









我们今天又来分析算子的具体实现了,如果只是知道一个方法的是干什么的,对于作用比较相似的方法我们很难分辨应该具体用什么,所以懂了具体的原理,我们就知道在具体业务场景下应用哪个方法更好
reduceByKey:
参数:func, [numTasks]
作用:在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置
aggregateByKey:
参数:(zeroValue:U,[partitioner: Partitioner]) (seqOp: (U, V) => U,combOp: (U, U) => U)
作用:在kv对的RDD中,,按key将value进行分组合并,合并时,将每个key的第一个value和初始值作为seq函数的参数,进行计算,返回的结果作为一个新的kv对,然后再将结果按照key进行合并,最后将每个分组的value传递给combine函数进行计算(先将前两个value进行计算,将返回结果和下一个value传给combine函数,以此类推),将key与计算结果作为一个新的kv对输出
foldByKey:
参数:(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
作用:aggregateByKey的简化操作,seqop和combop相同
combineByKey:
参数:(createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C)
我们追踪这四个方法的源码发现最后都是调用的同一个方法
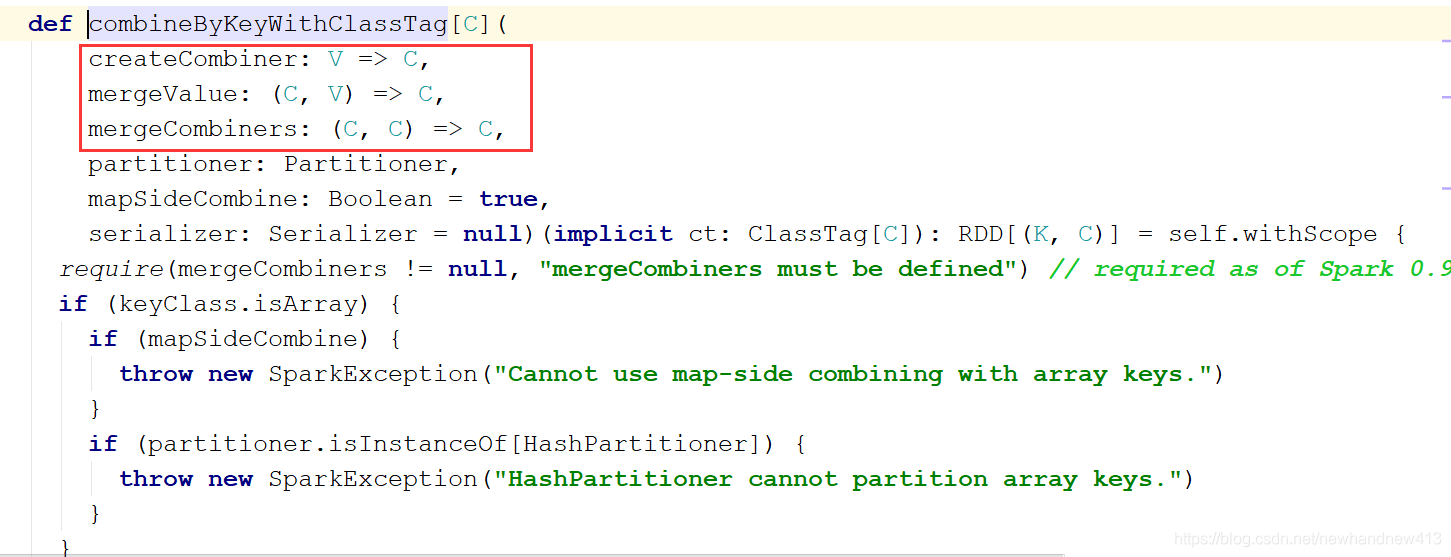
这三个参数的意思是:
(1)createCombiner: 表示的是将相同key第一次出现的value的转换操作
(2)mergeValue: 分区内数据的计算规则
(3)mergeCombiners: 分区间数据的计算规则
我们依次追踪四个方法到距离这个方法最近的源码内部:
reduceByKey:

我们看到reduceByKey方法调用这个方法没对value值进行任何操作,并且分区内和分区间的计算规则都是调用的我们传入的那个计算规则
aggregateByKey:
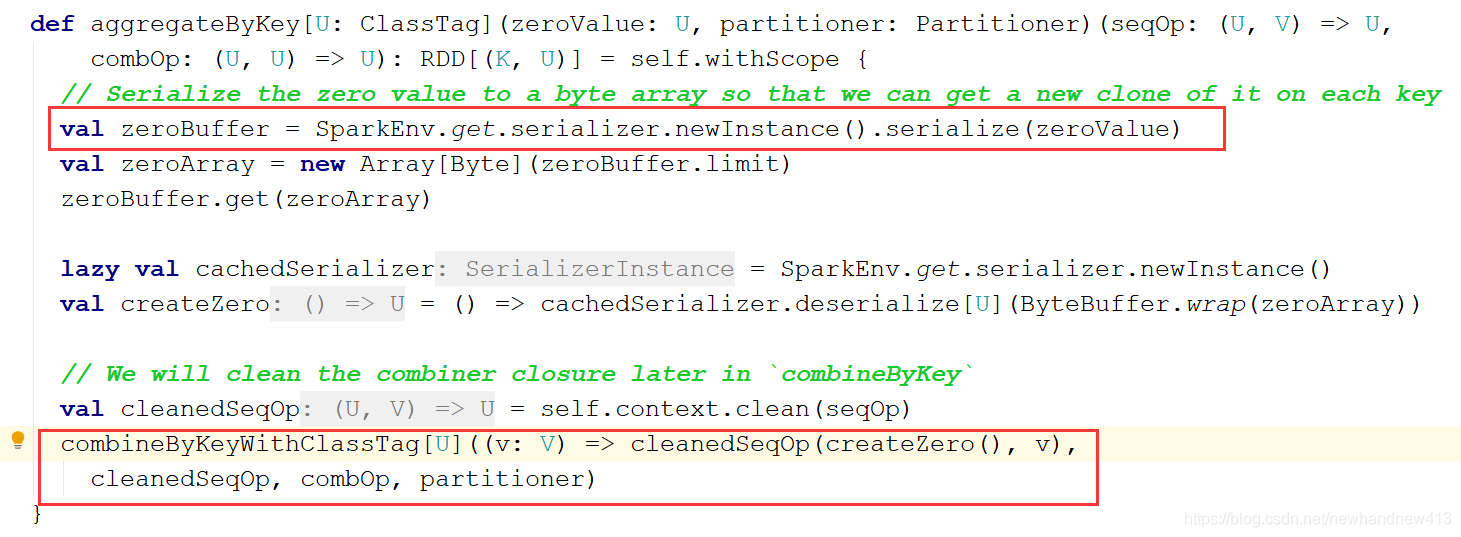
我们看到将我们传入的第一个参数进行一个序列化等包装操作,将分区内的计算规则进行了包装,我们也能看到会将我们传入的初始值用分区内的计算规则先进行一次操作
foldByKey:
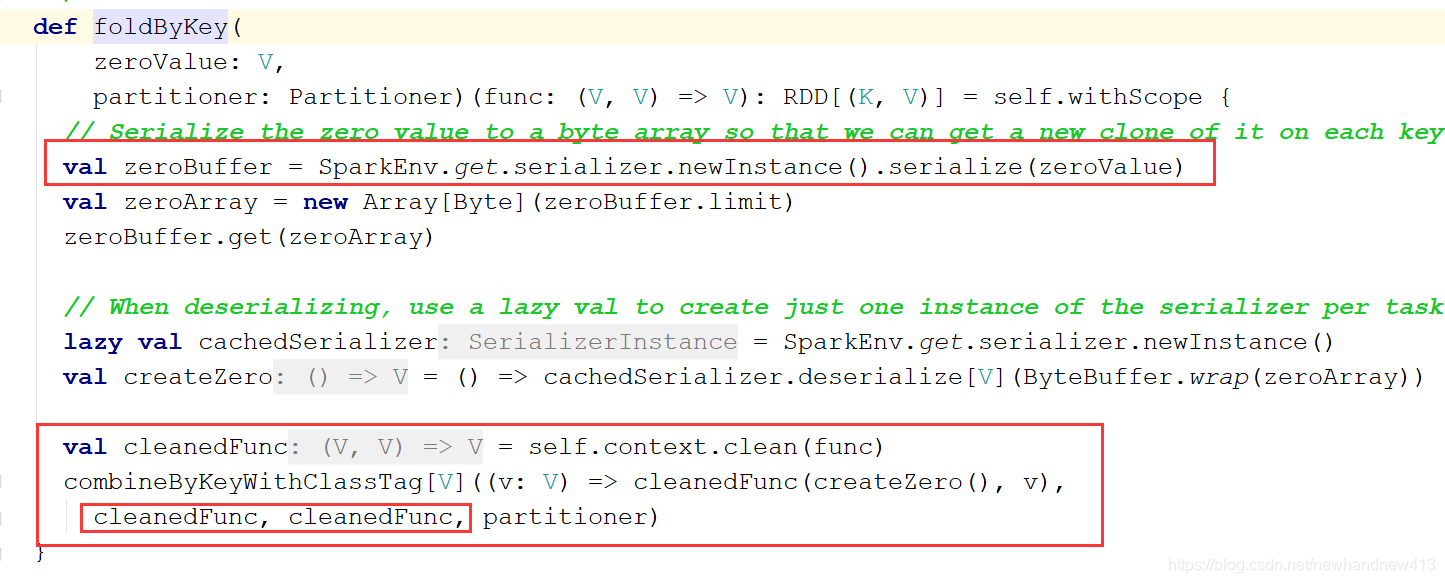
我们看到和aggregateByKey是一样的,只是分区内计算规则和分区间的计算规则都是调用的一样的而已
最后我们总结一下:
reduceByKey:是不改变value值,分区内计算规则和分区间计算规则一样
aggregateByKey:是需要有一个初始值,将初始值用分区内计算规则操作一遍,之后再做分区内计算,再做分区间计算
foldByKey:是简化的aggregateByKey,分区内计算规则和分区间计算规则一样
combineByKey:是需要将value的结构改变之后,再进行分区内计算,最后进行分区间计算














 1116
1116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









