






一、栈的概念及其结构
1、栈
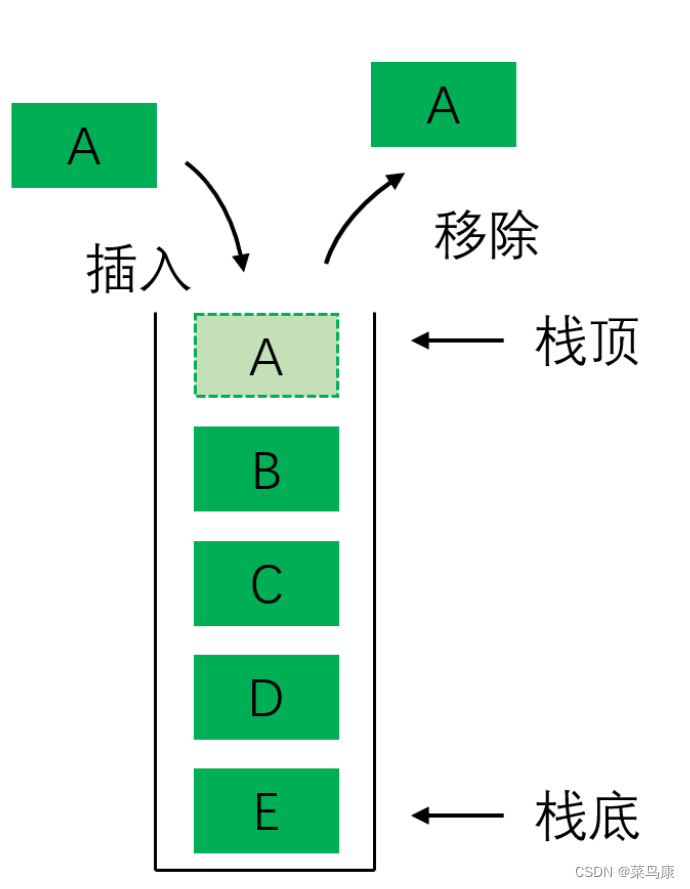
栈是一种的特殊的线性表,只允许在固定的一端进行插入和删除操作。进行插入和删除操作的一端称为栈顶,另一端称为栈底。栈里面的元素遵守后进先出(LIFO)的规则。
2、压栈及出栈
在栈顶插入数据叫做压栈,在栈顶删除数据叫出栈。
二、栈的实现
栈的实现一般可以用数组或者链表,但是相对于链表来说,数组的结构对于栈的实现更优一些,因为 数组的在尾上插入数据比链表的插入的代价小。
在结构体中,我们给出三个结构体变量,数组、栈顶下标(因为我们压栈和出栈操作都是从栈顶)和栈的容量(方便扩容)
1、头文件
#pragma once
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
typedef int STDataType;
typedef struct Stack
{
STDataType* _a;//标准化书写,结构体成员变量前边下划线
int _top;//栈顶下标
int _capacity;//容量
}Stack;
void StackInit(Stack* pst);//初始化栈
void StackDestroy(Stack* pst);//销毁栈
void StackPush(Stack* pst, STDataType x);//入栈
void StackPop(Stack* pst);//出栈
int StackSize(Stack* pst);//1、为了保持接口的一致性 2、结构体若太大,传指针好些
int StackEmpty(Stack* pst);//返回1则表示栈空,返回0表示栈非空
STDataType StackTop(Stack* pst);//获取栈顶的元素2、初始化
void StackInit(Stack * pst)//初始化栈
{
assert(pst);
pst->_a = (STDataType*)malloc(sizeof(STDataType) * 4);
pst->_top = 0;
pst->_capacity = 4;
}3、销毁栈
void StackDestroy(Stack* pst)//销毁栈
{
assert(pst);
free(pst->_a);
pst->_a = NULL;
pst->_top = pst->_capacity = 0;
}4、 入栈
void StackPush(Stack* pst, STDataType x)//入栈
{
assert(pst);
if (pst->_top == pst->_capacity)
{
//增容
pst->_capacity *= 2;
STDataType* tmp = (STDataType*)realloc(pst->_a, sizeof(STDataType) * pst->_capacity);
if (tmp == NULL)
{
printf("增容失败\n");
exit(-1);
}
else
{
pst->_a = tmp;
}
}
pst->_a[pst->_top] = x;
pst->_top++;
}5、出栈
通过直接让其栈顶指针减一找不到原来的栈顶元素即可。
void StackPop(Stack* pst)//出栈
{
assert(pst);
assert(pst->_top > 0);
--pst->_top;
}6、栈的大小
int StackSize(Stack* pst)//1、为了保持接口的一致性 2、结构体若太大,传指针好些
{
assert(pst);
return pst->_top;
}7、是否非空
int StackEmpty(Stack* pst)//返回1则表示栈空,返回0表示栈非空
{
assert(pst);
return pst->_top == 0 ? 1 : 0;
}8、返回栈顶元素
STDataType StackTop(Stack* pst)//获取栈顶的元素
{
assert(pst);
assert(pst->_top > 0);
return pst->_a[pst->_top - 1];
}














 3268
3268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









