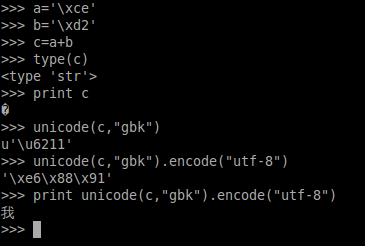
这样就可以得到utf-8的硬编码字符,关于encode,decode的方法,可以看其他的。
另外就是,假设不是这种情况,就是如果给你的是已经是unicode编码,但是却只是把gbk的每个字节转为unicode码,这种情况下就没有办法使用上面的方法了,例如上面的例子一样,如果a=u'\xce',b=u'\xd2'那么下面的调用就会出错。所以需要先将unicode先转化为str,但是这种方法也是不能够直接转换的,会出现如下的错误:

所以,需要从将其转化为bytes,这种转化方法是结合bytearray和buffer,然后再进行unicode编码,如下所示:
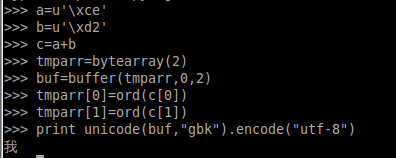
至于bytearray和buffer的用法,再上网查查。这个应该可以解决了很大一部分编码问题了。















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









