









01、什么是Selenium Grid
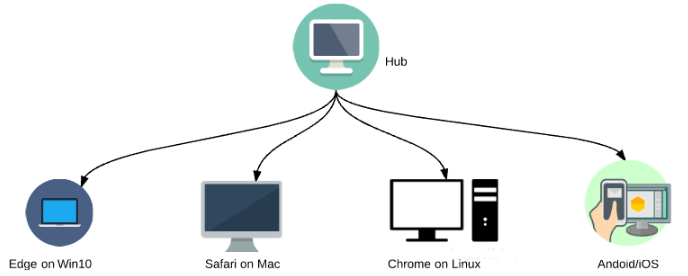
Selenium Grid是Selenium套件的一部分,它专门用于并行运行多个测试用例在不同的浏览器、操作系统和机器上。
Selenium Grid有两个版本——老版本Grid 1和新版本Grid 2。我们只对新版本做介绍,因为Selenium团队已经逐渐遗弃老版本了。
Selenium Grid 主要使用 master-slaves (or hub-nodes) 理念 --一个 master/hub 和多个基于master/hub注册的子节点 slaves/nodes。当我们在master上基于不同的浏览器/系统运行测试用例时,master将会分发给适当的node运行。
什么时候用Selenium Grid
同时在不同的浏览器、操作系统和机器上运行测试。最大程度用于兼容性测试
减少运行时间
02、怎样启动Selenium Grid
启动Selenium Grid的三种方式,一种直接用命令行,另一种用JSON配置文件,最后一种docker启动
01、命令行启动
将会使用2台机器,一台运行hub另一台运行node,为了方便描述,将运行hub的机器命名为“Machine H”(IP:192.168.1.100),运行node的机器命名为“Machine N”(IP:192.168.1.101)
Step 1
、配置Java环境
2、已安装需要运行的浏览器
3、下载浏览器driver,放到和selenium server相同的路径下 ,否则在启动node时要加参数,不然启动不了浏览器(java -Dwebdriver.chrome.driver=“C:\your path\chromedriver.exe” -jar selenium-server-standalone-3.141.59.jar -role node -hub http://192.168.1.100:5566/grid/register/,可切换浏览器)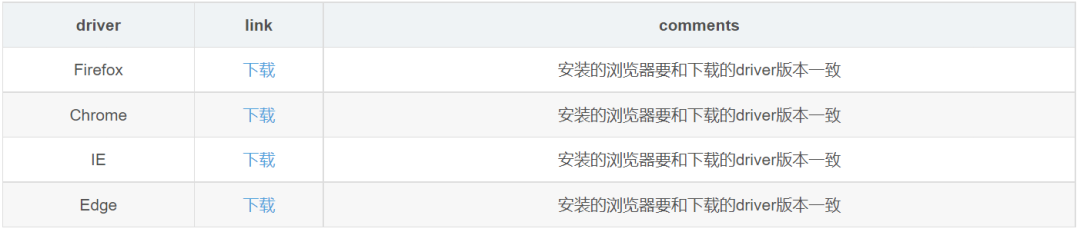
4、下载selenium server,将selenium-server-standalone-X.XX.jar分别放在“Machine H”和“Machine N”上(自定义路径)
Step 2
在机器“Machine H”上打开命令行,到selenium server所在的路径,运行:java -jar selenium-server-standalone-3.141.59.jar -role hub -port 5566,成功启动你会看到:

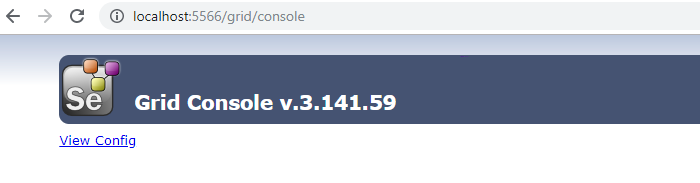
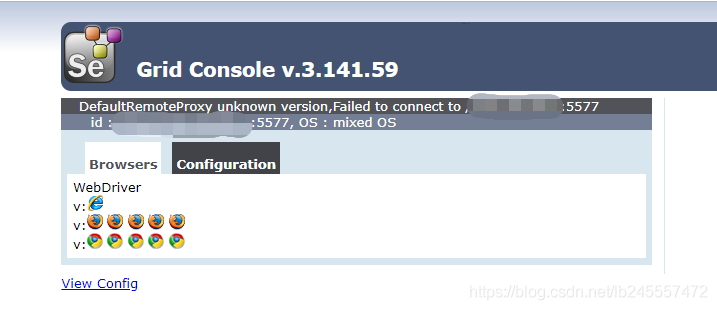
或者直接在机器“Machine H”上的浏览器(“Machine N”则需要将IP修改为“Machine H”的)打开:http://localhost:5566/grid/console ,将会看到:
在机器“Machine N”上打开命令行,到selenium server所在的路径,运行:java -jar selenium-server-standalone-3.141.59.jar -role node -hub http://192.168.1.100:5566/grid/register/ -port 5577,成功启动你会看到:
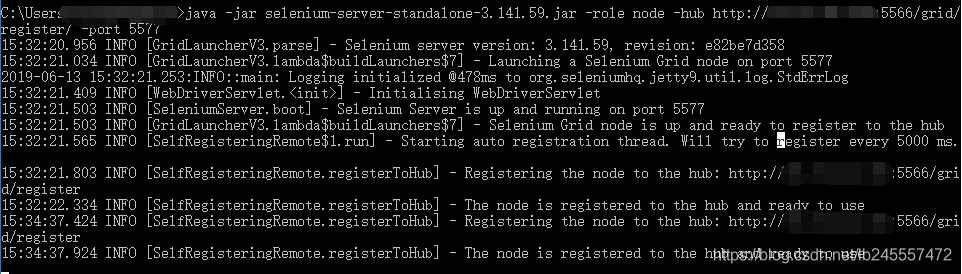
刷新:http://localhost:5566/grid/console ,将会看到:
Step 3
运行测试脚本,将会看到在机器“Machine N”上打开了Chrome浏览器,并运行了测试用例:
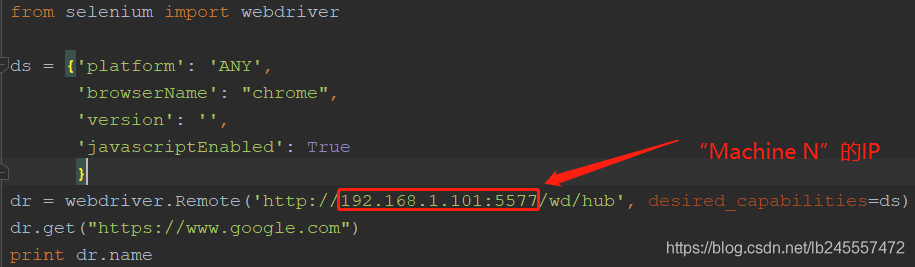
from selenium import webdriver
ds = {'platform': 'ANY',
'browserName': "chrome",
'version': '',
'javascriptEnabled': True
}
dr = webdriver.Remote('http://192.168.1.101:5577/wd/hub', desired_capabilities=ds)
dr.get("https://www.baidu.com")
print dr.name
02、Json配置文件启动
Step 1
1、创建hub的Json配置文件
代码如下:
{
"port": 4444,
"newSessionWaitTimeout": -1,
"servlets" : [],
"withoutServlets": [],
"custom": {},
"capabilityMatcher": "org.openqa.grid.internal.utils.DefaultCapabilityMatcher",
"registry": "org.openqa.grid.internal.DefaultGridRegistry",
"throwOnCapabilityNotPresent": true,
"cleanUpCycle": 5000,
"role": "hub",
"debug": false,
"browserTimeout": 0,
"timeout": 1800
}
将上述代码保存为hub_config.json文件,放在“Machine H”上和selenium server相同的路径下。
2、创建nodes的 Json配置文件
代码如下:
{
"capabilities":
[
{
"browserName": "firefox",
"marionette": true,
"maxInstances": 5,
"seleniumProtocol": "WebDriver"
},
{
"browserName": "chrome",
"maxInstances": 5,
"seleniumProtocol": "WebDriver"
},
{
"browserName": "internet explorer",
"platform": "WINDOWS",
"maxInstances": 1,
"seleniumProtocol": "WebDriver"
},
{
"browserName": "safari",
"technologyPreview": false,
"platform": "MAC",
"maxInstances": 1,
"seleniumProtocol": "WebDriver"
}
],
"proxy": "org.openqa.grid.selenium.proxy.DefaultRemoteProxy",
"maxSession": 5,
"port": -1,
"register": true,
"registerCycle": 5000,
"hub": "http://192.168.1.100:4444",
"nodeStatusCheckTimeout": 5000,
"nodePolling": 5000,
"role": "node",
"unregisterIfStillDownAfter": 60000,
"downPollingLimit": 2,
"debug": false,
"servlets" : [],
"withoutServlets": [],
"custom": {}
}
保存为文件(注意将hub对应的值改为机器“Machine H”的IP),放在“Machine N”上和selenium server相同的路径下。(当多个node时需将该文件放在多个node机器上或者同一个机器上启动多个node)
Step 2
hub机器上命令行运行:java -jar selenium-server-standalone-3.141.59.jar -role hub -hubConfig hub_config.json
node机器上命令行运行:java -jar selenium-server-standalone-3.141.59.jar -role node -nodeConfig node_config.json
运行之前的验证方法和脚本查看是否正确
(1、2)方式启动的挑战(不易启动和维护):
每个node需要下载和配置依赖
java 进程占内存
出现问题时需手动启动
不易维护
扩展性差
03、docker启动
docker上已经有selenium官方的Selenium Grid镜像,只有你已经安装了docker,即可使用。
启动hub:
docker run -d -p 4444:4444 --name selenium-hub selenium/hub
启动node(Chrome&&Firefox):
docker run -d --link selenium-hub:hub selenium/node-firefox
运行命令将会下载内置镜像文件(包括java、Chrome、Firefox、selenium-server-standalone-XXX.jar 等运行selenium所需的环境);此时你可以访问:http://localhost:4444/grid/console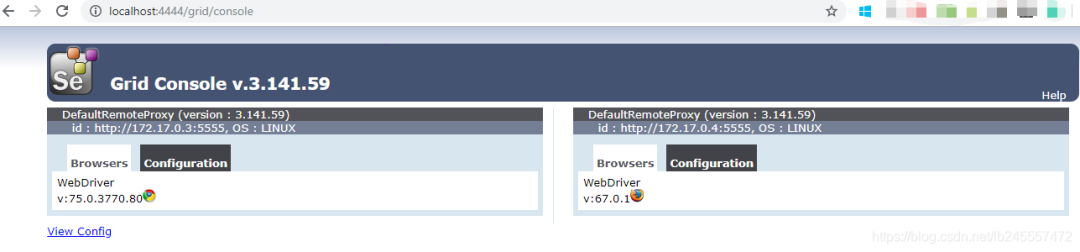
如果需要多个Chrome node则继续运行这个命令:docker run -d --link selenium-hub:hub selenium/node-chrome,刷新则看到多了一个Chrome实例。
通过运行命令:docker ps,显示正在运行的容器
关闭docker-grid的命令:docker stop $(docker ps -a -q), docker rm $(docker ps -a -q)
1、docker 组件启动Selenium Grid
selenium Grid通常需要启动一个hub,多个nodes像Chrome、Firefox等。我们可以把他们定义到一个文件中叫做docker-compose.yml,通过一个命令来整体启动,docker提供了一个这样的工具 –Docker-Compose。
安装docker-compose,一旦安装成功,则创建一个新的文件夹,创建文件 docker-compose.yml, docker-compose.yml内容:
version: "3"
services:
selenium-hub:
image: selenium/hub
container_name: selenium-hub
ports:
- "4444:4444"
chrome:
image: selenium/node-chrome
depends_on:
- selenium-hub
environment:
- HUB_PORT_4444_TCP_ADDR=selenium-hub
- HUB_PORT_4444_TCP_PORT=4444
firefox:
image: selenium/node-firefox
depends_on:
- selenium-hub
environment:
- HUB_PORT_4444_TCP_ADDR=selenium-hub
- HUB_PORT_4444_TCP_PORT=4444
2、docker-compose命令:
运行命令启动(到docker-compose.yml路径下):docker-compose up -d
查看启动是否成功:docker-compose ps
创建更多实例:docker-compose scale chrome=5
关闭命令:docker-compose down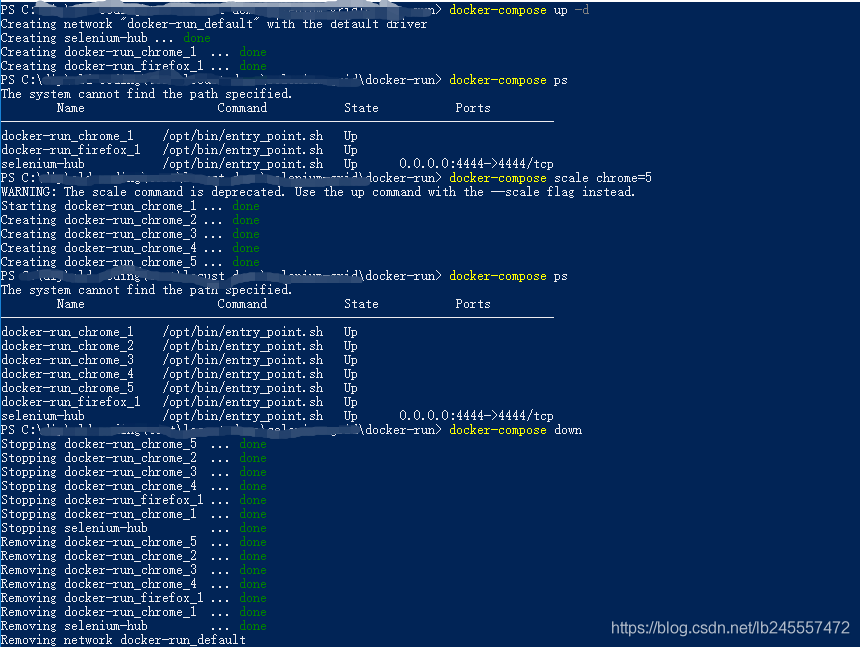
浏览器打开http://localhost:4444/grid/console将会看到:
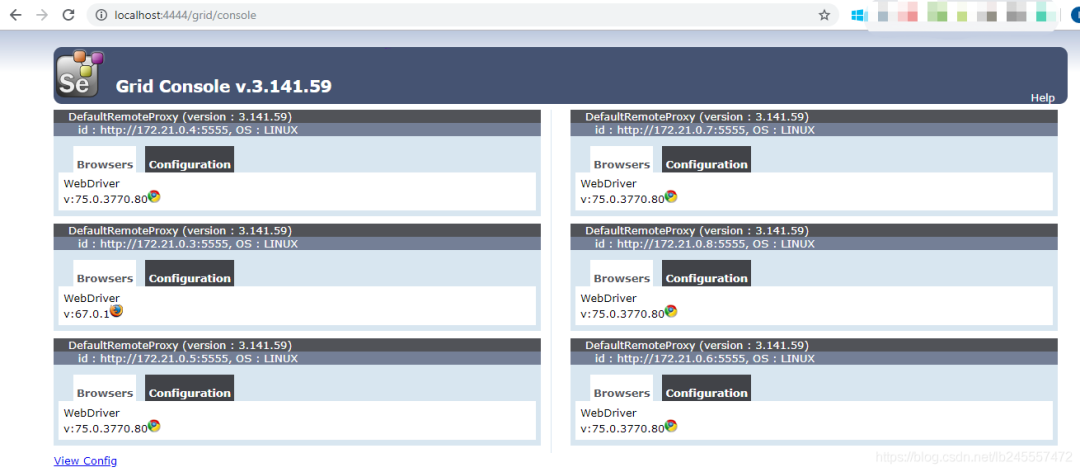
运行脚本的话直接运行就好(IP:http://localhost:4444/wd/hub) ,和上边两种的方法不太一样;不会有浏览器打开(容器内部运行),但是已经运行成功:
import unittest
from selenium import webdriver
class MyTestCase(unittest.TestCase):
def setUp(self):
ds = {'platform': 'ANY',
'browserName': "chrome",
'version': '',
'javascriptEnabled': True
}
self.dr = webdriver.Remote('http://localhost:4444/wd/hub', desired_capabilities=ds)
def test_something(self):
self.dr.get("https://www.baidu.com")
self.assertEqual(self.dr.name, "chrome")
def test_search_button(self):
self.dr.get("https://www.baidu.com")
self.assertTrue(self.dr.find_element_by_id("su").is_displayed())
def tearDown(self):
self.dr.quit()
if __name__ == '__main__':
unittest.main()
最后: 我给大家整理了完整的软件测试视频学习教程,朋友们如果需要可以自行免费领取 【保证100%免费】

软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
全套资料获取方式:
















 281
281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









