




 本文介绍如何使用PostgreSQL ROLLUP生成多组集合。ROLLUP是group by的子句,用于生成分组集合的快捷功能。与Cube子句不同,ROLLUP假设输入列间存在层次结构,生成有意义的所有分组集合。文章通过实例展示了如何生成报表小计和总计。
本文介绍如何使用PostgreSQL ROLLUP生成多组集合。ROLLUP是group by的子句,用于生成分组集合的快捷功能。与Cube子句不同,ROLLUP假设输入列间存在层次结构,生成有意义的所有分组集合。文章通过实例展示了如何生成报表小计和总计。
PostgreSQL ROLLUP教程
本文介绍如何使用PostgreSQL ROLLUP生成多组集合。
概述
PostgreSQL ROLLUP 是group by 的子句,是生成多个分组集合的快捷功能。与Cube子句的差异是,rollup 不生成基于特定列所有可能的分组集合,生成分组集合为其子集。
ROLLUP假设输入列之间存在层次结构,从而生成有意义的所有分组集合。这就是为什么ROLLUP经常用于生成报表的小计和总计。
举例,cube (c1,c2,c3)生成所有8中可能:
(c1, c2, c3)
(c1, c2)
(c2, c3)
(c1,c3)
(c1)
(c2)
(c3)
()
而ROLLUP(c1,c2,c3)仅生成4种分组集合,假设层级c1 > c2 > c3:
(c1, c2, c3)
(c1, c2)
(c1)
()
rollup通常用于按年、月、日计算数值合计,因为日期有层次 年>月>日。
下面描述其语法:
SELECT
c1,
c2,
c3,
aggregate(c4)
FROM
table_name
GROUP BY
ROLLUP (c1, c2, c3);
也可以部分上卷,从而减少生成子集的数量:
SELECT
c1,
c2,
c3,
aggregate(c4)
FROM
table_name
GROUP BY
c1,
ROLLUP (c2, c3);
PostgreSQL ROLLUP示例
下面查询使用rollup子句查询销售产品数量,根据品牌及品牌分段进行分组聚集:
SELECT
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
ROLLUP (brand, segment)
ORDER BY
brand,
segment;
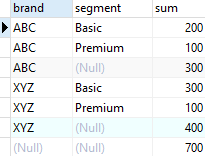
图1
从输出结果可以看到,三行显示ABC品牌的销售数量,接下来是XYZ产品的销售数量,最后一行显示所有品牌的所有分段的销售数量。本示例中的层次是品牌>分段。
如果你改变两者顺序,结果不同:
SELECT
segment,
brand,
SUM (quantity)
FROM
sales
GROUP BY
ROLLUP (segment, brand)
ORDER BY
segment,
brand;
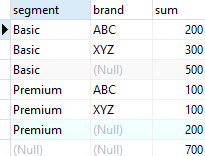
图2
这种情况,层次为分段>品牌。
下面语句执行部分上卷:
SELECT
segment,
brand,
SUM (quantity)
FROM
sales
GROUP BY
segment,
ROLLUP (brand)
ORDER BY
segment,
brand;
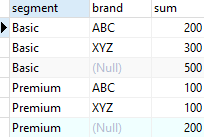
图3
下面我们看另一个表的上卷操作,示例表结构如下:

图4
下面语句查询每年、月、日的租借数量:
SELECT
EXTRACT (YEAR FROM rental_date) y,
EXTRACT (MONTH FROM rental_date) M,
EXTRACT (DAY FROM rental_date) d,
COUNT (rental_id)
FROM
rental
GROUP BY
ROLLUP (
EXTRACT (YEAR FROM rental_date),
EXTRACT (MONTH FROM rental_date),
EXTRACT (DAY FROM rental_date)
);
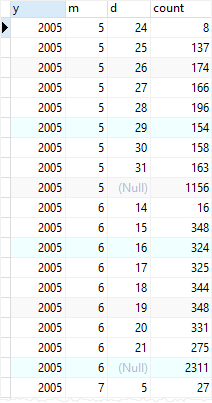
图5
总结
本文我们已经学习PostgreSQL ROLLUP分组子句,通过示例展示如何生成多组集合。

















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









