






MySQL 中的分析函数在8.0以上版本才支持,8.0以下较低版本可以通过group by 加变量的方式实现类似以下分析函数的功能:row_number()over()、rank()over、dence_rank()over()
-- 1.测试数据建表
CREATE TABLE `my_test_ranking` (
`ID` int NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`city_name` varchar(255) DEFAULT NULL COMMENT '地市',
`county_name` varchar(255) DEFAULT NULL COMMENT '区县',
`month` varchar(6) DEFAULT NULL COMMENT '年月',
`sales` int DEFAULT NULL COMMENT '销售数量',
`create_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '创建日期',
`update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新日期',
PRIMARY KEY (`ID`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='排序排名测试数据';
COMMIT;
-- 2.测试数据
INSERT INTO `my_test_ranking` (`ID`, `city_name`, `county_name`, `month`, `sales`, `create_time`, `update_time`) VALUES (1, '济南市', '天桥区', '202301', 100, '2023-04-28 10:27:56', '2023-04-28 10:27:56');
INSERT INTO `my_test_ranking` (`ID`, `city_name`, `county_name`, `month`, `sales`, `create_time`, `update_time`) VALUES (2, '济南市', '历城区', '202301', 200, '2023-04-28 10:27:58', '2023-04-28 10:27:58');
INSERT INTO `my_test_ranking` (`ID`, `city_name`, `county_name`, `month`, `sales`, `create_time`, `update_time`) VALUES (3, '济南市', '历下区', '202301', 150, '2023-04-28 10:28:00', '2023-04-28 10:28:00');
INSERT INTO `my_test_ranking` (`ID`, `city_name`, `county_name`, `month`, `sales`, `create_time`, `update_time`) VALUES (4, '青岛市', '市南区', '202301', 210, '2023-04-28 10:28:03', '2023-04-28 10:28:03');
INSERT INTO `my_test_ranking` (`ID`, `city_name`, `county_name`, `month`, `sales`, `create_time`, `update_time`) VALUES (5, '青岛市', '市北区', '202302', 160, '2023-04-28 10:28:05', '2023-04-28 10:28:05');
INSERT INTO `my_test_ranking` (`ID`, `city_name`, `county_name`, `month`, `sales`, `create_time`, `update_time`) VALUES (6, '青岛市', '城阳区', '202302', 152, '2023-04-28 10:28:07', '2023-04-28 10:28:07');
INSERT INTO `my_test_ranking` (`ID`, `city_name`, `county_name`, `month`, `sales`, `create_time`, `update_time`) VALUES (7, '潍坊市', '奎文区', '202302', 111, '2023-04-28 10:28:09', '2023-04-28 10:28:09');
INSERT INTO `my_test_ranking` (`ID`, `city_name`, `county_name`, `month`, `sales`, `create_time`, `update_time`) VALUES (8, '潍坊市', '诸城市', '202301', 146, '2023-04-28 10:28:11', '2023-04-28 10:28:11');
INSERT INTO `my_test_ranking` (`ID`, `city_name`, `county_name`, `month`, `sales`, `create_time`, `update_time`) VALUES (9, '临沂市', '沂水县', '202301', 180, '2023-04-28 10:28:17', '2023-04-28 10:28:17');
INSERT INTO `my_test_ranking` (`ID`, `city_name`, `county_name`, `month`, `sales`, `create_time`, `update_time`) VALUES (10, '济南市', '历下区', '202301', 199, '2023-04-28 10:28:17', '2023-04-28 10:28:17');
INSERT INTO `my_test_ranking` (`ID`, `city_name`, `county_name`, `month`, `sales`, `create_time`, `update_time`) VALUES (11, '济南市', '历下区', '202301', 199, '2023-04-28 10:28:17', '2023-04-28 10:28:17');
INSERT INTO `my_test_ranking` (`ID`, `city_name`, `county_name`, `month`, `sales`, `create_time`, `update_time`) VALUES (12, '临沂市', '沂南县', '202301', 180, '2023-04-28 10:28:17', '2023-04-28 10:28:17');commit;
-- 3.测试sql
-- 3.1.普通的排序递增/递减 -- 这种实现方式相当于 Oracle的 伪列 rowrank
set @rank := 0;
select @rank := @rank + 1 as rk, t1.* from my_test_ranking t1 order by sales desc;-- 等价SQL
select @rank := @rank + 1 as rk, t1.* from my_test_ranking t1, (select @rank := 0) t2
order by sales desc;

-- 3.2普通排序。相同数值排名相同,不占空位。-- 逻辑实现类似 Oracle 的dence_rank()over()
set @rank := 0, @sales := '';
select t1.*
,@rank := if(@sales = sales, @rank, @rank+1) as rk -- 销量相同则排名相同、不同加一
,@sales := sales as sales2
from my_test_ranking t1
order by sales desc ;

-- 3.3普通排序。组内相同数值排名相同,需要占空位。-- 逻辑实现类似 Oracle 的rank()over()
set @rank0 := 0, @rank := 0, @sales := '';
select t1.*
,@rank0 := @rank0 + 1 as rk0 -- 中间变量保存组内增量数值
,@rank := if(@sales = sales, @rank, @rank0) as rk -- 销量相同则排名相同、不同跳位
,@sales := sales as sales2
from my_test_ranking t1
order by sales desc ;

-- 3.4.实现分组递增, -- 该逻辑实现方式类似于 Oracle 中的开窗函数 row_rankber()over()
set @rank := 0, @city := '';
select t1.*, @rank := if(@city = city_name, @rank+1, 1) as rk, @city := city_name as city_name from my_test_ranking t1
order by city_name, sales desc ;-- 等价SQL
select t1.*
,@rank := if(@city = city_name, @rank + 1, 1) as rk
-- ,@rank := case when @city = city_name then @rank + 1 else 1 end as rank -- 等价上边的函数
,@city := city_name as city_name2from my_test_ranking t1, (select @rank := 0, @city := '') t2
order by city_name, sales desc;
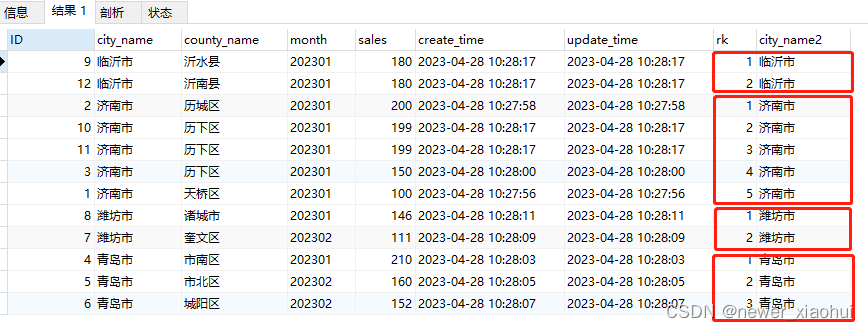
-- 3.5.分组排名。组内相同数值排名相同,不占空位。-- 逻辑实现类似 Oracle 的dence_rank()over()
set @rank := 0, @city := '', @sales := '';
select t1.*
,@rank := if(@city = city_name, if(@sales = sales, @rank, @rank+1), 1) as rk -- 城市相同则组内排名,(又销量相同则排名相同、不同加一),城市不同从 1 开始排名
,@city := city_name as city_name2
,@sales := sales as sales2
from my_test_ranking t1
order by city_name, sales desc ;
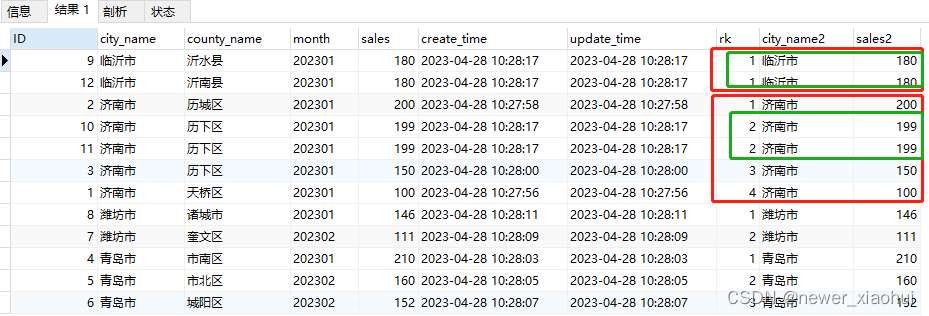
-- 3.6.分组排名。组内相同数值排名相同,需要占空位。-- 逻辑实现类似 Oracle 的rank()over()
set @rank := 0, @rank0 := 0, @city := '', @sales := '';
select t1.*
,@rank0 := if(@city = city_name, @rank0 + 1, 1) as rk0 -- 中间变量保存组内增量数值
,@rank := if(@city = city_name, if(@sales = sales, @rank, @rank0), 1) as rk -- 城市相同则组内排名,(又销量相同则排名相同、不同跳位),城市不同从 1 开始排名
,@city := city_name as city_name2
,@sales := sales as sales2
from my_test_ranking t1
order by city_name, sales desc ;

-- 注意事项:
-- 1.MySQL中符号@的作用:变量名,如果你不加的话,会认为这是一个列名,但是这列不存在,就报错了;
-- 2.@变量名 : 定义一个用户变量.
-- = 对该用户变量进行赋值.
-- 用户变量赋值有两种方式: 一种是直接用"=“号,另一种是用”:=“号。
--
-- 其区别在于:
-- 使用set命令对用户变量进行赋值时,两种方式都可以使用;
-- 用select语句时,只能用”:=“方式,因为select语句中,”="号被看作是比较操作符。-- 3.注意 select 中字段的顺序,从前往后解析,特别是变量的位置,前面的变量先赋值














 734
734











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









