







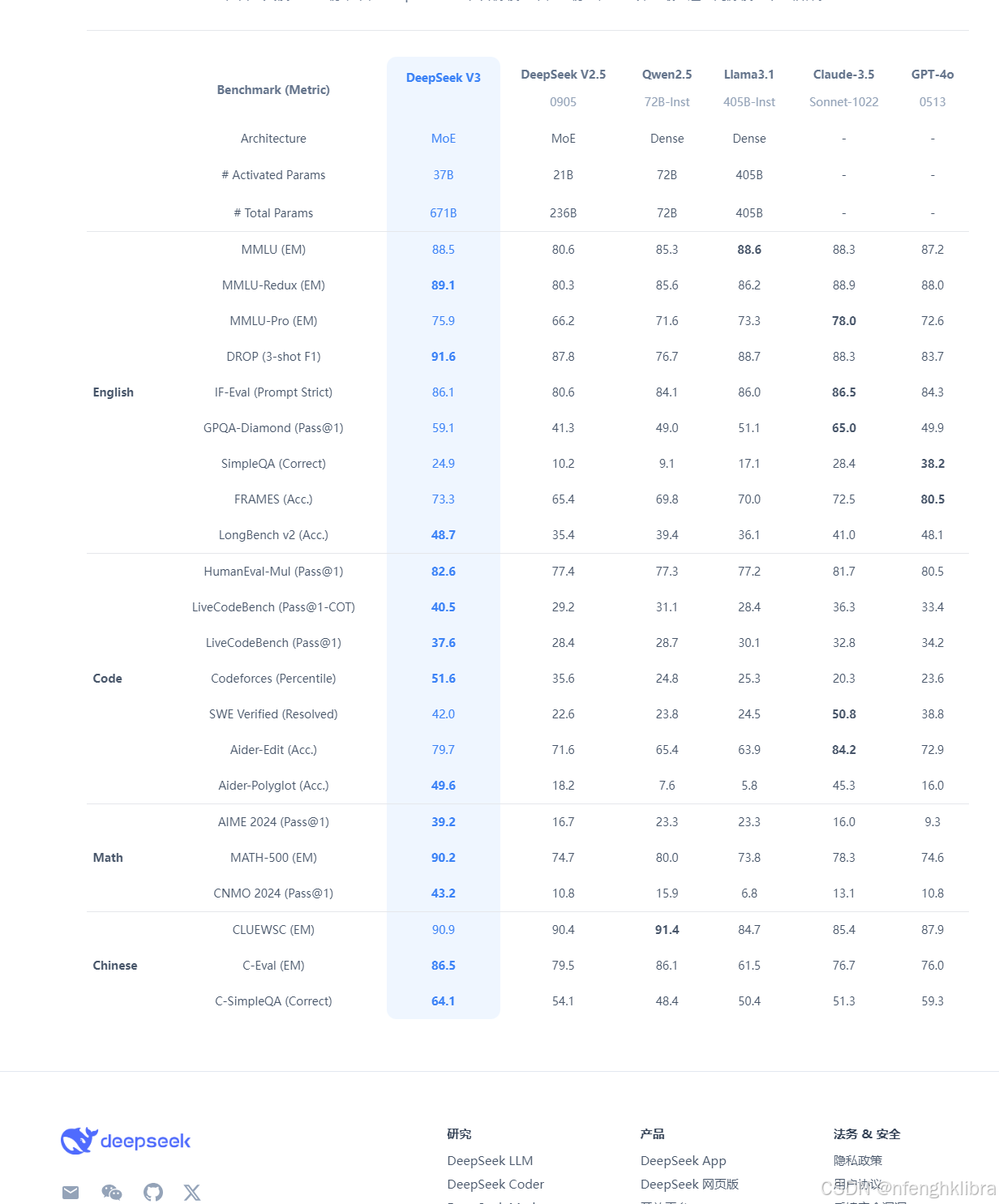
图中的参数和指标代表了不同模型在多个基准测试中的性能表现。以下是对各列和指标的详细解释:
---
### **模型列**
1. **DeepSeek V3**:DeepSeek 的最新版本模型。
2. **DeepSeek V2.5**:DeepSeek 的上一版本模型。
3. **Qwen2.5**:另一个模型(可能是竞争对手或开源模型)。
4. **Llama3.1**:Meta 的 Llama 系列模型的一个版本。
5. **Claude-3.5**:Anthropic 的 Claude 模型的一个版本。
6. **GPT-4o**:OpenAI 的 GPT-4 模型的一个版本。
---
### **参数列**
1. **Architecture**:模型架构。
- **MoE**:Mixture of Experts(专家混合模型)。
- **Dense**:密集模型(标准神经网络架构)。
2. **# Activated Params**:激活参数数量(单位:B 表示十亿)。
3. **# Total Params**:总参数数量(单位:B 表示十亿)。
---
### **基准测试指标**
1. **MMLU (EM)**:多任务语言理解(Exact Match,精确匹配)。
2. **MMLU-Redux (EM)**:MMLU 的简化版本。
3. **MMLU-Pro (EM)**:MMLU 的专业版本。
4. **DROP (3-shot F1)**:DROP 数据集上的 3-shot F1 分数。
5. **IF-Eval (Prompt Strict)**:指令跟随评估(严格模式)。
6. **GPQA-Diamond (Pass@1)**:GPQA 数据集上的通过率(Pass@1)。
7. **SimpleQA (Correct)**:简单问答的正确率。
8. **FRAMES (Acc.)**:FRAMES 数据集上的准确率。
9. **LongBench v2 (Acc.)**:长文本基准测试的准确率。
10. **HumanEval-Mul (Pass@1)**:多语言 HumanEval 数据集上的通过率。
11. **LiveCodeBench (Pass@1-COT)**:代码生成基准测试(使用 Chain-of-Thought 提示)。
12. **LiveCodeBench (Pass@1)**:代码生成基准测试(标准模式)。
13. **Codeforces (Percentile)**:Codeforces 竞赛中的百分位数。
14. **SWE Verified (Resolved)**:软件工程验证任务中的解决率。
15. **Alder-Edit (Acc.)**:Alder 编辑任务的准确率。
16. **Alder-Polyglot (Acc.)**:Alder 多语言任务的准确率。
17. **AIME 2024 (Pass@1)**:AIME 数学竞赛的通过率。
18. **MATH-500 (EM)**:MATH 数据集上的精确匹配。
19. **CNMO 2024 (Pass@1)**:CNMO 数学竞赛的通过率。
20. **CLUEWSC (EM)**:中文语言理解评估(Exact Match)。
21. **C-Eval (EM)**:中文评估数据集上的精确匹配。
22. **C-SimpleQA (Correct)**:中文简单问答的正确率。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









